Apr 10th, 2025 06:05 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Looking for input on fan placement for my Define R5 (4)
- How is the Gainward Phoenix Model in terms of quality? (2)
- Will you buy a RTX 5090? (478)
- Downgrading bios on asrock A320 board (1)
- Star Citizen (2515)
- ## [Golden Sample] RTX 5080 – 3300 MHz @ 1.020 V (Stock Curve) – Ultra-Stable & Efficient (45)
- RX 9000 series GPU Owners Club (276)
- random system shutdown with fans running at full speed (17)
- Shadow of the Tomb Raider benchmark (555)
- Do you use Linux? (573)
Popular Reviews
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- ASRock Z890 Taichi OCF Review
- MCHOSE L7 Pro Review
- Sapphire Radeon RX 9070 XT Pulse Review
- PowerColor Radeon RX 9070 Hellhound Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Acer Predator GM9000 2 TB Review
- ASUS GeForce RTX 5080 Astral OC Review
- UPERFECT UStation Delta Max Review - Two Screens In One
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (174)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (100)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
News Posts matching #PyTorch
Return to Keyword BrowsingLightmatter Unveils Six‑Chip Photonic AI Processor with Incredible Performance/Watt
Lightmatter has launched its latest photonic processor, representing a fundamental shift from traditional computing architectures. The new system integrates six chips into a single 3D packaged module, each containing photonic tensor cores and control dies that work in concert to accelerate AI workloads. Detailed in a recent Nature publication, the processor combines approximately 50 billion transistors with one million photonic components interconnected via high-speed optical links. The industry has faced numerous computing challenges as conventional scaling approaches plateau, with Moore's Law, Dennard scaling, and DRAM capacity doubling, all reaching physical limits per silicon area. Lightmatter's solution implements an adaptive block floating point (ABFP) format with analog gain control to overcome these barriers. During matrix operations, weights and activations are grouped into blocks sharing a single exponent determined by the most significant value, minimizing quantization errors.
The processor achieves 65.5 trillion 16-bit ABFP operations per second (sort of 16-bit TOPs) while consuming just 78 W of electrical power and 1.6 W of optical power. What sets this processor apart is its ability to run unmodified AI models with near FP32 accuracy. The system successfully executes full-scale models, including ResNet for image classification, BERT for natural language processing, and DeepMind's Atari reinforcement learning algorithms without specialized retraining or quantization-aware techniques. This represents the first commercially available photonic AI accelerator capable of running off-the-shelf models without fine-tuning. The processor's architecture fundamentally uses light for computation to address next-generation GPUs' prohibitive costs and energy demands. With native integration for popular AI frameworks like PyTorch and TensorFlow, Lightmatter hopes for immediate adoption in production environments.

The processor achieves 65.5 trillion 16-bit ABFP operations per second (sort of 16-bit TOPs) while consuming just 78 W of electrical power and 1.6 W of optical power. What sets this processor apart is its ability to run unmodified AI models with near FP32 accuracy. The system successfully executes full-scale models, including ResNet for image classification, BERT for natural language processing, and DeepMind's Atari reinforcement learning algorithms without specialized retraining or quantization-aware techniques. This represents the first commercially available photonic AI accelerator capable of running off-the-shelf models without fine-tuning. The processor's architecture fundamentally uses light for computation to address next-generation GPUs' prohibitive costs and energy demands. With native integration for popular AI frameworks like PyTorch and TensorFlow, Lightmatter hopes for immediate adoption in production environments.



Arm and Partners Develop AI CPU: Neoverse V3 CSS Made on 2 nm Samsung GAA FET
Yesterday, Arm has announced significant progress in its Total Design initiative. The program, launched a year ago, aims to accelerate the development of custom silicon for data centers by fostering collaboration among industry partners. The ecosystem has now grown to include nearly 30 participating companies, with recent additions such as Alcor Micro, Egis, PUF Security, and SEMIFIVE. A notable development is a partnership between Arm, Samsung Foundry, ADTechnology, and Rebellions to create an AI CPU chiplet platform. This collaboration aims to deliver a solution for cloud, HPC, and AI/ML workloads, combining Rebellions' AI accelerator with ADTechnology's compute chiplet, implemented using Samsung Foundry's 2 nm Gate-All-Around (GAA) FET technology. The platform is expected to offer significant efficiency gains for generative AI workloads, with estimates suggesting a 2-3x improvement over the standard CPU design for LLMs like Llama3.1 with 405 billion parameters.
Arm's approach emphasizes the importance of CPU compute in supporting the complete AI stack, including data pre-processing, orchestration, and advanced techniques like Retrieval-augmented Generation (RAG). The company's Compute Subsystems (CSS) are designed to address these requirements, providing a foundation for partners to build diverse chiplet solutions. Several companies, including Alcor Micro and Alphawave, have already announced plans to develop CSS-powered chiplets for various AI and high-performance computing applications. The initiative also focuses on software readiness, ensuring that major frameworks and operating systems are compatible with Arm-based systems. Recent efforts include the introduction of Arm Kleidi technology, which optimizes CPU-based inference for open-source projects like PyTorch and Llama.cpp. Notably, as Google claims, most AI workloads are being inferenced on CPUs, so creating the most efficient and most performant CPUs for AI makes a lot of sense.
Arm's approach emphasizes the importance of CPU compute in supporting the complete AI stack, including data pre-processing, orchestration, and advanced techniques like Retrieval-augmented Generation (RAG). The company's Compute Subsystems (CSS) are designed to address these requirements, providing a foundation for partners to build diverse chiplet solutions. Several companies, including Alcor Micro and Alphawave, have already announced plans to develop CSS-powered chiplets for various AI and high-performance computing applications. The initiative also focuses on software readiness, ensuring that major frameworks and operating systems are compatible with Arm-based systems. Recent efforts include the introduction of Arm Kleidi technology, which optimizes CPU-based inference for open-source projects like PyTorch and Llama.cpp. Notably, as Google claims, most AI workloads are being inferenced on CPUs, so creating the most efficient and most performant CPUs for AI makes a lot of sense.


