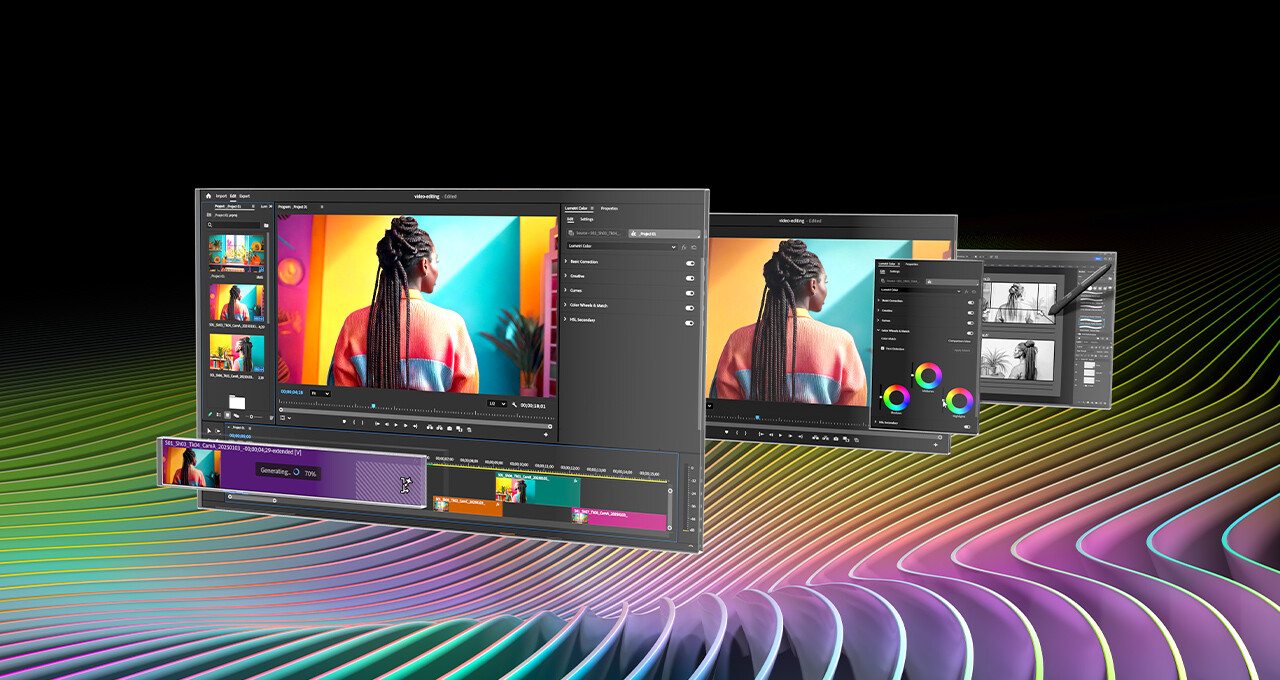
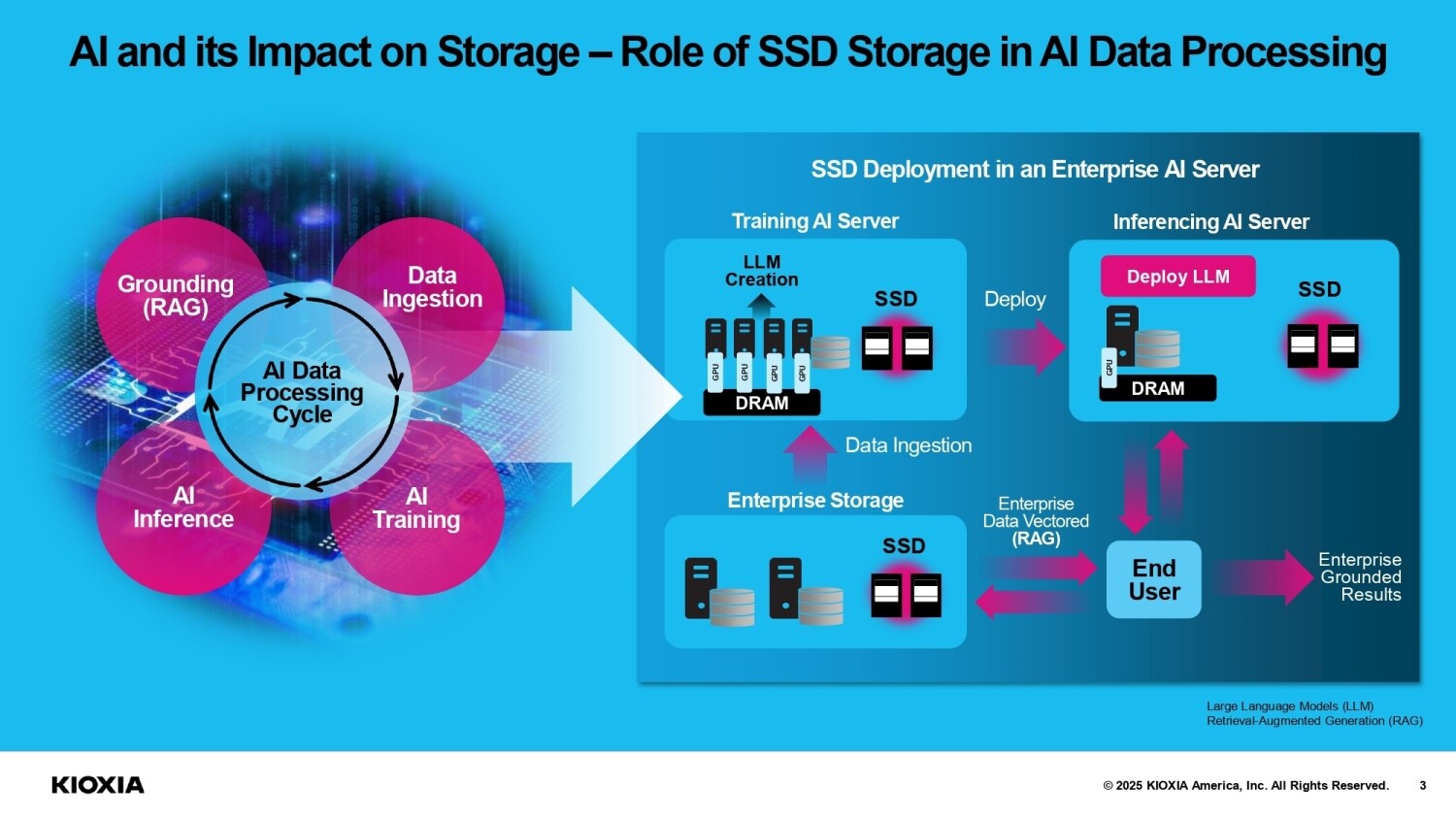
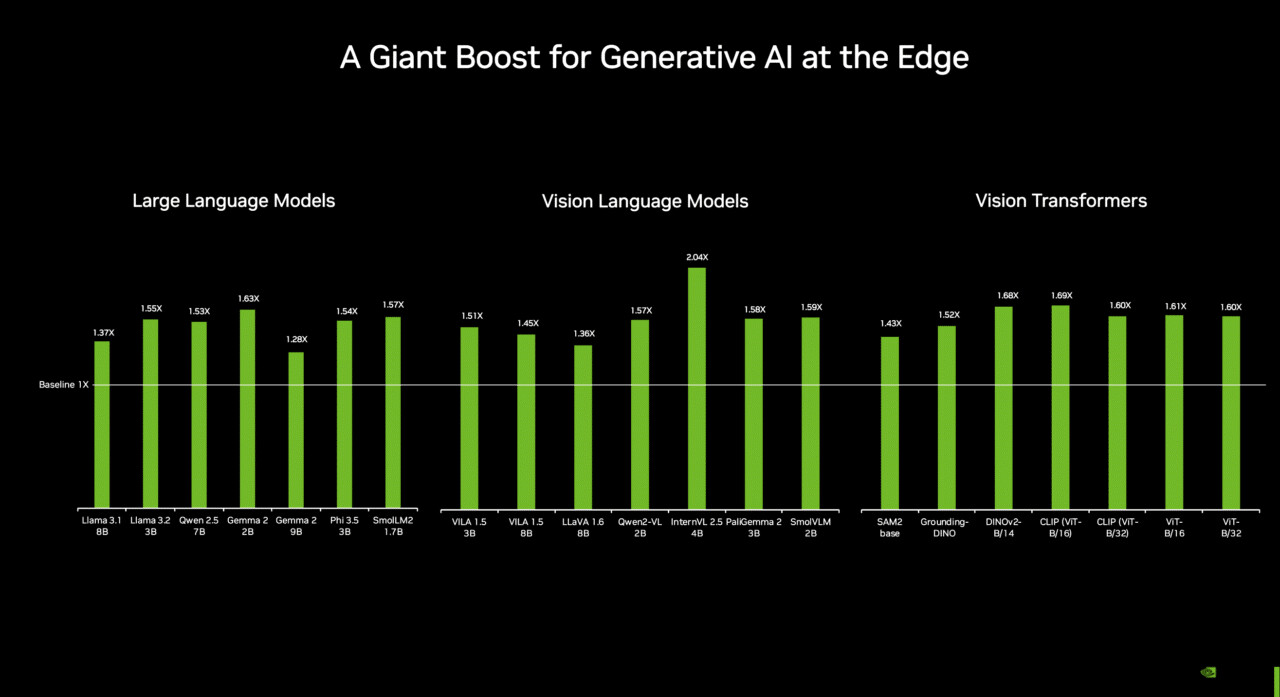
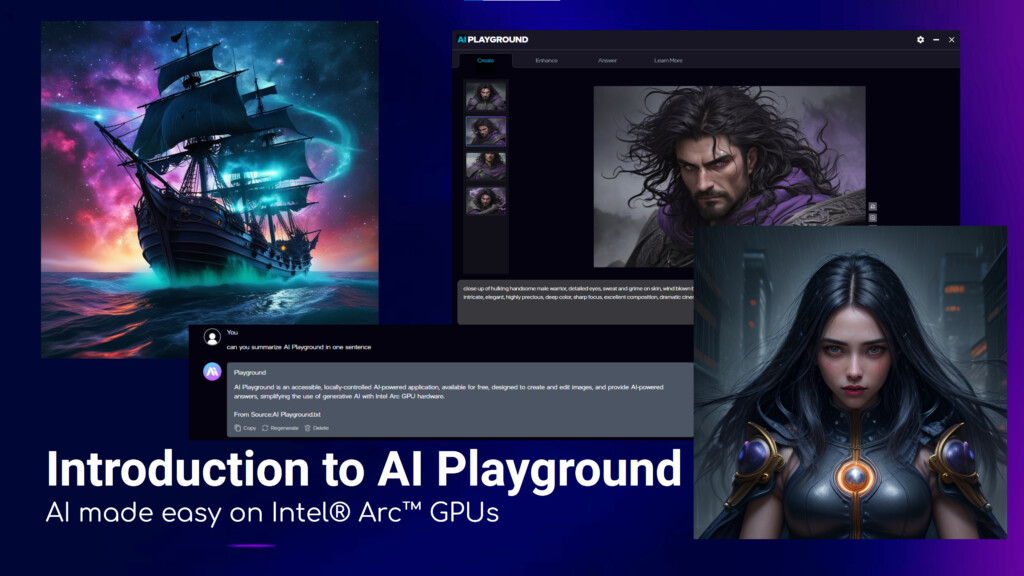
Qualcomm and IBM Scale Enterprise-grade Generative AI from Edge to Cloud
Ahead of Mobile World Congress 2025, Qualcomm Technologies, Inc. and IBM (NYSE: IBM) announced an expanded collaboration to drive enterprise-grade generative artificial intelligence (AI) solutions across edge and cloud devices designed to enable increased immediacy, privacy, reliability, personalization, and reduced cost and energy consumption. Through this collaboration, the companies plan to integrate watsonx.governance for generative AI solutions powered by Qualcomm Technologies' platforms, and enable support for IBM's Granite models through the Qualcomm AI Inference Suite and Qualcomm AI Hub.
"At Qualcomm Technologies, we are excited to join forces with IBM to deliver cutting-edge, enterprise-grade generative AI solutions for devices across the edge and cloud," said Durga Malladi, senior vice president and general manager, technology planning and edge solutions, Qualcomm Technologies, Inc. "This collaboration enables businesses to deploy AI solutions that are not only fast and personalized but also come with robust governance, monitoring, and decision-making capabilities, with the ability to enhance the overall reliability of AI from edge to cloud."
"At Qualcomm Technologies, we are excited to join forces with IBM to deliver cutting-edge, enterprise-grade generative AI solutions for devices across the edge and cloud," said Durga Malladi, senior vice president and general manager, technology planning and edge solutions, Qualcomm Technologies, Inc. "This collaboration enables businesses to deploy AI solutions that are not only fast and personalized but also come with robust governance, monitoring, and decision-making capabilities, with the ability to enhance the overall reliability of AI from edge to cloud."