Apr 15th, 2025 09:10 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Thermaltake riing plus 12 rgb and other rgb fans. (7)
- Overclocking Micron F-die RAM (6)
- RX 9000 series GPU Owners Club (320)
- SK hynix A-Die (Overclocking thread) only for RYZEN AM5 users (36)
- Lian Li O11 Dynamic XL ROG. (18)
- DTS DCH Driver for Realtek HDA [DTS:X APO4 + DTS Interactive] (2136)
- Whats your favourite Linux Distro? (226)
- Need some help with vbios flashing (4)
- Asus ZenWifi BE14000 3pk or Orbi 770 3pk (2)
- The VHS to PC struggle (26)
Popular Reviews
- G.SKILL Trident Z5 NEO RGB DDR5-6000 32 GB CL26 Review - AMD EXPO
- ASUS GeForce RTX 5080 TUF OC Review
- Thermaltake TR100 Review
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- TerraMaster F8 SSD Plus Review - Compact and quiet
- DAREU A950 Wing Review
- Sapphire Radeon RX 9070 XT Pulse Review
- Zotac GeForce RTX 5070 Ti Amp Extreme Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (124)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)
- NVIDIA Pushes GeForce RTX 5060 Ti Launch to Mid-April, RTX 5060 to May (77)
News Posts matching #GPU
Return to Keyword Browsing
NVIDIA and Microsoft Showcase Blackwell Preview, Omniverse Industrial AI and RTX AI PCs at Microsoft Ignite
NVIDIA and Microsoft today unveiled product integrations designed to advance full-stack NVIDIA AI development on Microsoft platforms and applications. At Microsoft Ignite, Microsoft announced the launch of the first cloud private preview of the Azure ND GB200 V6 VM series, based on the NVIDIA Blackwell platform. The Azure ND GB200 v6 will be a new AI-optimized virtual machine (VM) series and combines the NVIDIA GB200 NVL72 rack design with NVIDIA Quantum InfiniBand networking.
In addition, Microsoft revealed that Azure Container Apps now supports NVIDIA GPUs, enabling simplified and scalable AI deployment. Plus, the NVIDIA AI platform on Azure includes new reference workflows for industrial AI and an NVIDIA Omniverse Blueprint for creating immersive, AI-powered visuals. At Ignite, NVIDIA also announced multimodal small language models (SLMs) for RTX AI PCs and workstations, enhancing digital human interactions and virtual assistants with greater realism.
In addition, Microsoft revealed that Azure Container Apps now supports NVIDIA GPUs, enabling simplified and scalable AI deployment. Plus, the NVIDIA AI platform on Azure includes new reference workflows for industrial AI and an NVIDIA Omniverse Blueprint for creating immersive, AI-powered visuals. At Ignite, NVIDIA also announced multimodal small language models (SLMs) for RTX AI PCs and workstations, enhancing digital human interactions and virtual assistants with greater realism.

Hypertec Introduces the World's Most Advanced Immersion-Born GPU Server
Hypertec proudly announces the launch of its latest breakthrough product, the TRIDENT iG series, an immersion-born GPU server line that brings extreme density, sustainability, and performance to the AI and HPC community. Purpose-built for the most demanding AI applications, this cutting-edge server is optimized for generative AI, machine learning (ML), deep learning (DL), large language model (LLM) training, inference, and beyond. With up to six of the latest NVIDIA GPUs in a 2U form factor, a staggering 8 TB of memory with enhanced RDMA capabilities, and groundbreaking density supporting up to 200 GPUs per immersion tank, the TRIDENT iG server line is a game-changer for AI infrastructure.
Additionally, the server's innovative design features a single or dual root complex, enabling greater flexibility and efficiency for GPU usage in complex workloads.
Additionally, the server's innovative design features a single or dual root complex, enabling greater flexibility and efficiency for GPU usage in complex workloads.

NVIDIA Announces Hopper H200 NVL PCIe GPU Availability at SC24, Promising 1.3x HPC Performance Over H100 NVL
Since its introduction, the NVIDIA Hopper architecture has transformed the AI and high-performance computing (HPC) landscape, helping enterprises, researchers and developers tackle the world's most complex challenges with higher performance and greater energy efficiency. During the Supercomputing 2024 conference, NVIDIA announced the availability of the NVIDIA H200 NVL PCIe GPU - the latest addition to the Hopper family. H200 NVL is ideal for organizations with data centers looking for lower-power, air-cooled enterprise rack designs with flexible configurations to deliver acceleration for every AI and HPC workload, regardless of size.
According to a recent survey, roughly 70% of enterprise racks are 20kW and below and use air cooling. This makes PCIe GPUs essential, as they provide granularity of node deployment, whether using one, two, four or eight GPUs - enabling data centers to pack more computing power into smaller spaces. Companies can then use their existing racks and select the number of GPUs that best suits their needs. Enterprises can use H200 NVL to accelerate AI and HPC applications, while also improving energy efficiency through reduced power consumption. With a 1.5x memory increase and 1.2x bandwidth increase over NVIDIA H100 NVL, companies can use H200 NVL to fine-tune LLMs within a few hours and deliver up to 1.7x faster inference performance. For HPC workloads, performance is boosted up to 1.3x over H100 NVL and 2.5x over the NVIDIA Ampere architecture generation.
According to a recent survey, roughly 70% of enterprise racks are 20kW and below and use air cooling. This makes PCIe GPUs essential, as they provide granularity of node deployment, whether using one, two, four or eight GPUs - enabling data centers to pack more computing power into smaller spaces. Companies can then use their existing racks and select the number of GPUs that best suits their needs. Enterprises can use H200 NVL to accelerate AI and HPC applications, while also improving energy efficiency through reduced power consumption. With a 1.5x memory increase and 1.2x bandwidth increase over NVIDIA H100 NVL, companies can use H200 NVL to fine-tune LLMs within a few hours and deliver up to 1.7x faster inference performance. For HPC workloads, performance is boosted up to 1.3x over H100 NVL and 2.5x over the NVIDIA Ampere architecture generation.