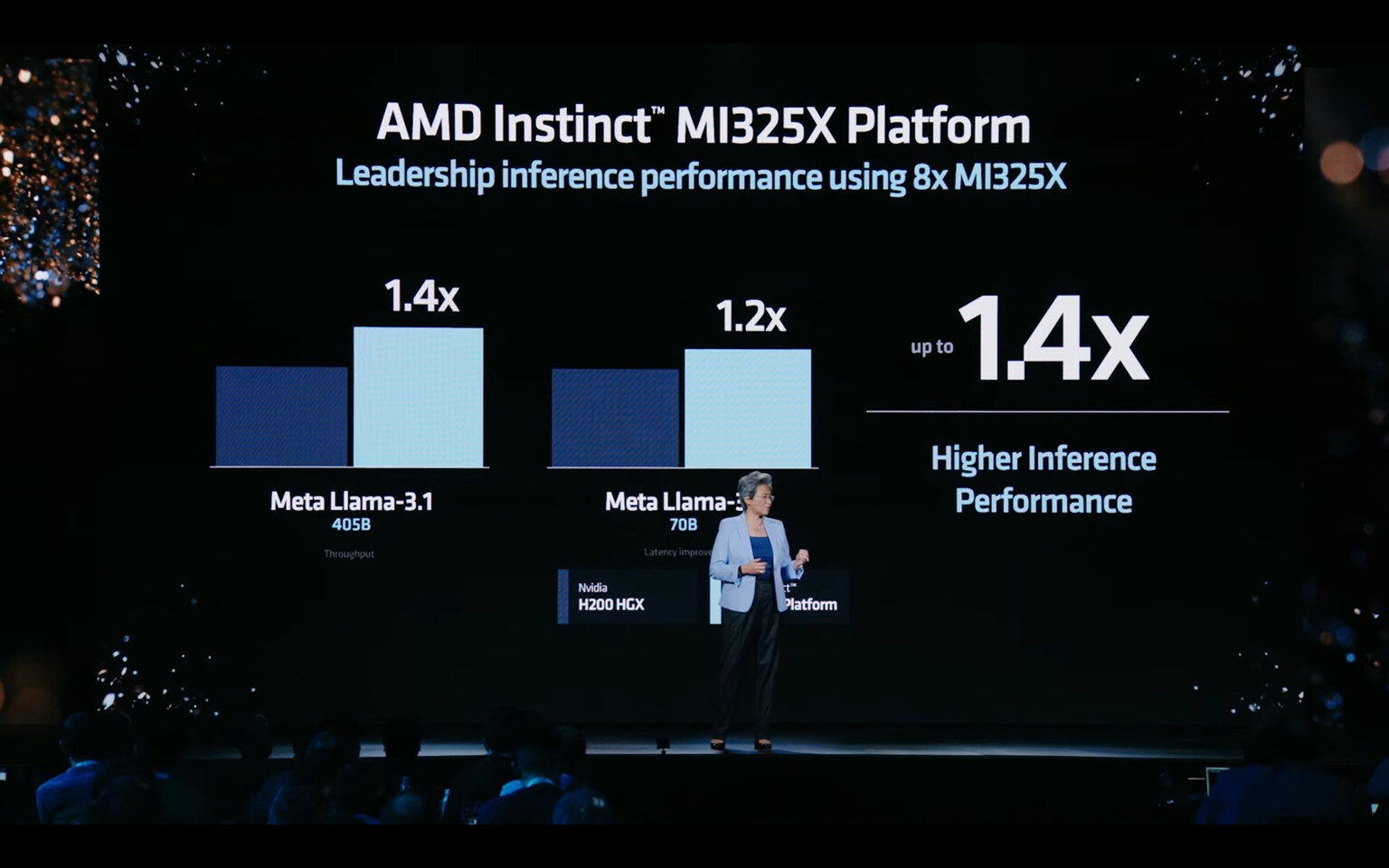
AMD Launches Instinct MI325X Accelerator for AI Workloads: 256 GB HBM3E Memory and 2.6 PetaFLOPS FP8 Compute
During its "Advancing AI" conference today, AMD has updated its AI accelerator portfolio with the Instinct MI325X accelerator, designed to succeed its MI300X predecessor. Built on the CDNA 3 architecture, Instinct MI325X brings a suite of improvements over the old SKU. Now, the MI325X features 256 GB of HBM3E memory running at 6 TB/s bandwidth. The capacity memory alone is a 1.8x improvement over the old MI300 SKU, which features 192 GB of regular HBM3 memory. Providing more memory capacity is crucial as upcoming AI workloads are training models with parameter counts measured in trillions, as opposed to billions with current models we have today. When it comes to compute resources, the Instinct MI325X provides 1.3 PetaFLOPS at FP16 and 2.6 PetaFLOPS at FP8 training and inference. This represents a 1.3x improvement over the Instinct MI300.
A chip alone is worthless without a good platform, and AMD decided to make the Instinct MI325X OAM modules a drop-in replacement for the current platform designed for MI300X, as they are both pin-compatible. In systems packing eight MI325X accelerators, there are 2 TB of HBM3E memory running at 48 TB/s memory bandwidth. Such a system achieves 10.4 PetaFLOPS of FP16 and 20.8 PetaFLOPS of FP8 compute performance. The company uses NVIDIA's H200 HGX as reference claims for its performance competitiveness, where the company claims that the Instinct MI325X outperforms NVIDIA H200 HGX system by 1.3x across the board in memory bandwidth, FP16 / FP8 compute performance and 1.8x in memory capacity.



