Oracle Plans to Use 30,000 AMD Instinct MI355X GPUs for AI Cloud
AMD's Instinct MI355X accelerators for AI workloads are gaining traction, and Oracle just became one of the bigger customers. According to Oracle's latest financial results, the company noted that it had acquired 30,000 AMD Instinct MI355X accelerators. "In Q3, we signed a multi billion dollar contract with AMD to build a cluster of 30,000 of their latest MI355X GPUs," noted Larry Ellison, adding that "And all four of the leading cloud security companies, CrowdStrike, Cyber Reason, Newfold Digital and Palo Alto, they all decided to move to the Oracle Cloud. But perhaps most importantly, Oracle has developed a new product called the AI data platform that enables our huge install base of database customers to use the latest AI models from OpenAI, XAI and Meta to analyze all of the data they have stored in their millions of existing Oracle databases. By using Oracle version 23 AI's vector capabilities, customers can automatically put all of their existing data into the vector format that is understood by AI models. This allows those AI models to learn, understand and analyze every aspect of your company or government agency, instantly unlocking the value in your data while keeping your data private and secure."
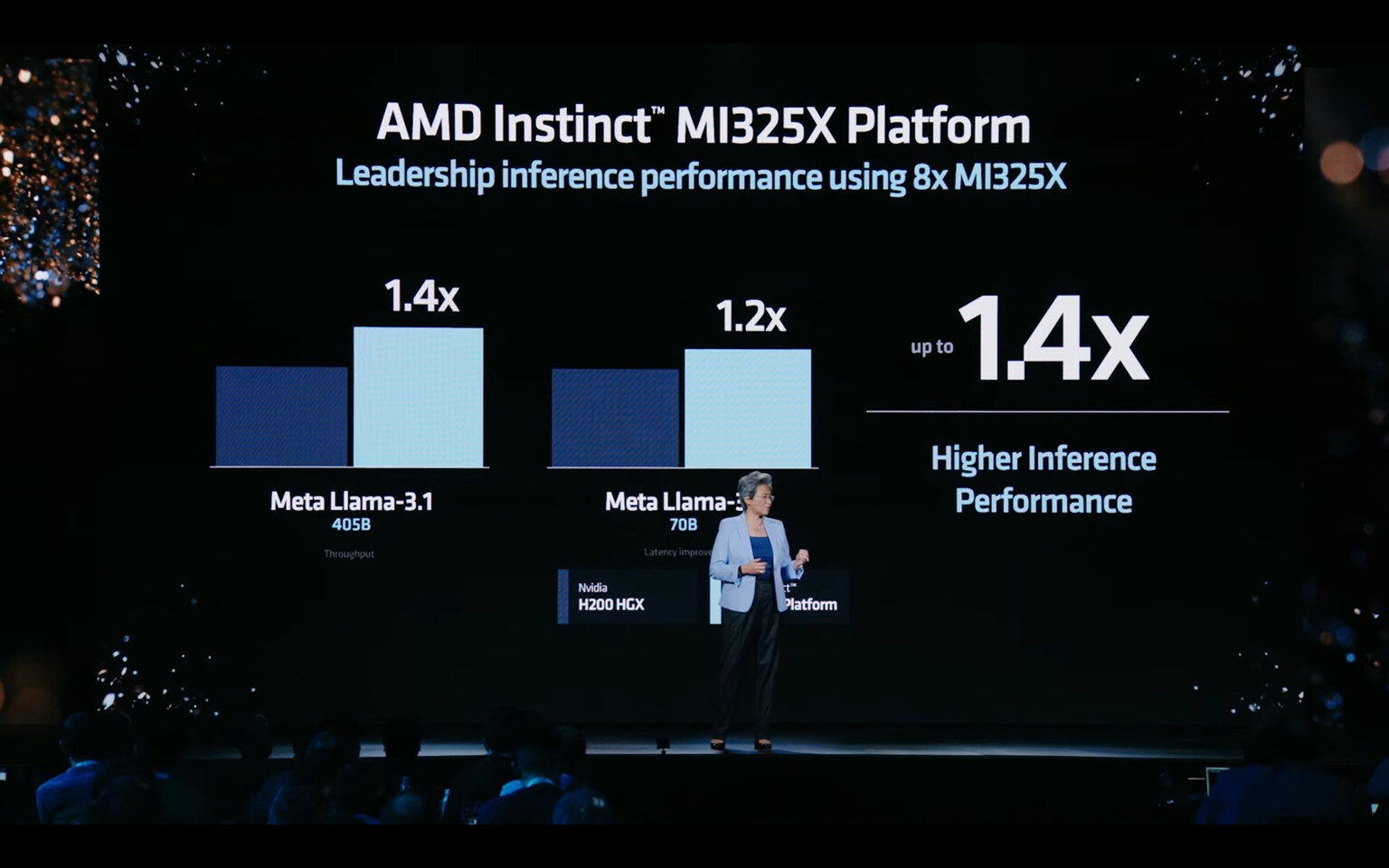
AMD's Instinct MI355X accelerator introduces the CDNA4 architecture on TSMC's N3 process node with a focus on AI workload acceleration. The chiplet-based GPU delivers 2.3 petaflops of FP16 compute and 4.6 petaflops of FP8 compute, marking a 77% performance increase over the MI300X series. The MI355X's key advancement comes through support for reduced-precision FP4 and FP6 numerical formats, enabling up to 9.2 petaflops of FP4 compute. Memory specifications include 288 GB of HBM3E across eight stacks, providing 8 TB/s of total bandwidth. Production timelines place the MI355X's market entry in the second half of 2025, continuing AMD's annual cadence for data center GPU launches. By second half, Oracle will likely prepare data center space for these GPUs and just power them on once AMD ships these accelerators.
AMD's Instinct MI355X accelerator introduces the CDNA4 architecture on TSMC's N3 process node with a focus on AI workload acceleration. The chiplet-based GPU delivers 2.3 petaflops of FP16 compute and 4.6 petaflops of FP8 compute, marking a 77% performance increase over the MI300X series. The MI355X's key advancement comes through support for reduced-precision FP4 and FP6 numerical formats, enabling up to 9.2 petaflops of FP4 compute. Memory specifications include 288 GB of HBM3E across eight stacks, providing 8 TB/s of total bandwidth. Production timelines place the MI355X's market entry in the second half of 2025, continuing AMD's annual cadence for data center GPU launches. By second half, Oracle will likely prepare data center space for these GPUs and just power them on once AMD ships these accelerators.