NVIDIA "Blackwell" NVL72 Servers Reportedly Require Redesign Amid Overheating Problems
According to The Information, NVIDIA's latest "Blackwell" processors are reportedly encountering significant thermal management issues in high-density server configurations, potentially affecting deployment timelines for major tech companies. The challenges emerge specifically in NVL72 GB200 racks housing 72 GB200 processors, which can consume up to 120 kilowatts of power per rack, weighting a "mere" 3,000 pounds (or about 1.5 tons). These thermal concerns have prompted NVIDIA to revisit and modify its server rack designs multiple times to prevent performance degradation and potential hardware damage. Hyperscalers like Google, Meta, and Microsoft, who rely heavily on NVIDIA GPUs for training their advanced language models, have allegedly expressed concerns about possible delays in their data center deployment schedules.
The thermal management issues follow earlier setbacks related to a design flaw in the Blackwell production process. The problem stemmed from the complex CoWoS-L packaging technology, which connects dual chiplets using RDL interposer and LSI bridges. Thermal expansion mismatches between various components led to warping issues, requiring modifications to the GPU's metal layers and bump structures. A company spokesperson characterized these modifications as part of the standard development process, noting that a new photomask resolved this issue. The Information states that mass production of the revised Blackwell GPUs began in late October, with shipments expected to commence in late January. However, these timelines are unconfirmed by NVIDIA, and some server makers like Dell confirmed that these GB200 NVL72 liquid-cooled systems are shipping now, not in January, with CoreWave GPU cloud provider as a customer. The original report could be using older information, as Dell is one of NVIDIA's most significant partners and among the first in the supply chain to gain access to new GPU batches.
The thermal management issues follow earlier setbacks related to a design flaw in the Blackwell production process. The problem stemmed from the complex CoWoS-L packaging technology, which connects dual chiplets using RDL interposer and LSI bridges. Thermal expansion mismatches between various components led to warping issues, requiring modifications to the GPU's metal layers and bump structures. A company spokesperson characterized these modifications as part of the standard development process, noting that a new photomask resolved this issue. The Information states that mass production of the revised Blackwell GPUs began in late October, with shipments expected to commence in late January. However, these timelines are unconfirmed by NVIDIA, and some server makers like Dell confirmed that these GB200 NVL72 liquid-cooled systems are shipping now, not in January, with CoreWave GPU cloud provider as a customer. The original report could be using older information, as Dell is one of NVIDIA's most significant partners and among the first in the supply chain to gain access to new GPU batches.


GIGABYTE Launches AMD Radeon PRO W7800 AI TOP 48G Graphics Card
GIGABYTE TECHNOLOGY Co. Ltd, a leading manufacturer of premium gaming hardware, today launched the cutting-edge GIGABYTE AMD Radeon PRO W7800 AI TOP 48G. GIGABYTE has taken a significant leap forward with the release of the Radeon PRO W7800 AI TOP 48G graphics card, featuring AMD's RDNA 3 architecture and a massive 48 GB of GDDR6 memory. This significant increase in memory capacity, compared to its predecessor, provides workstation professionals, creators, and AI developers with incredible computational power to effortlessly handle complex design, rendering, and AI model training tasks.
GIGABYTE stands as the AMD professional graphics partner in the market, with a proven ability to design and manufacture the entire Radeon PRO series. Our dedication to quality products, unwavering business commitment, and comprehensive customer service empower us to deliver professional-grade GPU solutions, expanding user's choices in workstation and AI computing.



GIGABYTE stands as the AMD professional graphics partner in the market, with a proven ability to design and manufacture the entire Radeon PRO series. Our dedication to quality products, unwavering business commitment, and comprehensive customer service empower us to deliver professional-grade GPU solutions, expanding user's choices in workstation and AI computing.




NVIDIA B200 "Blackwell" Records 2.2x Performance Improvement Over its "Hopper" Predecessor
We know that NVIDIA's latest "Blackwell" GPUs are fast, but how much faster are they over the previous generation "Hopper"? Thanks to the latest MLPerf Training v4.1 results, NVIDIA's HGX B200 Blackwell platform has demonstrated massive performance gains, measuring up to 2.2x improvement per GPU compared to its HGX H200 Hopper. The latest results, verified by MLCommons, reveal impressive achievements in large language model (LLM) training. The Blackwell architecture, featuring HBM3e high-bandwidth memory and fifth-generation NVLink interconnect technology, achieved double the performance per GPU for GPT-3 pre-training and a 2.2x boost for Llama 2 70B fine-tuning compared to the previous Hopper generation. Each benchmark system incorporated eight Blackwell GPUs operating at a 1,000 W TDP, connected via NVLink Switch for scale-up.
The network infrastructure utilized NVIDIA ConnectX-7 SuperNICs and Quantum-2 InfiniBand switches, enabling high-speed node-to-node communication for distributed training workloads. While previous Hopper-based systems required 256 GPUs to optimize performance for the GPT-3 175B benchmark, Blackwell accomplished the same task with just 64 GPUs, leveraging its larger HBM3e memory capacity and bandwidth. One thing to look out for is the upcoming GB200 NVL72 system, which promises even more significant gains past the 2.2x. It features expanded NVLink domains, higher memory bandwidth, and tight integration with NVIDIA Grace CPUs, complemented by ConnectX-8 SuperNIC and Quantum-X800 switch technologies. With faster switching and better data movement with Grace-Blackwell integration, we could see even more software optimization from NVIDIA to push the performance envelope.
The network infrastructure utilized NVIDIA ConnectX-7 SuperNICs and Quantum-2 InfiniBand switches, enabling high-speed node-to-node communication for distributed training workloads. While previous Hopper-based systems required 256 GPUs to optimize performance for the GPT-3 175B benchmark, Blackwell accomplished the same task with just 64 GPUs, leveraging its larger HBM3e memory capacity and bandwidth. One thing to look out for is the upcoming GB200 NVL72 system, which promises even more significant gains past the 2.2x. It features expanded NVLink domains, higher memory bandwidth, and tight integration with NVIDIA Grace CPUs, complemented by ConnectX-8 SuperNIC and Quantum-X800 switch technologies. With faster switching and better data movement with Grace-Blackwell integration, we could see even more software optimization from NVIDIA to push the performance envelope.

Report: GPU Market Records Explosive Growth, Reaching $98.5 Billion in 2024
With the latest industry boom in AI, the demand for more compute power is greater than ever, and the recent industry forecast predicts that the global GPU market will exceed $98.5 billion in value by the year 2024. This staggering projection, outlined in the 2024 supply-side GPU market summary report by Jon Peddie Research (JPR), shows how far the GPU market has come. Once primarily associated with powering consumer gaming rigs with AMD or NVIDIA inside, GPUs have become a key part of our modern tech stack, worth almost $100 billion in 2024 alone. Nowadays, GPUs are found in many products, from smartphones and vehicles to internet-connected devices and data centers.
"Graphics processor units (GPUs) have become ubiquitous and can be found in almost every industrial, scientific, commercial, and consumer product made today," said Dr. Jon Peddie, founder of JPR. "Some market segments, like AI, have grabbed headlines because of their rapid growth and high average selling price (ASP), but they are low-volume compared to other market segments." The report also shows the wide range of companies that are actively participating in the GPU marketplace, including industry giants like AMD, NVIDIA, and Intel, as well as smaller players from China like Loongson Zhongke, Siroyw, and Lingjiu Micro. Besides the discrete GPU solutions, the GPU IP market is very competitive, and millions of chips are shipped with GPU IP every year. Some revenue estimates of Chinese companies are not public, but JPR is measuring it from the supply chain side, so these estimates are pretty plausible.