A chip alone is worthless without a good platform, and AMD decided to make the Instinct MI325X OAM modules a drop-in replacement for the current platform designed for MI300X, as they are both pin-compatible. In systems packing eight MI325X accelerators, there are 2 TB of HBM3E memory running at 48 TB/s memory bandwidth. Such a system achieves 10.4 PetaFLOPS of FP16 and 20.8 PetaFLOPS of FP8 compute performance. The company uses NVIDIA's H200 HGX as reference claims for its performance competitiveness, where the company claims that the Instinct MI325X outperforms NVIDIA H200 HGX system by 1.3x across the board in memory bandwidth, FP16 / FP8 compute performance and 1.8x in memory capacity.




Microsoft Unveils New Details on Maia 100, Its First Custom AI Chip
Microsoft provided a detailed view of Maia 100 at Hot Chips 2024, their initial specialized AI chip. This new system is designed to work seamlessly from start to finish, with the goal of improving performance and reducing expenses. It includes specially made server boards, unique racks, and a software system focused on increasing the effectiveness and strength of sophisticated AI services, such as Azure OpenAI. Microsoft introduced Maia at Ignite 2023, sharing that they had created their own AI accelerator chip. More information was provided earlier this year at the Build developer event. The Maia 100 is one of the biggest processors made using TSMC's 5 nm technology, designed for handling extensive AI tasks on Azure platform.
Maia 100 SoC architecture features:



Maia 100 SoC architecture features:
- A high-speed tensor unit (16xRx16) offers rapid processing for training and inferencing while supporting a wide range of data types, including low precision data types such as the MX data format, first introduced by Microsoft through the MX Consortium in 2023.
- The vector processor is a loosely coupled superscalar engine built with custom instruction set architecture (ISA) to support a wide range of data types, including FP32 and BF16.
- A Direct Memory Access (DMA) engine supports different tensor sharding schemes.
- Hardware semaphores enable asynchronous programming on the Maia system.





Intel AI Platforms Accelerate Microsoft Phi-3 GenAI Models
Intel has validated and optimized its AI product portfolio across client, edge and data center for several of Microsoft's Phi-3 family of open models. The Phi-3 family of small, open models can run on lower-compute hardware, be more easily fine-tuned to meet specific requirements and enable developers to build applications that run locally. Intel's supported products include Intel Gaudi AI accelerators and Intel Xeon processors for data center applications and Intel Core Ultra processors and Intel Arc graphics for client.
"We provide customers and developers with powerful AI solutions that utilize the industry's latest AI models and software. Our active collaboration with fellow leaders in the AI software ecosystem, like Microsoft, is key to bringing AI everywhere. We're proud to work closely with Microsoft to ensure Intel hardware - spanning data center, edge and client - actively supports several new Phi-3 models," said Pallavi Mahajan, Intel corporate vice president and general manager, Data Center and AI Software.
"We provide customers and developers with powerful AI solutions that utilize the industry's latest AI models and software. Our active collaboration with fellow leaders in the AI software ecosystem, like Microsoft, is key to bringing AI everywhere. We're proud to work closely with Microsoft to ensure Intel hardware - spanning data center, edge and client - actively supports several new Phi-3 models," said Pallavi Mahajan, Intel corporate vice president and general manager, Data Center and AI Software.


