Thursday, April 11th 2024
Meta Announces New MTIA AI Accelerator with Improved Performance to Ease NVIDIA's Grip
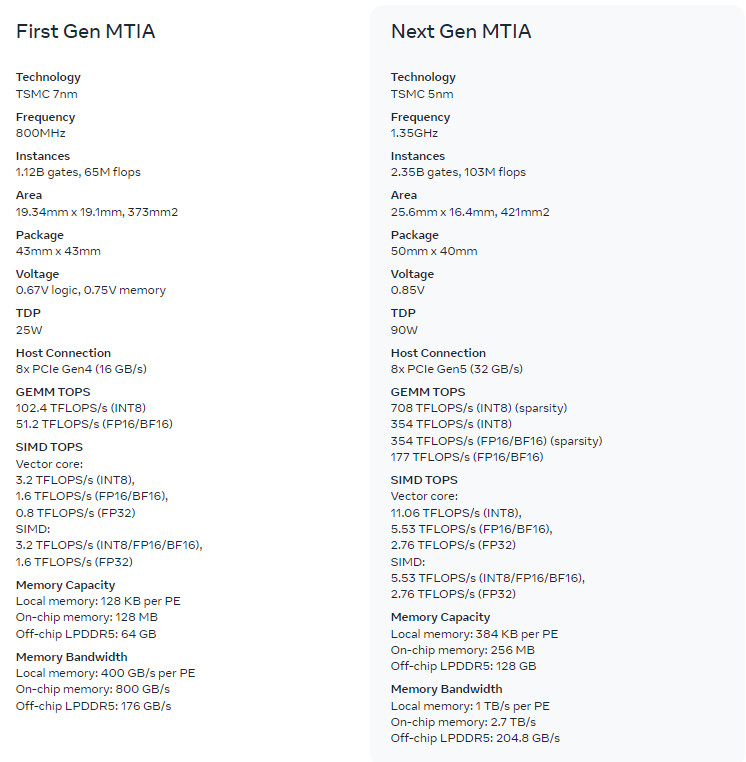
Meta has announced the next generation of its Meta Training and Inference Accelerator (MTIA) chip, which is designed to train and infer AI models at scale. The newest MTIA chip is a second-generation design of Meta's custom silicon for AI, and it is being built on TSMC's 5 nm technology. Running at the frequency of 1.35 GHz, the new chip is getting a boost to 90 Watts of TDP per package compared to just 25 Watts for the first-generation design. Basic Linear Algebra Subprograms (BLAS) processing is where the chip shines, and it includes matrix multiplication and vector/SIMD processing. At GEMM matrix processing, each chip can process 708 TeraFLOPS at INT8 (presumably meant FP8 in the spec) with sparsity, 354 TeraFLOPS without, 354 TeraFLOPS at FP16/BF16 with sparsity, and 177 TeraFLOPS without.
Classical vector and processing is a bit slower at 11.06 TeraFLOPS at INT8 (FP8), 5.53 TeraFLOPS at FP16/BF16, and 2.76 TFLOPS single-precision FP32. The MTIA chip is specifically designed to run AI training and inference on Meta's PyTorch AI framework, with an open-source Triton backend that produces compiler code for optimal performance. Meta uses this for all its Llama models, and with Llama3 just around the corner, it could be trained on these chips. To package it into a system, Meta puts two of these chips onto a board and pairs them with 128 GB of LPDDR5 memory. The board is connected via PCIe Gen 5 to a system where 12 boards are stacked densely. This process is repeated six times in a single rack for 72 boards and 144 chips in a single rack for a total of 101.95 PetaFLOPS, assuming linear scaling at INT8 (FP8) precision. Of course, linear scaling is not quite possible in scale-out systems, which could bring it down to under 100 PetaFLOPS per rack.