"Graphics processor units (GPUs) have become ubiquitous and can be found in almost every industrial, scientific, commercial, and consumer product made today," said Dr. Jon Peddie, founder of JPR. "Some market segments, like AI, have grabbed headlines because of their rapid growth and high average selling price (ASP), but they are low-volume compared to other market segments." The report also shows the wide range of companies that are actively participating in the GPU marketplace, including industry giants like AMD, NVIDIA, and Intel, as well as smaller players from China like Loongson Zhongke, Siroyw, and Lingjiu Micro. Besides the discrete GPU solutions, the GPU IP market is very competitive, and millions of chips are shipped with GPU IP every year. Some revenue estimates of Chinese companies are not public, but JPR is measuring it from the supply chain side, so these estimates are pretty plausible.




Sony Interactive Entertainment Launches the PlayStation 5 Pro
Today, Sony Interactive Entertainment expands the PlayStation 5 (PS5) family of products with the release of the new PlayStation 5 Pro (PS5 Pro) console - the company's most advanced and innovative gaming console to date. PlayStation 5 Pro was designed with deeply engaged players and game creators in mind and includes key performance features that allow games to run with higher fidelity graphics at smoother frame rates.
"With PlayStation 5 Pro, we wanted to make sure that the most dedicated gamers, as well as game creators, could utilize the most advanced console technology, taking the PlayStation 5 experience even farther," said Hideaki Nishino, CEO Platform Business Group, Sony Interactive Entertainment. "This is our most advanced PlayStation to date, and it gives our community of players the opportunity to experience games the way that developers intended for them to be. Players will be thrilled with how this console enhances some of their favorite titles, while opening avenues to discover new ones."
"With PlayStation 5 Pro, we wanted to make sure that the most dedicated gamers, as well as game creators, could utilize the most advanced console technology, taking the PlayStation 5 experience even farther," said Hideaki Nishino, CEO Platform Business Group, Sony Interactive Entertainment. "This is our most advanced PlayStation to date, and it gives our community of players the opportunity to experience games the way that developers intended for them to be. Players will be thrilled with how this console enhances some of their favorite titles, while opening avenues to discover new ones."


Nintendo Switch Successor: Backward Compatibility Confirmed for 2025 Launch
Nintendo has officially announced that its next-generation Switch console will feature backward compatibility, allowing players to use their existing game libraries on the new system. However, those eagerly awaiting the console's release may need to exercise patience as launch expectations have shifted to early 2025. On the official X account, Nintendo has announced: "At today's Corporate Management Policy Briefing, we announced that Nintendo Switch software will also be playable on the successor to Nintendo Switch. Nintendo Switch Online will be available on the successor to Nintendo Switch as well. Further information about the successor to Nintendo Switch, including its compatibility with Nintendo Switch, will be announced at a later date."
While the original Switch evolved from a 20 nm Tegra X1 to a more power-efficient 16 nm Tegra X1+ SoC (both featuring four Cortex-A57 and four Cortex-A53 cores with GM20B Maxwell GPUs), the Switch 2 is rumored to utilize a customized variant of NVIDIA's Jetson Orin SoC, now codenamed T239. The new chip represents a significant upgrade with its 12 Cortex-A78AE cores, LPDDR5 memory, and Ampere GPU architecture with 1,536 CUDA cores, promising enhanced battery efficiency and DLSS capabilities for the handheld gaming market. With the holiday 2024 release window now seemingly off the table, the new console is anticipated to debut in the first half of 2025, marking nearly eight years since the original Switch's launch.

While the original Switch evolved from a 20 nm Tegra X1 to a more power-efficient 16 nm Tegra X1+ SoC (both featuring four Cortex-A57 and four Cortex-A53 cores with GM20B Maxwell GPUs), the Switch 2 is rumored to utilize a customized variant of NVIDIA's Jetson Orin SoC, now codenamed T239. The new chip represents a significant upgrade with its 12 Cortex-A78AE cores, LPDDR5 memory, and Ampere GPU architecture with 1,536 CUDA cores, promising enhanced battery efficiency and DLSS capabilities for the handheld gaming market. With the holiday 2024 release window now seemingly off the table, the new console is anticipated to debut in the first half of 2025, marking nearly eight years since the original Switch's launch.



Sony's PS5 Pro To Launch on November 7 With Over 50 Enhanced Games
Many gamers have been skeptical of the recently announced Sony PS5 Pro since the day it was announced, largely due to the high price and the perceived lack of meaningful improvements. It seemed to many as though the PS5 Pro was simply a meaningless mid-cycle cash-grab with a few extra features tacked onto the top, however, it looks like Sony and its development partners have put in the work to make the PS5 Pro experience fresh and worthwhile. According to a new post on the official PlayStation Blog, the new console will launch with at least 50 confirmed "Enhanced" games.
What exactly Sony means by Enhanced is rather nebulous, since many of the Enhanced games for the PS5 Pro have a mishmash of different Pro features. For example, Resident Evil Village gets the full 120 FPS treatment, while Horizon Forbidden West only gets a bump up to 4K at 60 FPS. Stellar Blade, on the other hand, only gets an FPS boost to 80 FPS or 50 FPS at 4K. It's likely that, like Stellar Blade, all the titles aiming for higher refresh rates on the PS5 Pro are using some mix of PSSR, dedicated AI acceleration, and traditional rasterization rendering techniques to achieve the increased frame rates. Both The Last of Us Part I and The Last of Us II Remastered will run at 60 FPS on the PS5 Pro, but they will render at 1440p and use PSSR to upscale to 4K output.

What exactly Sony means by Enhanced is rather nebulous, since many of the Enhanced games for the PS5 Pro have a mishmash of different Pro features. For example, Resident Evil Village gets the full 120 FPS treatment, while Horizon Forbidden West only gets a bump up to 4K at 60 FPS. Stellar Blade, on the other hand, only gets an FPS boost to 80 FPS or 50 FPS at 4K. It's likely that, like Stellar Blade, all the titles aiming for higher refresh rates on the PS5 Pro are using some mix of PSSR, dedicated AI acceleration, and traditional rasterization rendering techniques to achieve the increased frame rates. Both The Last of Us Part I and The Last of Us II Remastered will run at 60 FPS on the PS5 Pro, but they will render at 1440p and use PSSR to upscale to 4K output.