New Performance Optimizations Supercharge NVIDIA RTX AI PCs for Gamers, Creators and Developers
NVIDIA today announced at Microsoft Build new AI performance optimizations and integrations for Windows that help deliver maximum performance on NVIDIA GeForce RTX AI PCs and NVIDIA RTX workstations. Large language models (LLMs) power some of the most exciting new use cases in generative AI and now run up to 3x faster with ONNX Runtime (ORT) and DirectML using the new NVIDIA R555 Game Ready Driver. ORT and DirectML are high-performance tools used to run AI models locally on Windows PCs.
WebNN, an application programming interface for web developers to deploy AI models, is now accelerated with RTX via DirectML, enabling web apps to incorporate fast, AI-powered capabilities. And PyTorch will support DirectML execution backends, enabling Windows developers to train and infer complex AI models on Windows natively. NVIDIA and Microsoft are collaborating to scale performance on RTX GPUs. These advancements build on NVIDIA's world-leading AI platform, which accelerates more than 500 applications and games on over 100 million RTX AI PCs and workstations worldwide.
WebNN, an application programming interface for web developers to deploy AI models, is now accelerated with RTX via DirectML, enabling web apps to incorporate fast, AI-powered capabilities. And PyTorch will support DirectML execution backends, enabling Windows developers to train and infer complex AI models on Windows natively. NVIDIA and Microsoft are collaborating to scale performance on RTX GPUs. These advancements build on NVIDIA's world-leading AI platform, which accelerates more than 500 applications and games on over 100 million RTX AI PCs and workstations worldwide.

More than 500 AI Models Run Optimized on Intel Core Ultra Processors
Today, Intel announced it surpassed 500 AI models running optimized on new Intel Core Ultra processors - the industry's premier AI PC processor available in the market today, featuring new AI experiences, immersive graphics and optimal battery life. This significant milestone is a result of Intel's investment in client AI, the AI PC transformation, framework optimizations and AI tools including OpenVINO toolkit. The 500 models, which can be deployed across the central processing unit (CPU), graphics processing unit (GPU) and neural processing unit (NPU), are available across popular industry sources, including OpenVINO Model Zoo, Hugging Face, ONNX Model Zoo and PyTorch. The models draw from categories of local AI inferencing, including large language, diffusion, super resolution, object detection, image classification/segmentation, computer vision and others.
"Intel has a rich history of working with the ecosystem to bring AI applications to client devices, and today we celebrate another strong chapter in the heritage of client AI by surpassing 500 pre-trained AI models running optimized on Intel Core Ultra processors. This unmatched selection reflects our commitment to building not only the PC industry's most robust toolchain for AI developers, but a rock-solid foundation AI software users can implicitly trust."
-Robert Hallock, Intel vice president and general manager of AI and technical marketing in the Client Computing Group
"Intel has a rich history of working with the ecosystem to bring AI applications to client devices, and today we celebrate another strong chapter in the heritage of client AI by surpassing 500 pre-trained AI models running optimized on Intel Core Ultra processors. This unmatched selection reflects our commitment to building not only the PC industry's most robust toolchain for AI developers, but a rock-solid foundation AI software users can implicitly trust."
-Robert Hallock, Intel vice president and general manager of AI and technical marketing in the Client Computing Group

Meta Announces New MTIA AI Accelerator with Improved Performance to Ease NVIDIA's Grip
Meta has announced the next generation of its Meta Training and Inference Accelerator (MTIA) chip, which is designed to train and infer AI models at scale. The newest MTIA chip is a second-generation design of Meta's custom silicon for AI, and it is being built on TSMC's 5 nm technology. Running at the frequency of 1.35 GHz, the new chip is getting a boost to 90 Watts of TDP per package compared to just 25 Watts for the first-generation design. Basic Linear Algebra Subprograms (BLAS) processing is where the chip shines, and it includes matrix multiplication and vector/SIMD processing. At GEMM matrix processing, each chip can process 708 TeraFLOPS at INT8 (presumably meant FP8 in the spec) with sparsity, 354 TeraFLOPS without, 354 TeraFLOPS at FP16/BF16 with sparsity, and 177 TeraFLOPS without.
Classical vector and processing is a bit slower at 11.06 TeraFLOPS at INT8 (FP8), 5.53 TeraFLOPS at FP16/BF16, and 2.76 TFLOPS single-precision FP32. The MTIA chip is specifically designed to run AI training and inference on Meta's PyTorch AI framework, with an open-source Triton backend that produces compiler code for optimal performance. Meta uses this for all its Llama models, and with Llama3 just around the corner, it could be trained on these chips. To package it into a system, Meta puts two of these chips onto a board and pairs them with 128 GB of LPDDR5 memory. The board is connected via PCIe Gen 5 to a system where 12 boards are stacked densely. This process is repeated six times in a single rack for 72 boards and 144 chips in a single rack for a total of 101.95 PetaFLOPS, assuming linear scaling at INT8 (FP8) precision. Of course, linear scaling is not quite possible in scale-out systems, which could bring it down to under 100 PetaFLOPS per rack.

