The Alters Studio Confirms AI Use After Community Backlash
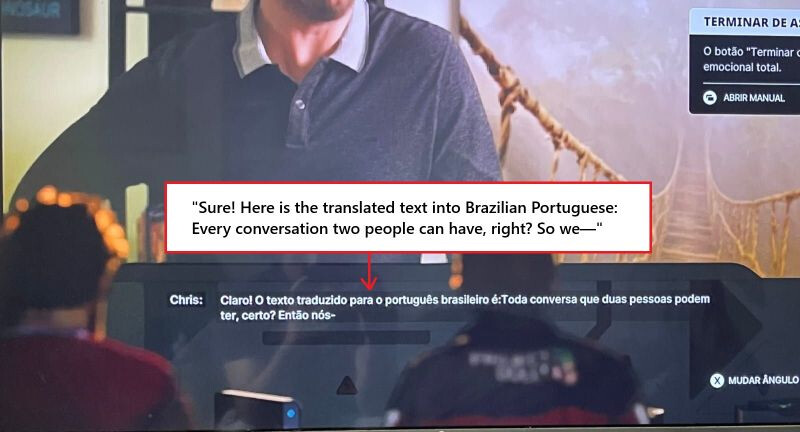
The latest game to fall into the trap of annoying or even estranging fans by using generative AI without disclosing it is The Alters. Accusations from the community over the use of generative AI in The Alters have been coming from all corners but most prominently from Steam reviews and the game's subreddit. The accusations included everything from AI-generated text in parts of the environment to AI-translated dialogue that included part of the AI prompt in the final game. These accusations became so commonplace that gamers even started to suspect that some of the visual assets had been created with generative AI. Adding insult to injury, there was no disclosure on the game's Steam page that confirmed the use of AI, so it seemed as though 11 Bit Studios was trying to hide the use of AI-generated content in The Alters.
After the allegations started to make the news, though, 11 Bit Studios responded to the accusations, explaining that generative AI was used during the development of The Alters, specifying that "AI-generated text for a graphic asset, which was meant as a piece of background texture, was used by one of our graphical designers as a placeholder." The studio goes on to explain that the asset was never meant to make it into the final version of the game, and that it has conducted a thorough investigation and determined that this is the only instance of AI-generated placeholders making it into the game. 11 Bit Studios also says that there are instances of "last-minute translations" made to some of the licensed movies that characters can watch in the game—these are seemingly the examples pointed out by a game localization expert on LinkedIn. According to the statement put out by the game studio, the studio's usual translation partners were not included in the localization hotfix, which largely adds to the concerns of those who oppose the use of generative AI in media and gaming, since that work would likely have been done by a human instead of an LLM. Ultimately, the studio made the decision to use AI instead of its translation partner because of time constraints, and it acknowledges that it should have disclosed the use of AI from the outset.

After the allegations started to make the news, though, 11 Bit Studios responded to the accusations, explaining that generative AI was used during the development of The Alters, specifying that "AI-generated text for a graphic asset, which was meant as a piece of background texture, was used by one of our graphical designers as a placeholder." The studio goes on to explain that the asset was never meant to make it into the final version of the game, and that it has conducted a thorough investigation and determined that this is the only instance of AI-generated placeholders making it into the game. 11 Bit Studios also says that there are instances of "last-minute translations" made to some of the licensed movies that characters can watch in the game—these are seemingly the examples pointed out by a game localization expert on LinkedIn. According to the statement put out by the game studio, the studio's usual translation partners were not included in the localization hotfix, which largely adds to the concerns of those who oppose the use of generative AI in media and gaming, since that work would likely have been done by a human instead of an LLM. Ultimately, the studio made the decision to use AI instead of its translation partner because of time constraints, and it acknowledges that it should have disclosed the use of AI from the outset.