AMD and Fujitsu to Begin Strategic Partnership to Create Computing Platforms for AI and High-Performance Computing (HPC)
AMD and Fujitsu Limited today announced that they have signed a memorandum of understanding (MOU) to form a strategic partnership to create computing platforms for AI and high-performance computing (HPC). The partnership, encompassing aspects from technology development to commercialization, will seek to facilitate the creation of open source and energy efficient platforms comprised of advanced processors with superior power performance and highly flexible AI/HPC software and aims to accelerate open-source AI and/or HPC initiatives.
Due to the rapid spread of AI, including generative AI, cloud service providers and end-users are seeking optimized architectures at various price and power per performance configurations. From end-to-end, AMD supports an open ecosystem, and strongly believes in giving customers choice. Fujitsu has worked to develop FUJITSU-MONAKA, a next-generation Arm-based processor that aims to achieve both high performance and low power consumption. With FUJITSU-MONAKA, together with AMD Instinct accelerators, customers have an additional choice to achieve large-scale AI workload processing to whilst attempting to reduce the data center total cost of ownership.
Due to the rapid spread of AI, including generative AI, cloud service providers and end-users are seeking optimized architectures at various price and power per performance configurations. From end-to-end, AMD supports an open ecosystem, and strongly believes in giving customers choice. Fujitsu has worked to develop FUJITSU-MONAKA, a next-generation Arm-based processor that aims to achieve both high performance and low power consumption. With FUJITSU-MONAKA, together with AMD Instinct accelerators, customers have an additional choice to achieve large-scale AI workload processing to whilst attempting to reduce the data center total cost of ownership.


AMD Falling Behind: Radeon dGPUs Absent from Steam's Top 20
As we entered November, Valve just finished processing data for October in its monthly update of Steam Hardware and Software Survey, showcasing trend changes in the largest gaming community. And according to October data, AMD's discrete GPUs are not exactly in the best place. In the top 20 most commonly used GPUs, not a single discrete SKU was based on AMD. All of them included NVIDIA as their primary GPU choice. However, there is some change to AMD's entries, as the Radeon RX 580, which used to be the most popular AMD GPU, just got bested by the Radeon RX 6600 as the most common choice for AMD gamers. The AMD Radeon RX 6600 now holds 0.98% of the GPU market.
NVIDIA's situation paints a different picture, as the top 20 spots are all occupied by NVIDIA-powered gamers. The GeForce RTX 3060 remains the most popular GPU at 7.46% of the GPU market, but the number two spot is now held by the GeForce RTX 4060 Laptop GPU at 5.61%. This is an interesting change since this NVIDIA GPU was in third place, right behind the regular GeForce RTX 4060 for desktops. However, laptop gamers are in abundance, and they are showing their strength, placing the desktop GeForce RTX 4060 in third place, recording 5.25% usage.

NVIDIA's situation paints a different picture, as the top 20 spots are all occupied by NVIDIA-powered gamers. The GeForce RTX 3060 remains the most popular GPU at 7.46% of the GPU market, but the number two spot is now held by the GeForce RTX 4060 Laptop GPU at 5.61%. This is an interesting change since this NVIDIA GPU was in third place, right behind the regular GeForce RTX 4060 for desktops. However, laptop gamers are in abundance, and they are showing their strength, placing the desktop GeForce RTX 4060 in third place, recording 5.25% usage.


New Arm CPUs from NVIDIA Coming in 2025
According to DigiTimes, NVIDIA is reportedly targeting the high-end segment for its first consumer CPU attempt. Slated to arrive in 2025, NVIDIA is partnering with MediaTek to break into the AI PC market, currently being popularized by Qualcomm, Intel, and AMD. With Microsoft and Qualcomm laying the foundation for Windows-on-Arm (WoA) development, NVIDIA plans to join and leverage its massive ecosystem of partners to design and deliver regular applications and games for its Arm-based processors. At the same time, NVIDIA is also scheduled to launch "Blackwell" GPUs for consumers, which could end up in these AI PCs with an Arm CPU at its core.
NVIDIA's partner, MediaTek, has recently launched a big core SoC for mobile called Dimensity 9400. NVIDIA could use something like that as a base for its SoC and add its Blackwell IP to the mix. This would be similar to what Apple is doing with its Apple Silicon and the recent M4 Max chip, which is apparently the fastest CPU in single-threaded and multithreaded workloads, as per recent Geekbench recordings. For NVIDIA, the company already has a team of CPU designers that delivered its Grace CPU to enterprise/server customers. Using off-the-shelf Arm Neoverse IP, the company's customers are acquiring systems with Grace CPUs as fast as they are produced. This puts a lot of hope into NVIDIA's upcoming AI PC, which could offer a selling point no other WoA device currently provides, and that is tried and tested gaming-grade GPU with AI accelerators.
NVIDIA's partner, MediaTek, has recently launched a big core SoC for mobile called Dimensity 9400. NVIDIA could use something like that as a base for its SoC and add its Blackwell IP to the mix. This would be similar to what Apple is doing with its Apple Silicon and the recent M4 Max chip, which is apparently the fastest CPU in single-threaded and multithreaded workloads, as per recent Geekbench recordings. For NVIDIA, the company already has a team of CPU designers that delivered its Grace CPU to enterprise/server customers. Using off-the-shelf Arm Neoverse IP, the company's customers are acquiring systems with Grace CPUs as fast as they are produced. This puts a lot of hope into NVIDIA's upcoming AI PC, which could offer a selling point no other WoA device currently provides, and that is tried and tested gaming-grade GPU with AI accelerators.