 Below, you can see images of the chip floorplan, specifications compared to the prior version, as well as the system.
Below, you can see images of the chip floorplan, specifications compared to the prior version, as well as the system.
Classical vector and processing is a bit slower at 11.06 TeraFLOPS at INT8 (FP8), 5.53 TeraFLOPS at FP16/BF16, and 2.76 TFLOPS single-precision FP32. The MTIA chip is specifically designed to run AI training and inference on Meta's PyTorch AI framework, with an open-source Triton backend that produces compiler code for optimal performance. Meta uses this for all its Llama models, and with Llama3 just around the corner, it could be trained on these chips. To package it into a system, Meta puts two of these chips onto a board and pairs them with 128 GB of LPDDR5 memory. The board is connected via PCIe Gen 5 to a system where 12 boards are stacked densely. This process is repeated six times in a single rack for 72 boards and 144 chips in a single rack for a total of 101.95 PetaFLOPS, assuming linear scaling at INT8 (FP8) precision. Of course, linear scaling is not quite possible in scale-out systems, which could bring it down to under 100 PetaFLOPS per rack.



Cerebras Systems Unveils World's Fastest AI Chip with 4 Trillion Transistors and 900,000 AI cores
Cerebras Systems, the pioneer in accelerating generative AI, has doubled down on its existing world record of fastest AI chip with the introduction of the Wafer Scale Engine 3. The WSE-3 delivers twice the performance of the previous record-holder, the Cerebras WSE-2, at the same power draw and for the same price. Purpose built for training the industry's largest AI models, the 5 nm-based, 4 trillion transistor WSE-3 powers the Cerebras CS-3 AI supercomputer, delivering 125 petaflops of peak AI performance through 900,000 AI optimized compute cores.

Intel Gaudi2 Accelerator Beats NVIDIA H100 at Stable Diffusion 3 by 55%
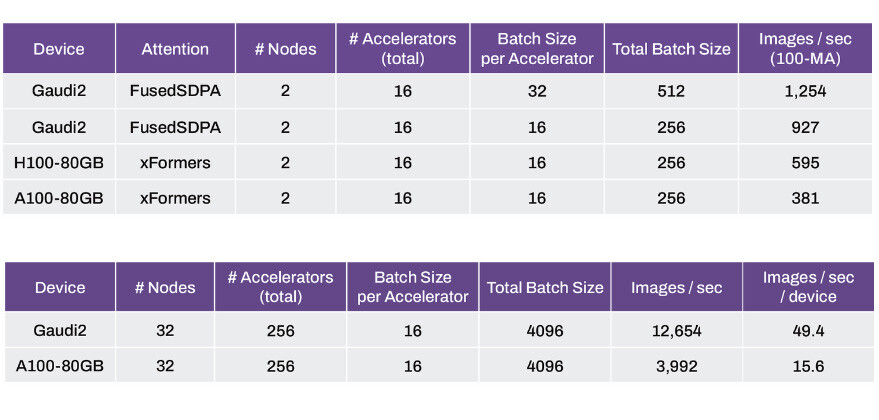
Stability AI, the developers behind the popular Stable Diffusion generative AI model, have run some first-party performance benchmarks for Stable Diffusion 3 using popular data-center AI GPUs, including the NVIDIA H100 "Hopper" 80 GB, A100 "Ampere" 80 GB, and Intel's Gaudi2 96 GB accelerator. Unlike the H100, which is a super-scalar CUDA+Tensor core GPU; the Gaudi2 is purpose-built to accelerate generative AI and LLMs. Stability AI published its performance findings in a blog post, which reveals that the Intel Gaudi2 96 GB is posting a roughly 56% higher performance than the H100 80 GB.
With 2 nodes, 16 accelerators, and a constant batch size of 16 per accelerator (256 in all), the Intel Gaudi2 array is able to generate 927 images per second, compared to 595 images for the H100 array, and 381 images per second for the A100 array, keeping accelerator and node counts constant. Scaling things up a notch to 32 nodes, and 256 accelerators or a batch size of 16 per accelerator (total batch size of 4,096), the Gaudi2 array is posting 12,654 images per second; or 49.4 images per-second per-device; compared to 3,992 images per second or 15.6 images per-second per-device for the older-gen A100 "Ampere" array.

With 2 nodes, 16 accelerators, and a constant batch size of 16 per accelerator (256 in all), the Intel Gaudi2 array is able to generate 927 images per second, compared to 595 images for the H100 array, and 381 images per second for the A100 array, keeping accelerator and node counts constant. Scaling things up a notch to 32 nodes, and 256 accelerators or a batch size of 16 per accelerator (total batch size of 4,096), the Gaudi2 array is posting 12,654 images per second; or 49.4 images per-second per-device; compared to 3,992 images per second or 15.6 images per-second per-device for the older-gen A100 "Ampere" array.


