Thursday, October 10th 2024

AMD Launches Instinct MI325X Accelerator for AI Workloads: 256 GB HBM3E Memory and 2.6 PetaFLOPS FP8 Compute
During its "Advancing AI" conference today, AMD has updated its AI accelerator portfolio with the Instinct MI325X accelerator, designed to succeed its MI300X predecessor. Built on the CDNA 3 architecture, Instinct MI325X brings a suite of improvements over the old SKU. Now, the MI325X features 256 GB of HBM3E memory running at 6 TB/s bandwidth. The capacity memory alone is a 1.8x improvement over the old MI300 SKU, which features 192 GB of regular HBM3 memory. Providing more memory capacity is crucial as upcoming AI workloads are training models with parameter counts measured in trillions, as opposed to billions with current models we have today. When it comes to compute resources, the Instinct MI325X provides 1.3 PetaFLOPS at FP16 and 2.6 PetaFLOPS at FP8 training and inference. This represents a 1.3x improvement over the Instinct MI300.
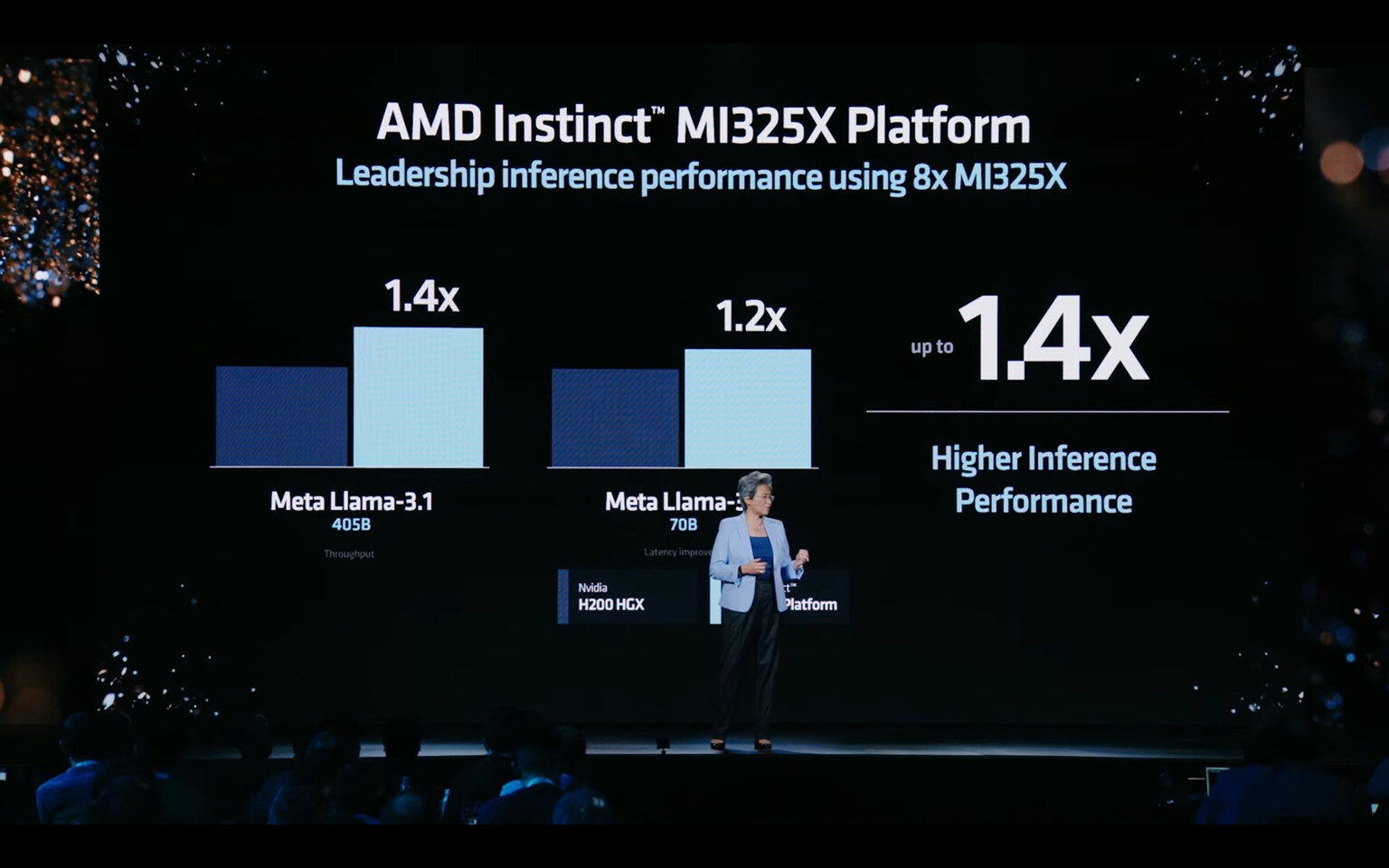
A chip alone is worthless without a good platform, and AMD decided to make the Instinct MI325X OAM modules a drop-in replacement for the current platform designed for MI300X, as they are both pin-compatible. In systems packing eight MI325X accelerators, there are 2 TB of HBM3E memory running at 48 TB/s memory bandwidth. Such a system achieves 10.4 PetaFLOPS of FP16 and 20.8 PetaFLOPS of FP8 compute performance. The company uses NVIDIA's H200 HGX as reference claims for its performance competitiveness, where the company claims that the Instinct MI325X outperforms NVIDIA H200 HGX system by 1.3x across the board in memory bandwidth, FP16 / FP8 compute performance and 1.8x in memory capacity.