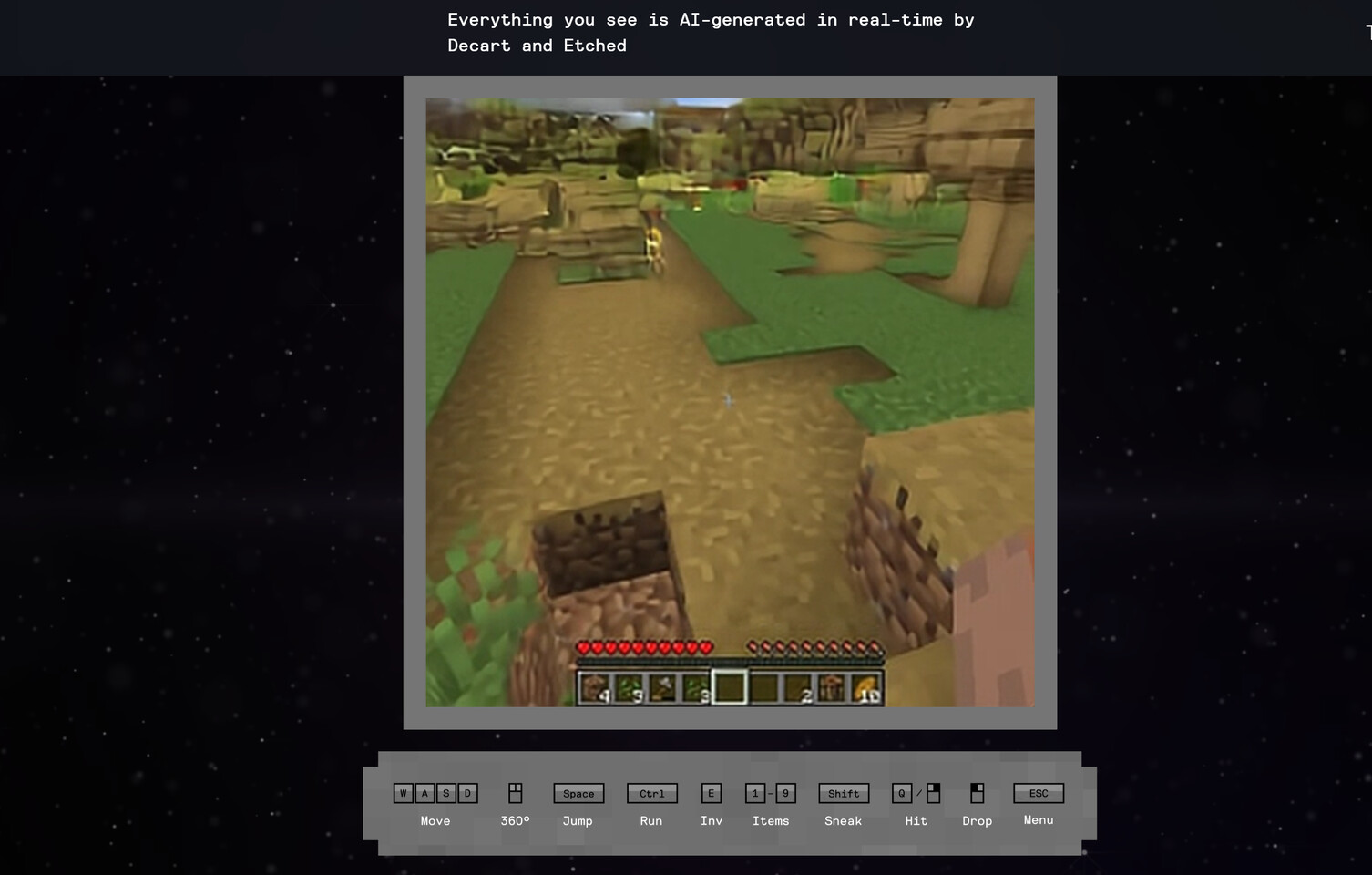
Etched Introduces AI-Powered Games Without GPUs, Displays Minecraft Replica
The gaming industry is about to get massively disrupted. Instead of using game engines to power games, we are now witnessing an entirely new and crazy concept. A startup specializing in designing ASICs specifically for Transformer architecture, the foundation behind generative AI models like GPT/Claude/Stable Diffusion, has showcased a demo in partnership with Decart of a Minecraft clone being entirely generated and operated by AI instead of the traditional game engine. While we use AI to create images and videos based on specific descriptions and output pretty realistic content, having an AI model spit out an entire playable game is something different. Oasis is the first playable, real-time, real-time, open-world AI model that takes users' input and generates real-time gameplay, including physics, game rules, and graphics.
An interesting thing to point out is the hardware that powers this setup. Using a single NVIDIA H100 GPU, this 500-million parameter Oasis model can run at 720p resolution at 20 generated frames per second. Due to limitations of accelerators like NVIDIA's H100/B200, gameplay at 4K is almost impossible. However, Etched has its own accelerator called Sohu, which is specialized in accelerating transformer architectures. Eight NVIDIA H100 GPUs can power five Oasis models to five users, while the eight Sohu cards are capable of serving 65 Oasis runs to 65 users. This is more than a 10x increase in inference capability compared to NVIDIA's hardware on a single-use case alone. The accelerator is designed to run much larger models like future 100 billion-parameter generative AI video game models that can output 4K 30 FPS, all thanks to 144 GB of HBM3E memory, yielding 1,152 GB in eight-accelerator server configuration.



An interesting thing to point out is the hardware that powers this setup. Using a single NVIDIA H100 GPU, this 500-million parameter Oasis model can run at 720p resolution at 20 generated frames per second. Due to limitations of accelerators like NVIDIA's H100/B200, gameplay at 4K is almost impossible. However, Etched has its own accelerator called Sohu, which is specialized in accelerating transformer architectures. Eight NVIDIA H100 GPUs can power five Oasis models to five users, while the eight Sohu cards are capable of serving 65 Oasis runs to 65 users. This is more than a 10x increase in inference capability compared to NVIDIA's hardware on a single-use case alone. The accelerator is designed to run much larger models like future 100 billion-parameter generative AI video game models that can output 4K 30 FPS, all thanks to 144 GB of HBM3E memory, yielding 1,152 GB in eight-accelerator server configuration.



NVIDIA Ethernet Networking Accelerates World's Largest AI Supercomputer, Built by xAI
NVIDIA today announced that xAI's Colossus supercomputer cluster comprising 100,000 NVIDIA Hopper GPUs in Memphis, Tennessee, achieved this massive scale by using the NVIDIA Spectrum-X Ethernet networking platform, which is designed to deliver superior performance to multi-tenant, hyperscale AI factories using standards-based Ethernet, for its Remote Direct Memory Access (RDMA) network.
Colossus, the world's largest AI supercomputer, is being used to train xAI's Grok family of large language models, with chatbots offered as a feature for X Premium subscribers. xAI is in the process of doubling the size of Colossus to a combined total of 200,000 NVIDIA Hopper GPUs.
Colossus, the world's largest AI supercomputer, is being used to train xAI's Grok family of large language models, with chatbots offered as a feature for X Premium subscribers. xAI is in the process of doubling the size of Colossus to a combined total of 200,000 NVIDIA Hopper GPUs.


Interview with RISC-V International: High-Performance Chips, AI, Ecosystem Fragmentation, and The Future
RISC-V is an industry standard instruction set architecture (ISA) born in UC Berkeley. RISC-V is the fifth iteration in the lineage of historic RISC processors. The core value of the RISC-V ISA is the freedom of usage it offers. Any organization can leverage the ISA to design the best possible core for their specific needs, with no regional restrictions or licensing costs. It attracts a massive ecosystem of developers and companies building systems using the RISC-V ISA. To support these efforts and grow the ecosystem, the brains behind RISC decided to form RISC-V International—a non-profit foundation that governs the ISA and guides the ecosystem.
We had the privilege of talking with Andrea Gallo, Vice President of Technology at RISC-V International. Andrea oversees the technological advancement of RISC-V, collaborating with vendors and institutions to overcome challenges and expand its global presence. Andrea's career in technology spans several influential roles at major companies. Before joining RISC-V International, he worked at Linaro, where he pioneered Arm data center engineering initiatives, later overseeing diverse technological sectors as Vice President of Segment Groups, and ultimately managing crucial business development activities as executive Vice President. During his earlier tenure as a Fellow at ST-Ericsson, he focused on smartphone and application processor technology, and at STMicroelectronics he optimized hardware-software architectures and established international development teams.