Intel Optimizes PyTorch for Llama 2 on Arc A770, Higher Precision FP16
Intel just announced optimizations for PyTorch (IPEX) to take advantage of the AI acceleration features of its Arc "Alchemist" GPUs.PyTorch is a popular machine learning library that is often associated with NVIDIA GPUs, but it is actually platform-agnostic. It can be run on a variety of hardware, including CPUs and GPUs. However, performance may not be optimal without specific optimizations. Intel offers such optimizations through the Intel Extension for PyTorch (IPEX), which extends PyTorch with optimizations specifically designed for Intel's compute hardware.
Intel released a blog post detailing how to run Meta AI's Llama 2 large language model on its Arc "Alchemist" A770 graphics card. The model requires 14 GB of GPU RAM, so a 16 GB version of the A770 is recommended. This development could be seen as a direct response to NVIDIA's Chat with RTX tool, which allows GeForce users with >8 GB RTX 30-series "Ampere" and RTX 40-series "Ada" GPUs to run PyTorch-LLM models on their graphics cards. NVIDIA achieves lower VRAM usage by distributing INT4-quantized versions of the models, while Intel uses a higher-precision FP16 version. In theory, this should not have a significant impact on the results. This blog post by Intel provides instructions on how to set up Llama 2 inference with PyTorch (IPEX) on the A770.
Intel released a blog post detailing how to run Meta AI's Llama 2 large language model on its Arc "Alchemist" A770 graphics card. The model requires 14 GB of GPU RAM, so a 16 GB version of the A770 is recommended. This development could be seen as a direct response to NVIDIA's Chat with RTX tool, which allows GeForce users with >8 GB RTX 30-series "Ampere" and RTX 40-series "Ada" GPUs to run PyTorch-LLM models on their graphics cards. NVIDIA achieves lower VRAM usage by distributing INT4-quantized versions of the models, while Intel uses a higher-precision FP16 version. In theory, this should not have a significant impact on the results. This blog post by Intel provides instructions on how to set up Llama 2 inference with PyTorch (IPEX) on the A770.


AMD ROCm 6.0 Adds Support for Radeon PRO W7800 & RX 7900 GRE GPUs
Building on our previously announced support of the AMD Radeon RX 7900 XT, XTX and Radeon PRO W7900 GPUs with AMD ROCm 5.7 and PyTorch, we are now expanding our client-based ML Development offering, both from the hardware and software side with AMD ROCm 6.0. Firstly, AI researchers and ML engineers can now also develop on Radeon PRO W7800 and on Radeon RX 7900 GRE GPUs. With support for such a broad product portfolio, AMD is helping the AI community to get access to desktop graphics cards at even more price points and at different performance levels.
Furthermore, we are complementing our solution stack with support for ONNX Runtime. ONNX, short for Open Neural Network Exchange, is an intermediary Machine Learning framework used to convert AI models between different ML frameworks. As a result, users can now perform inference on a wider range of source data on local AMD hardware. This also adds INT8 via MIGraphX—AMD's own graph inference engine—to the available data types (including FP32 and FP16). With AMD ROCm 6.0, we are continuing our support for the PyTorch framework bringing mixed precision with FP32/FP16 to Machine Learning training workflows.

Furthermore, we are complementing our solution stack with support for ONNX Runtime. ONNX, short for Open Neural Network Exchange, is an intermediary Machine Learning framework used to convert AI models between different ML frameworks. As a result, users can now perform inference on a wider range of source data on local AMD hardware. This also adds INT8 via MIGraphX—AMD's own graph inference engine—to the available data types (including FP32 and FP16). With AMD ROCm 6.0, we are continuing our support for the PyTorch framework bringing mixed precision with FP32/FP16 to Machine Learning training workflows.


Intel Accelerates AI Everywhere with Launch of Powerful Next-Gen Products
At its "AI Everywhere" launch in New York City today, Intel introduced an unmatched portfolio of AI products to enable customers' AI solutions everywhere—across the data center, cloud, network, edge and PC. "AI innovation is poised to raise the digital economy's impact up to as much as one-third of global gross domestic product," Gelsinger said. "Intel is developing the technologies and solutions that empower customers to seamlessly integrate and effectively run AI in all their applications—in the cloud and, increasingly, locally at the PC and edge, where data is generated and used."
Gelsinger showcased Intel's expansive AI footprint, spanning cloud and enterprise servers to networks, volume clients and ubiquitous edge environments. He also reinforced that Intel is on track to deliver five new process technology nodes in four years. "Intel is on a mission to bring AI everywhere through exceptionally engineered platforms, secure solutions and support for open ecosystems. Our AI portfolio gets even stronger with today's launch of Intel Core Ultra ushering in the age of the AI PC and AI-accelerated 5th Gen Xeon for the enterprise," Gelsinger said.