 At the core of the accelerator is the ROCm software stack. We recently covered AMD's plan of ROCm coming to every GPU, even consumer models. The company reiterated that point. Another important disclaimer made was working with the open-source community to integrate all the latest features into its ROCm stack, especially from frameworks like PyTorch, Triton, ONNX, etc. AMD also pointed out that the company is preparing Instinct MI350X family for second half of 2025. By then, we should be getting a CDNA 4 Instinct MI355X accelerator built on TSMC 3 nm node, running with 288 GB of HBM3E. The new CDNA 4 architecture brings support for lower-lever data types such as FP4 and FP6. The upcoming chip will yield a massive 2.3 PetaFLOPS of FP16, and 4.6 PetaFLOPS of FP8 compute capability. The new FP4 and FP6 formats will allow a single CDNA 4 Instinct MI355X to reach 9.2 PetaFLOPS of compute capability.
At the core of the accelerator is the ROCm software stack. We recently covered AMD's plan of ROCm coming to every GPU, even consumer models. The company reiterated that point. Another important disclaimer made was working with the open-source community to integrate all the latest features into its ROCm stack, especially from frameworks like PyTorch, Triton, ONNX, etc. AMD also pointed out that the company is preparing Instinct MI350X family for second half of 2025. By then, we should be getting a CDNA 4 Instinct MI355X accelerator built on TSMC 3 nm node, running with 288 GB of HBM3E. The new CDNA 4 architecture brings support for lower-lever data types such as FP4 and FP6. The upcoming chip will yield a massive 2.3 PetaFLOPS of FP16, and 4.6 PetaFLOPS of FP8 compute capability. The new FP4 and FP6 formats will allow a single CDNA 4 Instinct MI355X to reach 9.2 PetaFLOPS of compute capability.
Source:
AMD YouTube
A chip alone is worthless without a good platform, and AMD decided to make the Instinct MI325X OAM modules a drop-in replacement for the current platform designed for MI300X, as they are both pin-compatible. In systems packing eight MI325X accelerators, there are 2 TB of HBM3E memory running at 48 TB/s memory bandwidth. Such a system achieves 10.4 PetaFLOPS of FP16 and 20.8 PetaFLOPS of FP8 compute performance. The company uses NVIDIA's H200 HGX as reference claims for its performance competitiveness, where the company claims that the Instinct MI325X outperforms NVIDIA H200 HGX system by 1.3x across the board in memory bandwidth, FP16 / FP8 compute performance and 1.8x in memory capacity.



13 Comments on AMD Launches Instinct MI325X Accelerator for AI Workloads: 256 GB HBM3E Memory and 2.6 PetaFLOPS FP8 Compute
Also,Lisa faces looks like my Mom- grey hair
The fanbois are already lined up to pay $2500 for a 5090 and even if AMD released a gpu that was faster AND cheaper than the 5090, they will still buy the 5090.
This one at least is honest and upfront about it:
.
Also most people do not buy AMD since their FSR implementation is garbage when compared to DLSS, quality wise.
So in other words, my original post stands.