We had the privilege of talking with Andrea Gallo, Vice President of Technology at RISC-V International. Andrea oversees the technological advancement of RISC-V, collaborating with vendors and institutions to overcome challenges and expand its global presence. Andrea's career in technology spans several influential roles at major companies. Before joining RISC-V International, he worked at Linaro, where he pioneered Arm data center engineering initiatives, later overseeing diverse technological sectors as Vice President of Segment Groups, and ultimately managing crucial business development activities as executive Vice President. During his earlier tenure as a Fellow at ST-Ericsson, he focused on smartphone and application processor technology, and at STMicroelectronics he optimized hardware-software architectures and established international development teams.


AYANEO AG01 Starship Graphics Dock to Hit Shelves in Late November with a $599 Price Tag
AYANEO makes a plethora of commendable products, including eGPU docks. The brand's newest AG01 Starship Graphics Dock will soon join the family, with a shipping date set for the end of November. The dock sports a fascinating design which, unfortunately, might be a tad too ostentatious for some.
The unit is powered by the RDNA 3-based Radeon RX 7600M XT graphics card. It is by no means the fastest kid on the block, but is still a very decent GPU, and should provide ample performance for most gaming and creative tasks. But that's not all - as the name suggests, the AG01 Starship also functions as a dock with a respectable array of ports including a USB 4 port with PD, an RJ 45 Gigabit LAN port, a USB 3.2 Gen 2 Type-A port, along with an M.2 2280 PCIe 3.0 slot for storage.
The unit is powered by the RDNA 3-based Radeon RX 7600M XT graphics card. It is by no means the fastest kid on the block, but is still a very decent GPU, and should provide ample performance for most gaming and creative tasks. But that's not all - as the name suggests, the AG01 Starship also functions as a dock with a respectable array of ports including a USB 4 port with PD, an RJ 45 Gigabit LAN port, a USB 3.2 Gen 2 Type-A port, along with an M.2 2280 PCIe 3.0 slot for storage.


Google's Upcoming Tensor G5 and G6 Specs Might Have Been Revealed Early
Details of what is claimed to be Google's upcoming Tensor G5 and G6 SoCs have popped up over on Notebookcheck.net and the site claims to have found the specs on a public platform, without going into any further details. Those that were betting on the Tensor G5—codenamed Laguna—delivering vastly improved performance over the Tensor G4, are likely to be disappointed, at least on the CPU side of things. As previous rumours have suggested, the chip is expected to be manufactured by TSMC, using its N3E process node, but the Tensor G5 will retain the single Arm Cortex-X4 core, although it will see a slight upgrade to five Cortex-A725 cores vs. the three Cortex-A720 cores of the Tensor G4. The G5 loses two Cortex-A520 cores in favour of the extra Cortex-A725 cores. The Cortex-X4 will also remain clocked at the same peak 3.1 GHz as that of the Tensor G4.
Interestingly it looks like Google will drop the Arm Mali GPU in favour of an Imagination Technologies DXT GPU, although the specs listed by Notebookcheck doesn't add up with any of the specs listed by Imagination Technologies. The G5 will continue to support 4x 16-bit LPDDR5 or LPDDR5X memory chips, but Google has added support for UFS 4.0 memory, something that's been a point of complaint for the Tensor G4. Other new additions is support for 10 Gbps USB 3.2 Gen 2 and PCI Express 4.0. Some improvements to the camera logic has also been made, with support for up to 200 Megapixel sensors or 108 Megapixels with zero shutter lag, but if Google will use such a camera or not is anyone's guess at this point in time.
Interestingly it looks like Google will drop the Arm Mali GPU in favour of an Imagination Technologies DXT GPU, although the specs listed by Notebookcheck doesn't add up with any of the specs listed by Imagination Technologies. The G5 will continue to support 4x 16-bit LPDDR5 or LPDDR5X memory chips, but Google has added support for UFS 4.0 memory, something that's been a point of complaint for the Tensor G4. Other new additions is support for 10 Gbps USB 3.2 Gen 2 and PCI Express 4.0. Some improvements to the camera logic has also been made, with support for up to 200 Megapixel sensors or 108 Megapixels with zero shutter lag, but if Google will use such a camera or not is anyone's guess at this point in time.


Micron SSDs Qualified for Recommended Vendor List on NVIDIA GB200 NVL72
Micron Technology, Inc., today announced that its 9550 PCIe Gen 5 E1.S data center SSDs have been added to the NVIDIA recommended vendor list (RVL) for the NVIDIA GB200 NVL72 system and its derivatives. The GB200 NVL72 uses the GB200 Grace Blackwell Superchip to deliver rack-scale, energy-efficient AI infrastructure. The enablement of PCIe Gen 5 storage in the system makes the Micron 9550 SSD an ideal fit for optimizing performance and power efficiency in AI workloads like large-scale training of AI models, real-time trillion-parameter language model inference and high-performance computing (HPC) tasks.
Micron 9550 delivers world-class AI workload performance and power efficiency:
Compared with other industry offerings, the 9550 SSD delivers up to 34% higher throughput for NVIDIA Magnum IO GPUDirect (GDS) and up to 33% faster workload completion times in graph neural network (GNN) training with Big Accelerator Memory (BaM). The Micron 9550 SSD saves energy and sets new sustainability benchmarks by consuming 81% less SSD energy per 1 TB transferred than other SSD offerings with NVIDIA Magnum IO GDS and up to 43% lower SSD power in GNN training with BaM.

Micron 9550 delivers world-class AI workload performance and power efficiency:
Compared with other industry offerings, the 9550 SSD delivers up to 34% higher throughput for NVIDIA Magnum IO GPUDirect (GDS) and up to 33% faster workload completion times in graph neural network (GNN) training with Big Accelerator Memory (BaM). The Micron 9550 SSD saves energy and sets new sustainability benchmarks by consuming 81% less SSD energy per 1 TB transferred than other SSD offerings with NVIDIA Magnum IO GDS and up to 43% lower SSD power in GNN training with BaM.


