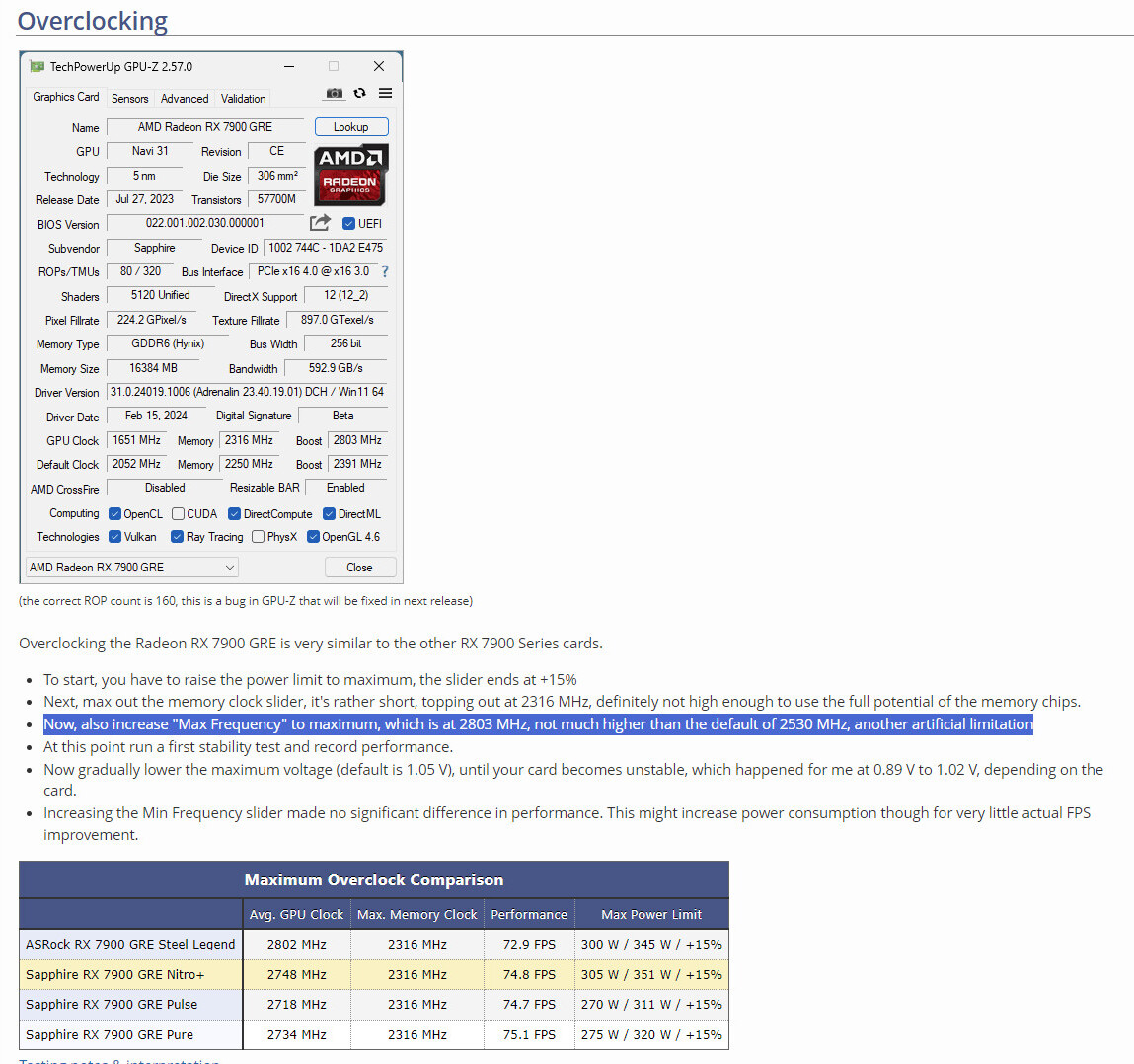
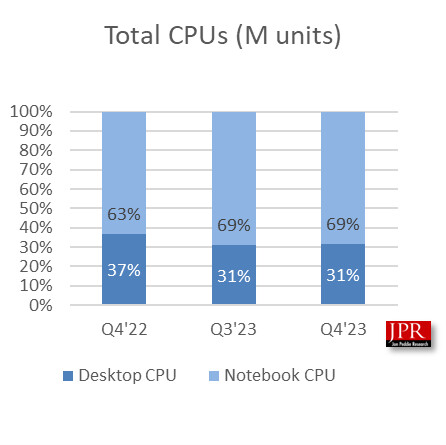
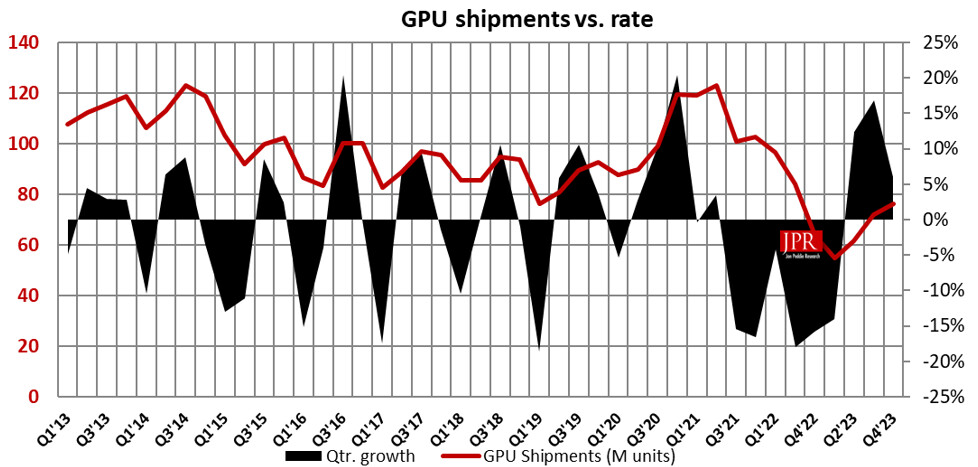
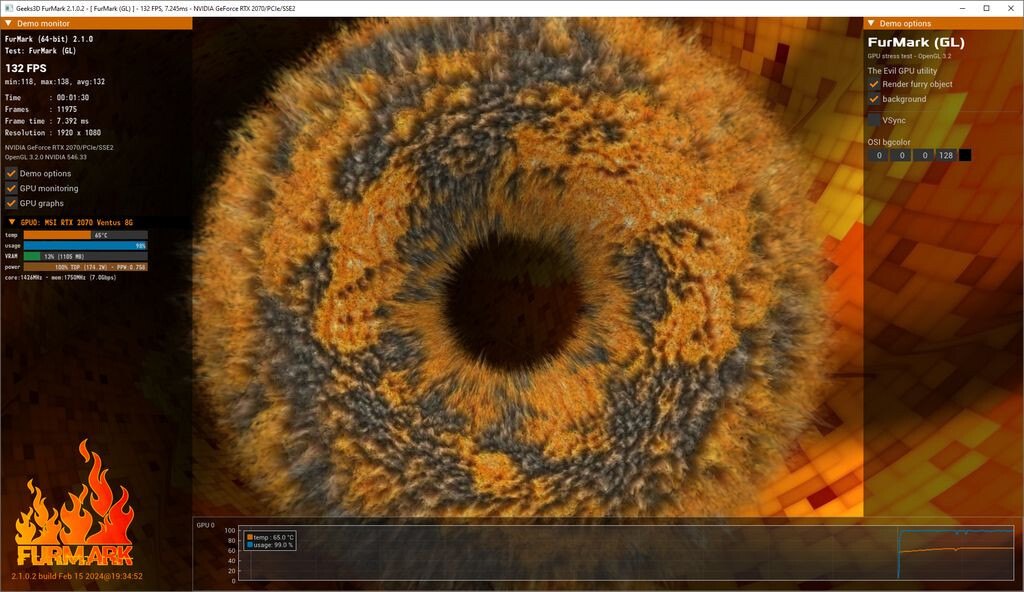
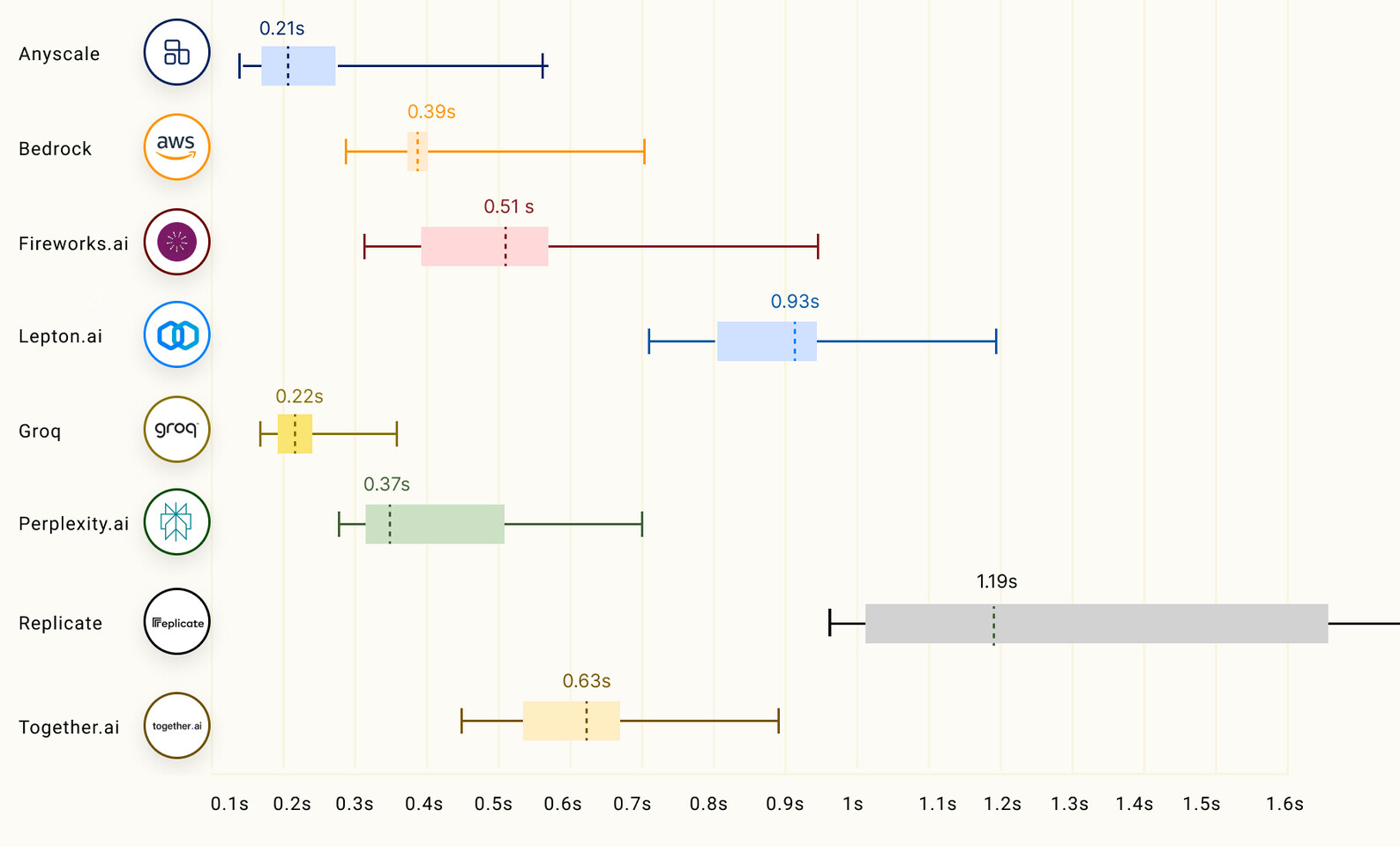
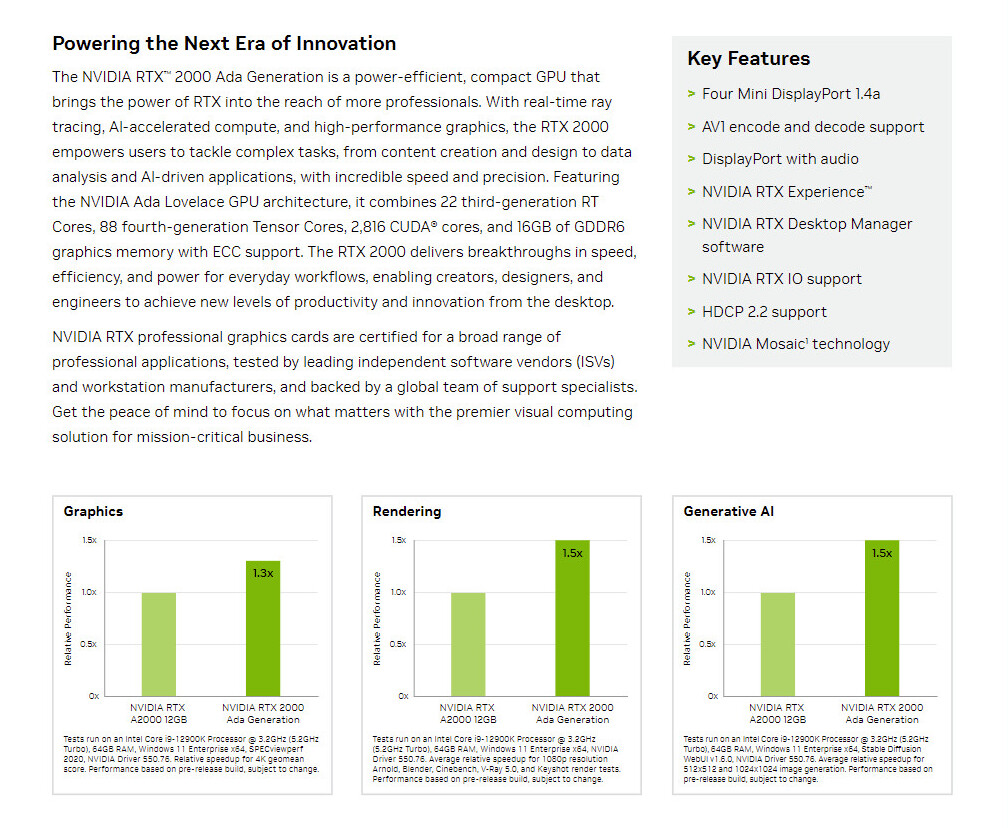
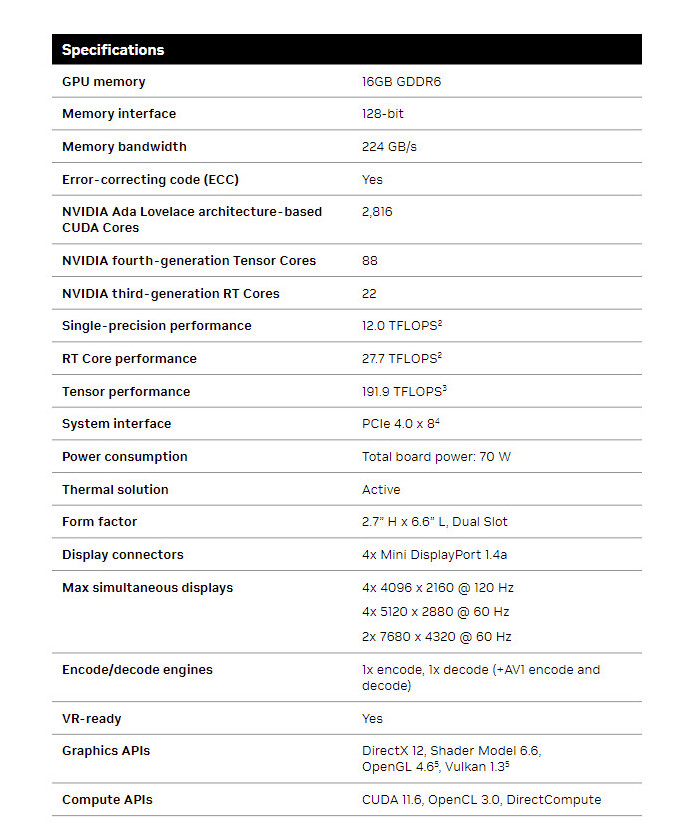
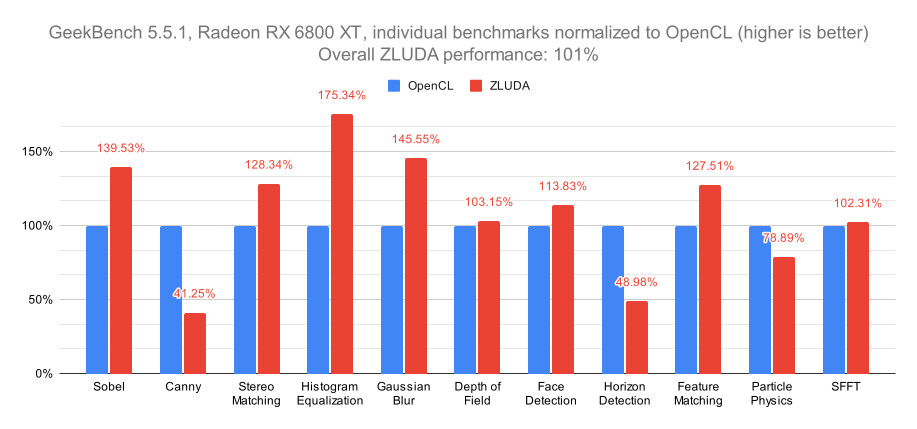
Tulpar Preparing "Custom" Intel Arc A770 Model for Q3 2024 Launch
Tulpar, an emerging PC gaming hardware company, has been doing the rounds across several European tech events—they demoed Meteor Lake-powered handheld devices