Gelsinger showcased Intel's expansive AI footprint, spanning cloud and enterprise servers to networks, volume clients and ubiquitous edge environments. He also reinforced that Intel is on track to deliver five new process technology nodes in four years. "Intel is on a mission to bring AI everywhere through exceptionally engineered platforms, secure solutions and support for open ecosystems. Our AI portfolio gets even stronger with today's launch of Intel Core Ultra ushering in the age of the AI PC and AI-accelerated 5th Gen Xeon for the enterprise," Gelsinger said.





AMD Unveils Alveo UL3524 Purpose-Built, FPGA-Based Accelerator
AMD today announced the AMD Alveo UL3524 accelerator card, a new fintech accelerator designed for ultra-low latency electronic trading applications. Already deployed by leading trading firms and enabling multiple solution partner offerings, the Alveo UL3524 provides proprietary traders, market makers, hedge funds, brokerages, and exchanges with a state-of-the-art FPGA platform for electronic trading at nanosecond (ns) speed.
The Alveo UL3524 delivers a 7X latency improvement over prior generation FPGA technology, achieving less than 3ns FPGA transceiver latency for accelerated trade execution. Powered by a custom 16 nm Virtex UltraScale + FPGA, it features a novel transceiver architecture with hardened, optimized network connectivity cores to achieve breakthrough performance. By combining hardware flexibility with ultra-low latency networking on a production platform, the Alveo UL3524 enables faster design closure and deployment compared to traditional FPGA alternatives.
The Alveo UL3524 delivers a 7X latency improvement over prior generation FPGA technology, achieving less than 3ns FPGA transceiver latency for accelerated trade execution. Powered by a custom 16 nm Virtex UltraScale + FPGA, it features a novel transceiver architecture with hardened, optimized network connectivity cores to achieve breakthrough performance. By combining hardware flexibility with ultra-low latency networking on a production platform, the Alveo UL3524 enables faster design closure and deployment compared to traditional FPGA alternatives.


Google Introduces Cloud TPU v5e and Announces A3 Instance Availability
We're at a once-in-a-generation inflection point in computing. The traditional ways of designing and building computing infrastructure are no longer adequate for the exponentially growing demands of workloads like generative AI and LLMs. In fact, the number of parameters in LLMs has increased by 10x per year over the past five years. As a result, customers need AI-optimized infrastructure that is both cost effective and scalable.
For two decades, Google has built some of the industry's leading AI capabilities: from the creation of Google's Transformer architecture that makes gen AI possible, to our AI-optimized infrastructure, which is built to deliver the global scale and performance required by Google products that serve billions of users like YouTube, Gmail, Google Maps, Google Play, and Android. We are excited to bring decades of innovation and research to Google Cloud customers as they pursue transformative opportunities in AI. We offer a complete solution for AI, from computing infrastructure optimized for AI to the end-to-end software and services that support the full lifecycle of model training, tuning, and serving at global scale.
For two decades, Google has built some of the industry's leading AI capabilities: from the creation of Google's Transformer architecture that makes gen AI possible, to our AI-optimized infrastructure, which is built to deliver the global scale and performance required by Google products that serve billions of users like YouTube, Gmail, Google Maps, Google Play, and Android. We are excited to bring decades of innovation and research to Google Cloud customers as they pursue transformative opportunities in AI. We offer a complete solution for AI, from computing infrastructure optimized for AI to the end-to-end software and services that support the full lifecycle of model training, tuning, and serving at global scale.

MLCommons Shares Intel Habana Gaudi2 and 4th Gen Intel Xeon Scalable AI Benchmark Results
Today, MLCommons published results of its industry AI performance benchmark, MLPerf Training 3.0, in which both the Habana Gaudi2 deep learning accelerator and the 4th Gen Intel Xeon Scalable processor delivered impressive training results.
"The latest MLPerf results published by MLCommons validates the TCO value Intel Xeon processors and Intel Gaudi deep learning accelerators provide to customers in the area of AI. Xeon's built-in accelerators make it an ideal solution to run volume AI workloads on general-purpose processors, while Gaudi delivers competitive performance for large language models and generative AI. Intel's scalable systems with optimized, easy-to-program open software lowers the barrier for customers and partners to deploy a broad array of AI-based solutions in the data center from the cloud to the intelligent edge." - Sandra Rivera, Intel executive vice president and general manager of the Data Center and AI Group

"The latest MLPerf results published by MLCommons validates the TCO value Intel Xeon processors and Intel Gaudi deep learning accelerators provide to customers in the area of AI. Xeon's built-in accelerators make it an ideal solution to run volume AI workloads on general-purpose processors, while Gaudi delivers competitive performance for large language models and generative AI. Intel's scalable systems with optimized, easy-to-program open software lowers the barrier for customers and partners to deploy a broad array of AI-based solutions in the data center from the cloud to the intelligent edge." - Sandra Rivera, Intel executive vice president and general manager of the Data Center and AI Group


