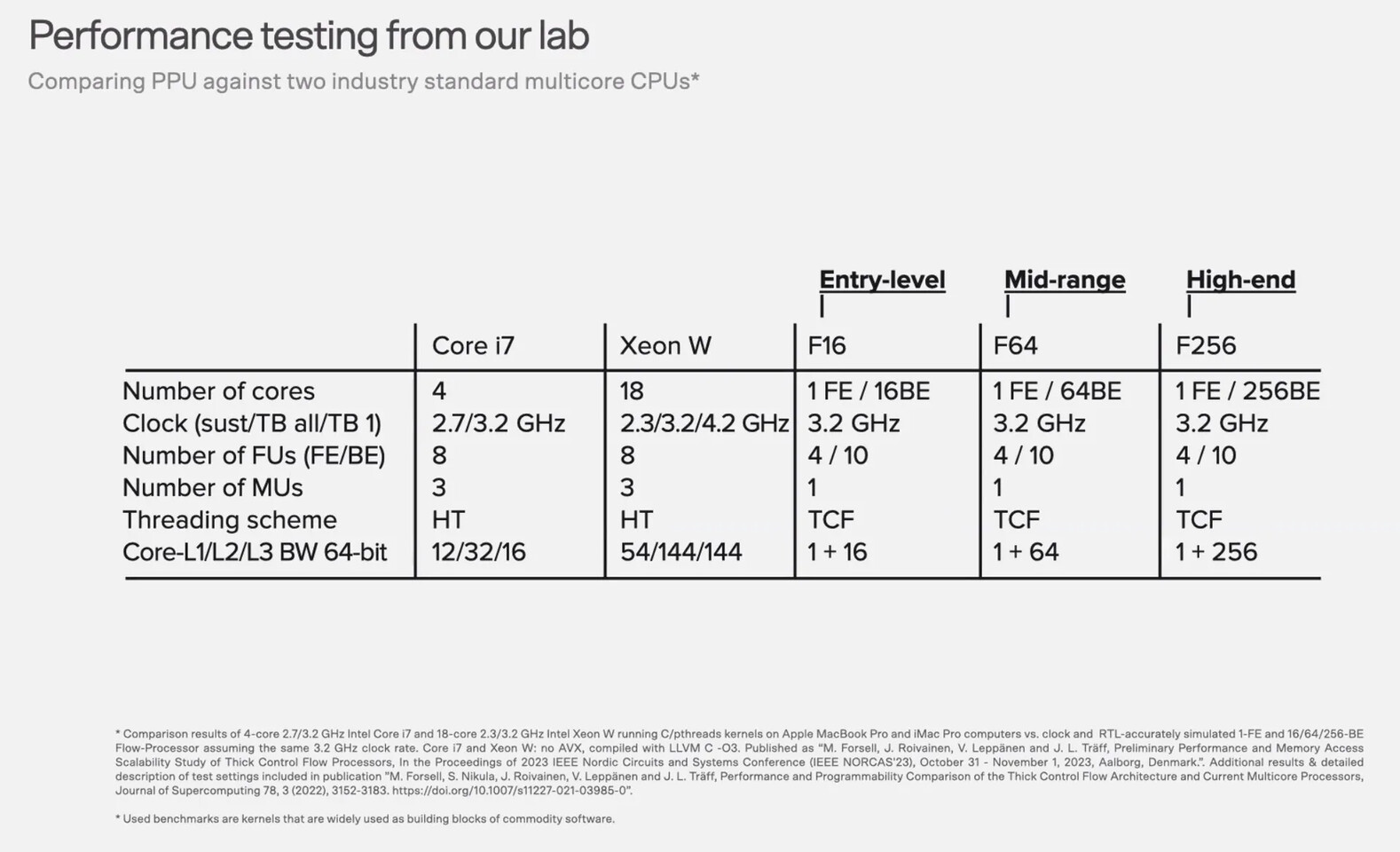
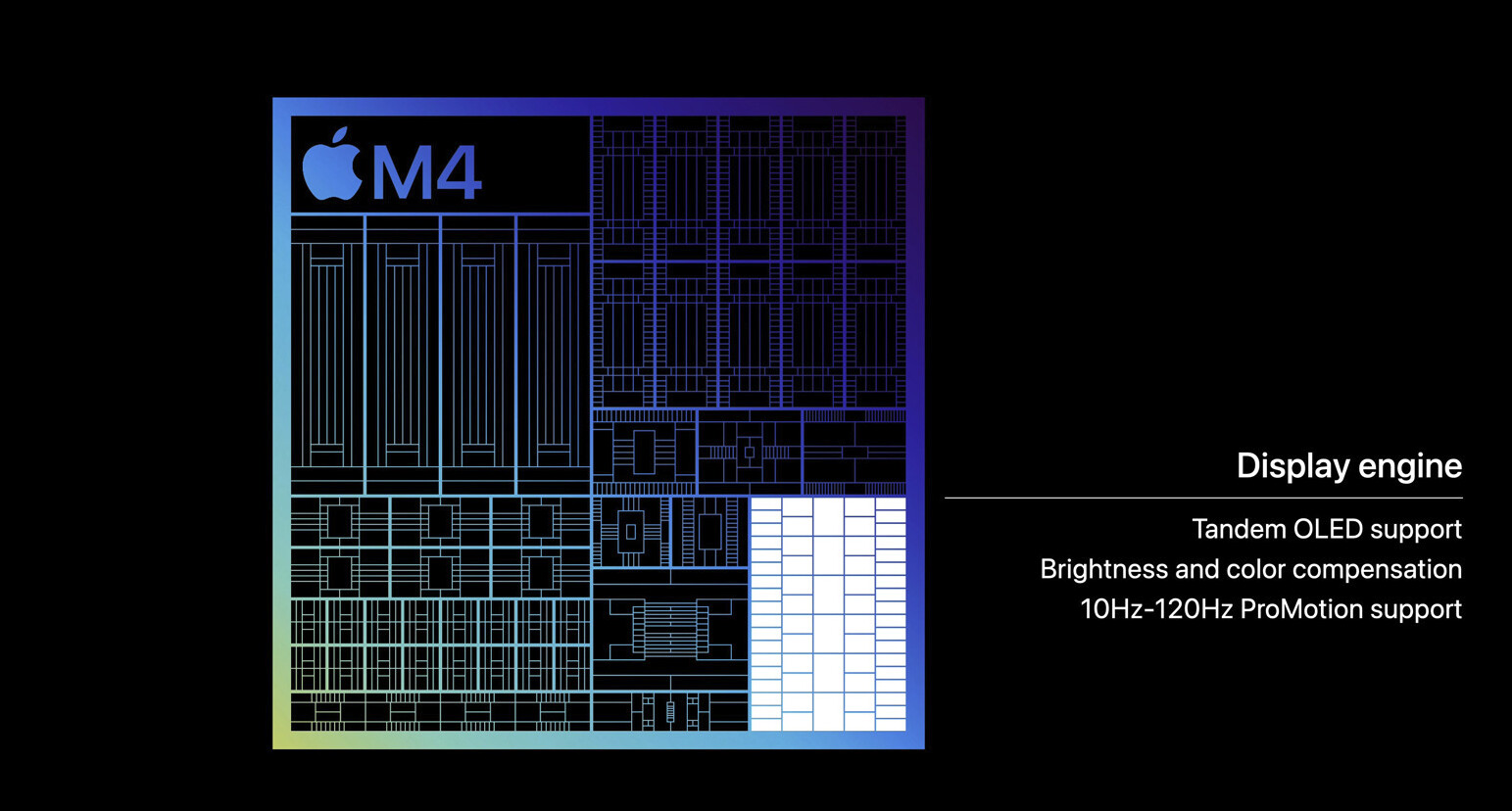
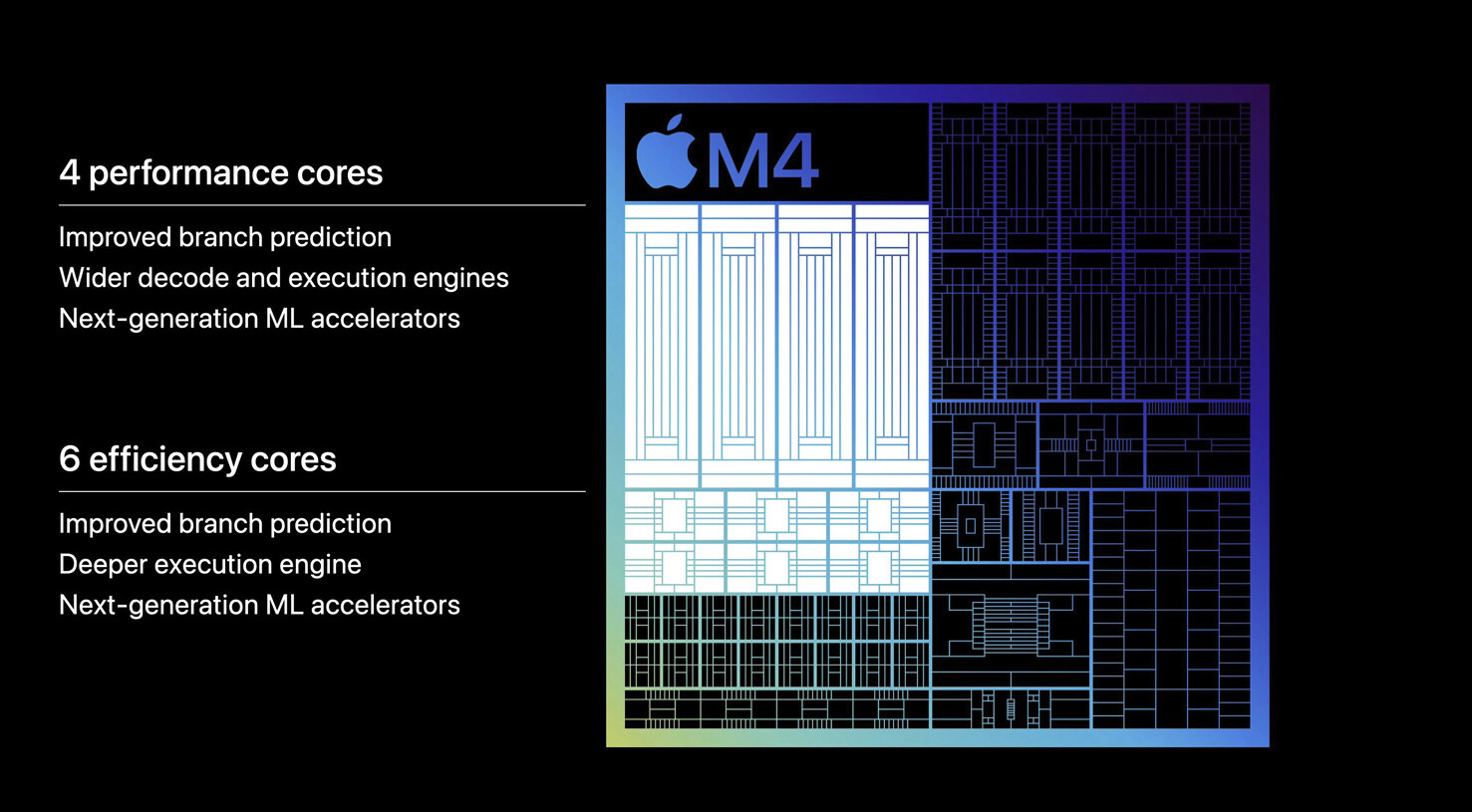
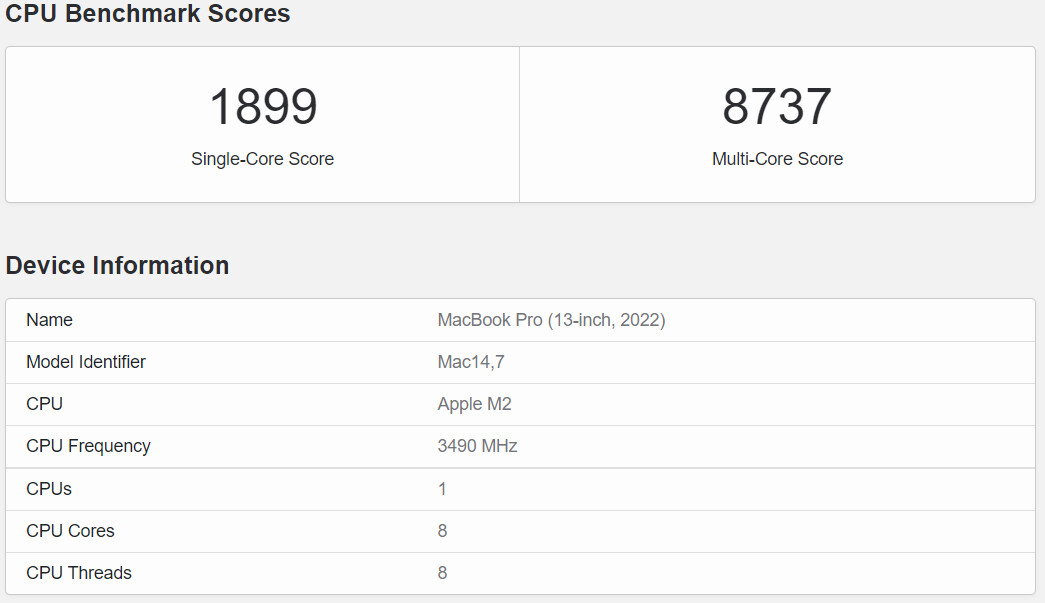
Alphawave Semi Tapes Out New UCIe IP on TSMC 2nm Supporting 36G Die-to-Die Data Rates
Alphawave Semi, a global leader in high-speed connectivity and compute silicon for the world's technology infrastructure, announced the successful tape out of one of the industry's first UCIe IP subsystem on TSMC's N2 process, supporting 36G die-to-die data rates. The solution is fully integrated with TSMC's Chip-on-Wafer-on-Substrate (CoWoS ) advanced packaging technology, unlocking breakthrough bandwidth density and scalability for next-generation chiplet architectures.
This milestone builds on the recent release of the Alphawave Semi AI Platform, proving readiness to support the future of disaggregated SoCs and scale-up infrastructure for hyperscale AI and HPC workloads. With this tape-out, Alphawave Semi becomes one of the industry's first to enable UCIe connectivity on 2 nm nanosheet technology, marking a major step forward for the open chiplet ecosystem.

This milestone builds on the recent release of the Alphawave Semi AI Platform, proving readiness to support the future of disaggregated SoCs and scale-up infrastructure for hyperscale AI and HPC workloads. With this tape-out, Alphawave Semi becomes one of the industry's first to enable UCIe connectivity on 2 nm nanosheet technology, marking a major step forward for the open chiplet ecosystem.