Meta Shows Open-Architecture NVIDIA "Blackwell" GB200 System for Data Center
During the Open Compute Project (OCP) Summit 2024, Meta, one of the prime members of the OCP project, showed its NVIDIA "Blackwell" GB200 systems for its massive data centers. We previously covered Microsoft's Azure server rack with GB200 GPUs featuring one-third of the rack space for computing and two-thirds for cooling. A few days later, Google showed off its smaller GB200 system, and today, Meta is showing off its GB200 system—the smallest of the bunch. To train a dense transformer large language model with 405B parameters and a context window of up to 128k tokens, like the Llama 3.1 405B, Meta must redesign its data center infrastructure to run a distributed training job on two 24,000 GPU clusters. That is 48,000 GPUs used for training a single AI model.
Called "Catalina," it is built on the NVIDIA Blackwell platform, emphasizing modularity and adaptability while incorporating the latest NVIDIA GB200 Grace Blackwell Superchip. To address the escalating power requirements of GPUs, Catalina introduces the Orv3, a high-power rack capable of delivering up to 140kW. The comprehensive liquid-cooled setup encompasses a power shelf supporting various components, including a compute tray, switch tray, the Orv3 HPR, Wedge 400 fabric switch with 12.8 Tbps switching capacity, management switch, battery backup, and a rack management controller. Interestingly, Meta also upgraded its "Grand Teton" system for internal usage, such as deep learning recommendation models (DLRMs) and content understanding with AMD Instinct MI300X. Those are used to inference internal models, and MI300X appears to provide the best performance per Dollar for inference. According to Meta, the computational demand stemming from AI will continue to increase exponentially, so more NVIDIA and AMD GPUs is needed, and we can't wait to see what the company builds.

Called "Catalina," it is built on the NVIDIA Blackwell platform, emphasizing modularity and adaptability while incorporating the latest NVIDIA GB200 Grace Blackwell Superchip. To address the escalating power requirements of GPUs, Catalina introduces the Orv3, a high-power rack capable of delivering up to 140kW. The comprehensive liquid-cooled setup encompasses a power shelf supporting various components, including a compute tray, switch tray, the Orv3 HPR, Wedge 400 fabric switch with 12.8 Tbps switching capacity, management switch, battery backup, and a rack management controller. Interestingly, Meta also upgraded its "Grand Teton" system for internal usage, such as deep learning recommendation models (DLRMs) and content understanding with AMD Instinct MI300X. Those are used to inference internal models, and MI300X appears to provide the best performance per Dollar for inference. According to Meta, the computational demand stemming from AI will continue to increase exponentially, so more NVIDIA and AMD GPUs is needed, and we can't wait to see what the company builds.


NVIDIA Fine-Tunes Llama3.1 Model to Beat GPT-4o and Claude 3.5 Sonnet with Only 70 Billion Parameters
NVIDIA has officially released its Llama-3.1-Nemotron-70B-Instruct model. Based on META's Llama3.1 70B, the Nemotron model is a large language model customized by NVIDIA in order to improve the helpfulness of LLM-generated responses. NVIDIA uses fine-tuning structured data to steer the model and allow it to generate more helpful responses. With only 70 billion parameters, the model is punching far above its weight class. The company claims that the model is beating the current top models from leading labs like OpenAI's GPT-4o and Anthropic's Claude 3.5 Sonnet, which are the current leaders across AI benchmarks. In evaluations such as Arena Hard, the NVIDIA Llama3.1 Nemotron 70B is scoring 85 points, while GPT-4o and Sonnet 3.5 score 79.3 and 79.2, respectively. Other benchmarks like AlpacaEval and MT-Bench spot NVIDIA also hold the top spot, with 57.6 and 8.98 scores earned. Claude and GPT reach 52.4 / 8.81 and 57.5 / 8.74, just below Nemotron.
This language model underwent training using reinforcement learning from human feedback (RLHF), specifically employing the REINFORCE algorithm. The process involved a reward model based on a large language model architecture and custom preference prompts designed to guide the model's behavior. The training began with a pre-existing instruction-tuned language model as the starting point. It was trained on Llama-3.1-Nemotron-70B-Reward and HelpSteer2-Preference prompts on a Llama-3.1-70B-Instruct model as the initial policy. Running the model locally requires either four 40 GB or two 80 GB VRAM GPUs and 150 GB of free disk space. We managed to take it for a spin on NVIDIA's website to say hello to TechPowerUp readers. The model also passes the infamous "strawberry" test, where it has to count the number of specific letters in a word, however, it appears that it was part of the fine-tuning data as it fails the next test, shown in the image below.



This language model underwent training using reinforcement learning from human feedback (RLHF), specifically employing the REINFORCE algorithm. The process involved a reward model based on a large language model architecture and custom preference prompts designed to guide the model's behavior. The training began with a pre-existing instruction-tuned language model as the starting point. It was trained on Llama-3.1-Nemotron-70B-Reward and HelpSteer2-Preference prompts on a Llama-3.1-70B-Instruct model as the initial policy. Running the model locally requires either four 40 GB or two 80 GB VRAM GPUs and 150 GB of free disk space. We managed to take it for a spin on NVIDIA's website to say hello to TechPowerUp readers. The model also passes the infamous "strawberry" test, where it has to count the number of specific letters in a word, however, it appears that it was part of the fine-tuning data as it fails the next test, shown in the image below.




Google Shows Production NVIDIA "Blackwell" GB200 NVL System for Cloud
Last week, we got a preview of Microsoft's Azure production-ready NVIDIA "Blackwell" GB200 system, showing that only a third of the rack that goes in the data center is actually holding the compute elements, with the other two-thirds holding the cooling compartment to cool down the immense heat output from tens of GB200 GPUs. Today, Google is showing off a part of its own infrastructure ahead of the Google Cloud App Dev & Infrastructure Summit, taking place on October 30, digitally as an event. Shown below are two racks standing side by side, connecting NVIDIA "Blackwell" GB200 NVL cards with the rest of the Google infrastructure. Unlike Microsoft Azure, Google Cloud uses a different data center design in its facilities.
There is one rack with power distribution units, networking switches, and cooling distribution units, all connected to the compute rack, which houses power supplies, GPUs, and CPU servers. Networking equipment is present, and it connects to Google's "global" data center network, which is Google's own data center fabric. We are not sure what is the fabric connection of choice between these racks; as for optimal performance, NVIDIA recommends InfiniBand (Mellanox acquisition). However, given that Google's infrastructure is set up differently, there may be Ethernet switches present. Interestingly, Google's design of GB200 racks differs from Azure's, as it uses additional rack space to distribute the coolant to its local heat exchangers, i.e., coolers. We are curious to see if Google releases more information on infrastructure, as it has been known as the infrastructure king because of its ability to scale and keep everything organized.
There is one rack with power distribution units, networking switches, and cooling distribution units, all connected to the compute rack, which houses power supplies, GPUs, and CPU servers. Networking equipment is present, and it connects to Google's "global" data center network, which is Google's own data center fabric. We are not sure what is the fabric connection of choice between these racks; as for optimal performance, NVIDIA recommends InfiniBand (Mellanox acquisition). However, given that Google's infrastructure is set up differently, there may be Ethernet switches present. Interestingly, Google's design of GB200 racks differs from Azure's, as it uses additional rack space to distribute the coolant to its local heat exchangers, i.e., coolers. We are curious to see if Google releases more information on infrastructure, as it has been known as the infrastructure king because of its ability to scale and keep everything organized.