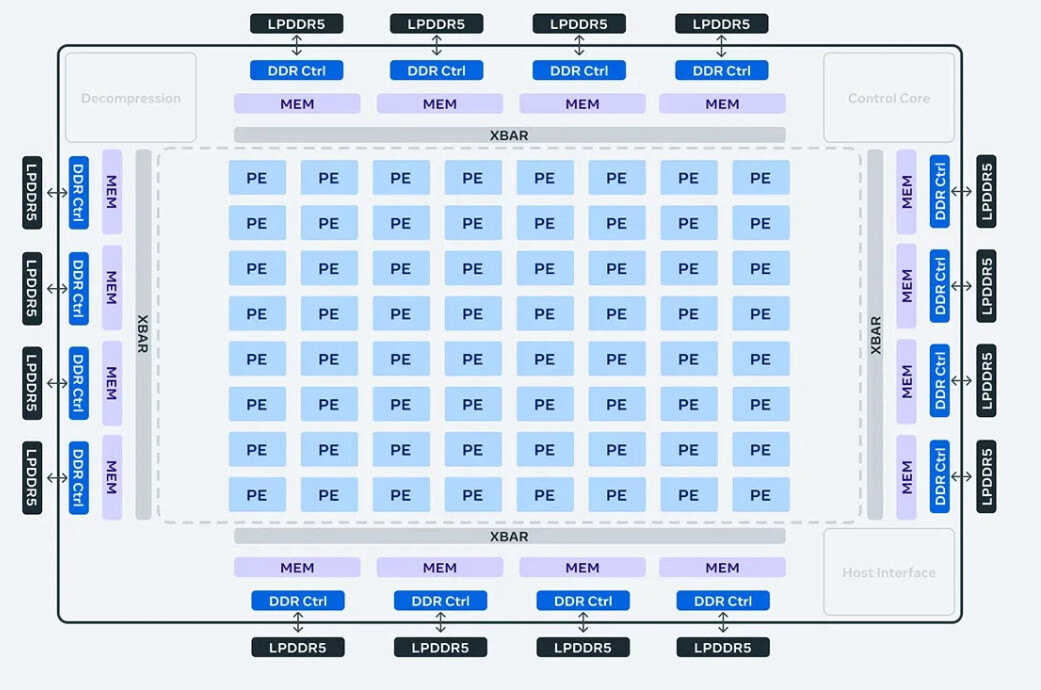
 Below, you can see images of the chip floorplan, specifications compared to the prior version, as well as the system.
Below, you can see images of the chip floorplan, specifications compared to the prior version, as well as the system.




Source:
Meta
Classical vector and processing is a bit slower at 11.06 TeraFLOPS at INT8 (FP8), 5.53 TeraFLOPS at FP16/BF16, and 2.76 TFLOPS single-precision FP32. The MTIA chip is specifically designed to run AI training and inference on Meta's PyTorch AI framework, with an open-source Triton backend that produces compiler code for optimal performance. Meta uses this for all its Llama models, and with Llama3 just around the corner, it could be trained on these chips. To package it into a system, Meta puts two of these chips onto a board and pairs them with 128 GB of LPDDR5 memory. The board is connected via PCIe Gen 5 to a system where 12 boards are stacked densely. This process is repeated six times in a single rack for 72 boards and 144 chips in a single rack for a total of 101.95 PetaFLOPS, assuming linear scaling at INT8 (FP8) precision. Of course, linear scaling is not quite possible in scale-out systems, which could bring it down to under 100 PetaFLOPS per rack.





19 Comments on Meta Announces New MTIA AI Accelerator with Improved Performance to Ease NVIDIA's Grip
Edit: Was looking at the Instances flops, maybe that is a bad comparison ¯\_(ツ)_/¯
More worrying is Meta's grip a known bad actor hehe
And with a bit of PR, they think they can swipe away Nvidia's marketshare? Don't think it works that way.
There is no floating point in int8...
Nvidia has plenty of competition in cloud services regardless of the hardware. What the market is lacking is competition in hardware that can be bought to run in the clients' installations.