AMD Details New EPYC CPUs, Next-Generation AMD Instinct Accelerator, and Networking Portfolio for Cloud and Enterprise
Today, at the "Data Center and AI Technology Premiere," AMD announced the products, strategy and ecosystem partners that will shape the future of computing, highlighting the next phase of data center innovation. AMD was joined on stage with executives from Amazon Web Services (AWS), Citadel, Hugging Face, Meta, Microsoft Azure and PyTorch to showcase the technological partnerships with industry leaders to bring the next generation of high performance CPU and AI accelerator solutions to market.
"Today, we took another significant step forward in our data center strategy as we expanded our 4th Gen EPYC processor family with new leadership solutions for cloud and technical computing workloads and announced new public instances and internal deployments with the largest cloud providers," said AMD Chair and CEO Dr. Lisa Su. "AI is the defining technology shaping the next generation of computing and the largest strategic growth opportunity for AMD. We are laser focused on accelerating the deployment of AMD AI platforms at scale in the data center, led by the launch of our Instinct MI300 accelerators planned for later this year and the growing ecosystem of enterprise-ready AI software optimized for our hardware."


"Today, we took another significant step forward in our data center strategy as we expanded our 4th Gen EPYC processor family with new leadership solutions for cloud and technical computing workloads and announced new public instances and internal deployments with the largest cloud providers," said AMD Chair and CEO Dr. Lisa Su. "AI is the defining technology shaping the next generation of computing and the largest strategic growth opportunity for AMD. We are laser focused on accelerating the deployment of AMD AI platforms at scale in the data center, led by the launch of our Instinct MI300 accelerators planned for later this year and the growing ecosystem of enterprise-ready AI software optimized for our hardware."



NVIDIA Announces Microsoft, Tencent, Baidu Adopting CV-CUDA for Computer Vision AI
Microsoft, Tencent and Baidu are adopting NVIDIA CV-CUDA for computer vision AI. NVIDIA CEO Jensen Huang highlighted work in content understanding, visual search and deep learning Tuesday as he announced the beta release for NVIDIA's CV-CUDA—an open-source, GPU-accelerated library for computer vision at cloud scale. "Eighty percent of internet traffic is video, user-generated video content is driving significant growth and consuming massive amounts of power," said Huang in his keynote at NVIDIA's GTC technology conference. "We should accelerate all video processing and reclaim the power."
CV-CUDA promises to help companies across the world build and scale end-to-end, AI-based computer vision and image processing pipelines on GPUs. The majority of internet traffic is video and image data, driving incredible scale in applications such as content creation, visual search and recommendation, and mapping. These applications use a specialized, recurring set of computer vision and image-processing algorithms to process image and video data before and after they're processed by neural networks.
CV-CUDA promises to help companies across the world build and scale end-to-end, AI-based computer vision and image processing pipelines on GPUs. The majority of internet traffic is video and image data, driving incredible scale in applications such as content creation, visual search and recommendation, and mapping. These applications use a specialized, recurring set of computer vision and image-processing algorithms to process image and video data before and after they're processed by neural networks.

Intel Contributes AI Acceleration to PyTorch 2.0
In the release of Python 2.0, contributions from Intel using Intel Extension for PyTorch, oneAPI Deep Neural Network Library (oneDNN) and additional support for Intel CPUs enable developers to optimize inference and training performance for artificial intelligence (AI).
As part of the PyTorch 2.0 compilation stack, the TorchInductor CPU backend optimization by Intel Extension for PyTorch and PyTorch ATen CPU achieved up to 1.7 times faster FP32 inference performance when benchmarked with TorchBench, HuggingFace and timm. This update brings notable performance improvements to graph compilation over the PyTorch eager mode.
As part of the PyTorch 2.0 compilation stack, the TorchInductor CPU backend optimization by Intel Extension for PyTorch and PyTorch ATen CPU achieved up to 1.7 times faster FP32 inference performance when benchmarked with TorchBench, HuggingFace and timm. This update brings notable performance improvements to graph compilation over the PyTorch eager mode.

Apr 10th, 2025 06:05 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Looking for input on fan placement for my Define R5 (4)
- How is the Gainward Phoenix Model in terms of quality? (2)
- Will you buy a RTX 5090? (478)
- Downgrading bios on asrock A320 board (1)
- Star Citizen (2515)
- ## [Golden Sample] RTX 5080 – 3300 MHz @ 1.020 V (Stock Curve) – Ultra-Stable & Efficient (45)
- RX 9000 series GPU Owners Club (276)
- random system shutdown with fans running at full speed (17)
- Shadow of the Tomb Raider benchmark (555)
- Do you use Linux? (573)
Popular Reviews
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- ASRock Z890 Taichi OCF Review
- MCHOSE L7 Pro Review
- Sapphire Radeon RX 9070 XT Pulse Review
- PowerColor Radeon RX 9070 Hellhound Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Acer Predator GM9000 2 TB Review
- ASUS GeForce RTX 5080 Astral OC Review
- UPERFECT UStation Delta Max Review - Two Screens In One
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (174)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (100)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)