at last month's Intel Extreme Masters tour stop in Katowice, Poland. A Hardwareluxx Germany report presented evidence of the Turkish company expanding into graphics card market sectors—Tulpar exhibited their "customized" Intel Arc A770 16 GB model at a recent trade show in Berlin. Andreas Schilling, resident editor at Hardwareluxx, realized that Tulpar had simply rebadged and color adjusted ASRock's Arc A770 Phantom D OC card design.
Tulpar's product placard boasted about their own "3X Cooling System"—a thin renaming of the already well-known ASRock Phantom Gaming triple-fan cooling solution. Their reliance on OEM designs is not a major revelation—the Tulpar 7-inch handheld gaming PC appears to be based on an existing platform—somewhat similar to Emdoor's EM-GP080MTL. Company representatives estimate that their "first dedicated gaming GPU" will be hitting retail within the third quarter of this year. News outlets have questioned this curious launch window—first generation Intel Arc "Alchemist" graphics cards (released in late 2022) are a tough sell, even with a much improved driver ecosystem delivering significant improvements throughout 2023/2024. Tulpar could be targeting a super budget price point, since Team Blue has signalled that their next-gen "Battlemage" GPUs are due later on in the year.



Tulpar's product placard boasted about their own "3X Cooling System"—a thin renaming of the already well-known ASRock Phantom Gaming triple-fan cooling solution. Their reliance on OEM designs is not a major revelation—the Tulpar 7-inch handheld gaming PC appears to be based on an existing platform—somewhat similar to Emdoor's EM-GP080MTL. Company representatives estimate that their "first dedicated gaming GPU" will be hitting retail within the third quarter of this year. News outlets have questioned this curious launch window—first generation Intel Arc "Alchemist" graphics cards (released in late 2022) are a tough sell, even with a much improved driver ecosystem delivering significant improvements throughout 2023/2024. Tulpar could be targeting a super budget price point, since Team Blue has signalled that their next-gen "Battlemage" GPUs are due later on in the year.