Supermicro's Liquid-Cooled SuperClusters for AI Data Centers Powered by NVIDIA GB200 NVL72 and NVIDIA HGX B200 Systems
Supermicro, Inc., a Total IT Solution Provider for AI, Cloud, Storage, and 5G/Edge, is accelerating the industry's transition to liquid-cooled data centers with the NVIDIA Blackwell platform to deliver a new paradigm of energy-efficiency for the rapidly heightened energy demand of new AI infrastructures. Supermicro's industry-leading end-to-end liquid-cooling solutions are powered by the NVIDIA GB200 NVL72 platform for exascale computing in a single rack and have started sampling to select customers for full-scale production in late Q4. In addition, the recently announced Supermicro X14 and H14 4U liquid-cooled systems and 10U air-cooled systems are production-ready for the NVIDIA HGX B200 8-GPU system.
"We're driving the future of sustainable AI computing, and our liquid-cooled AI solutions are rapidly being adopted by some of the most ambitious AI Infrastructure projects in the world with over 2000 liquid-cooled racks shipped since June 2024," said Charles Liang, president and CEO of Supermicro. "Supermicro's end-to-end liquid-cooling solution, with the NVIDIA Blackwell platform, unlocks the computational power, cost-effectiveness, and energy-efficiency of the next generation of GPUs, such as those that are part of the NVIDIA GB200 NVL72, an exascale computer contained in a single rack. Supermicro's extensive experience in deploying liquid-cooled AI infrastructure, along with comprehensive on-site services, management software, and global manufacturing capacity, provides customers a distinct advantage in transforming data centers with the most powerful and sustainable AI solutions."
"We're driving the future of sustainable AI computing, and our liquid-cooled AI solutions are rapidly being adopted by some of the most ambitious AI Infrastructure projects in the world with over 2000 liquid-cooled racks shipped since June 2024," said Charles Liang, president and CEO of Supermicro. "Supermicro's end-to-end liquid-cooling solution, with the NVIDIA Blackwell platform, unlocks the computational power, cost-effectiveness, and energy-efficiency of the next generation of GPUs, such as those that are part of the NVIDIA GB200 NVL72, an exascale computer contained in a single rack. Supermicro's extensive experience in deploying liquid-cooled AI infrastructure, along with comprehensive on-site services, management software, and global manufacturing capacity, provides customers a distinct advantage in transforming data centers with the most powerful and sustainable AI solutions."

Supermicro Adds New Petascale JBOF All-Flash Storage Solution Integrating NVIDIA BlueField-3 DPU for AI Data Pipeline Acceleration
Supermicro, Inc., a Total IT Solution Provider for AI, Cloud, Storage, and 5G/Edge, is launching a new optimized storage system for high performance AI training, inference and HPC workloads. This JBOF (Just a Bunch of Flash) system utilizes up to four NVIDIA BlueField-3 data processing units (DPUs) in a 2U form factor to run software-defined storage workloads. Each BlueField-3 DPU features 400 Gb Ethernet or InfiniBand networking and hardware acceleration for high computation storage and networking workloads such as encryption, compression and erasure coding, as well as AI storage expansion. The state-of-the-art, dual port JBOF architecture enables active-active clustering ensuring high availability for scale up mission critical storage applications as well as scale-out storage such as object storage and parallel file systems.
"Supermicro's new high performance JBOF Storage System is designed using our Building Block approach which enables support for either E3.S or U.2 form-factor SSDs and the latest PCIe Gen 5 connectivity for the SSDs and the DPU networking and storage platform," said Charles Liang, president and CEO of Supermicro. "Supermicro's system design supports 24 or 36 SSD's enabling up to 1.105PB of raw capacity using 30.71 TB SSDs. Our balanced network and storage I/O design can saturate the full 400 Gb/s BlueField-3 line-rate realizing more than 250 GB/s bandwidth of the Gen 5 SSDs."



"Supermicro's new high performance JBOF Storage System is designed using our Building Block approach which enables support for either E3.S or U.2 form-factor SSDs and the latest PCIe Gen 5 connectivity for the SSDs and the DPU networking and storage platform," said Charles Liang, president and CEO of Supermicro. "Supermicro's system design supports 24 or 36 SSD's enabling up to 1.105PB of raw capacity using 30.71 TB SSDs. Our balanced network and storage I/O design can saturate the full 400 Gb/s BlueField-3 line-rate realizing more than 250 GB/s bandwidth of the Gen 5 SSDs."




NVIDIA Contributes Blackwell Platform Design to Open Hardware Ecosystem, Accelerating AI Infrastructure Innovation
To drive the development of open, efficient and scalable data center technologies, NVIDIA today announced that it has contributed foundational elements of its NVIDIA Blackwell accelerated computing platform design to the Open Compute Project (OCP) and broadened NVIDIA Spectrum-X support for OCP standards.
At this year's OCP Global Summit, NVIDIA will be sharing key portions of the NVIDIA GB200 NVL72 system electro-mechanical design with the OCP community — including the rack architecture, compute and switch tray mechanicals, liquid-cooling and thermal environment specifications, and NVIDIA NVLink cable cartridge volumetrics — to support higher compute density and networking bandwidth.
At this year's OCP Global Summit, NVIDIA will be sharing key portions of the NVIDIA GB200 NVL72 system electro-mechanical design with the OCP community — including the rack architecture, compute and switch tray mechanicals, liquid-cooling and thermal environment specifications, and NVIDIA NVLink cable cartridge volumetrics — to support higher compute density and networking bandwidth.

Apr 15th, 2025 09:10 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Thermaltake riing plus 12 rgb and other rgb fans. (7)
- Overclocking Micron F-die RAM (6)
- RX 9000 series GPU Owners Club (320)
- SK hynix A-Die (Overclocking thread) only for RYZEN AM5 users (36)
- Lian Li O11 Dynamic XL ROG. (18)
- DTS DCH Driver for Realtek HDA [DTS:X APO4 + DTS Interactive] (2136)
- Whats your favourite Linux Distro? (226)
- Need some help with vbios flashing (4)
- Asus ZenWifi BE14000 3pk or Orbi 770 3pk (2)
- The VHS to PC struggle (26)
Popular Reviews
- G.SKILL Trident Z5 NEO RGB DDR5-6000 32 GB CL26 Review - AMD EXPO
- ASUS GeForce RTX 5080 TUF OC Review
- Thermaltake TR100 Review
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- TerraMaster F8 SSD Plus Review - Compact and quiet
- DAREU A950 Wing Review
- Sapphire Radeon RX 9070 XT Pulse Review
- Zotac GeForce RTX 5070 Ti Amp Extreme Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (124)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)
- NVIDIA Pushes GeForce RTX 5060 Ti Launch to Mid-April, RTX 5060 to May (77)