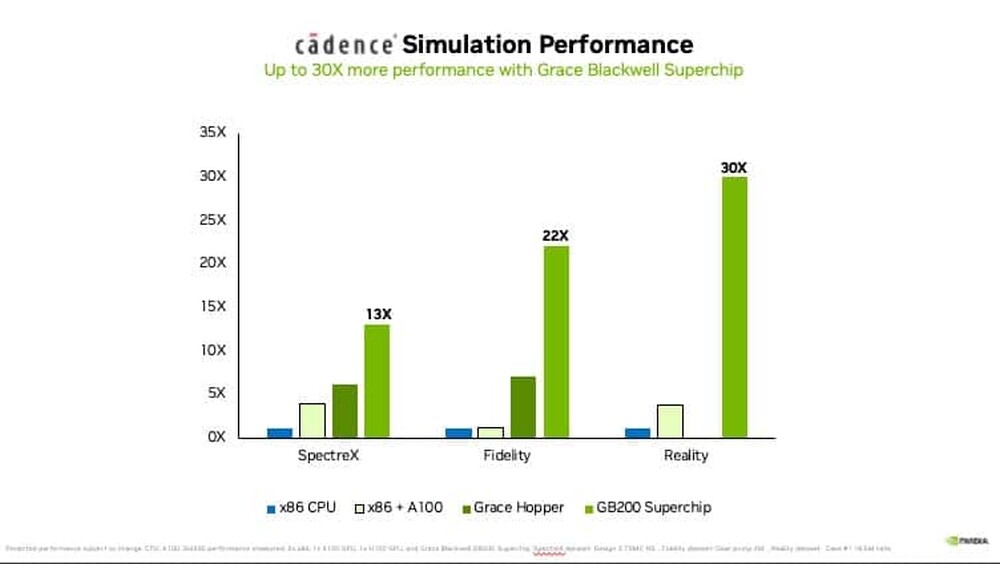
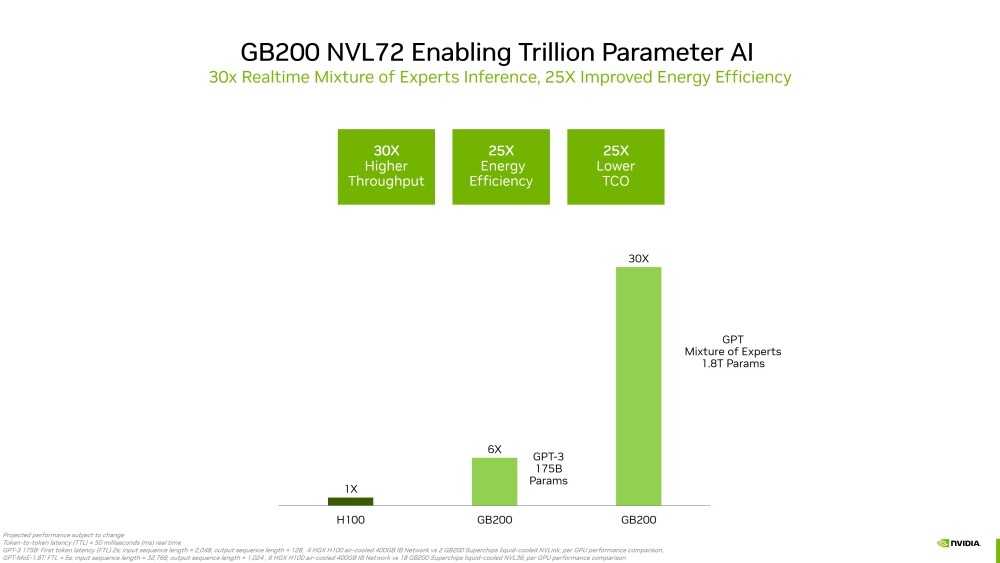
Supermicro Adds Portfolio for Next Wave of AI with NVIDIA Blackwell Ultra Solutions
Supermicro, Inc., a Total IT Solution Provider for AI, Cloud, Storage, and 5G/Edge, is announcing new systems and rack solutions powered by the NVIDIA's Blackwell Ultra platform, featuring the NVIDIA HGX B300 NVL16 and NVIDIA GB300 NVL72 platforms. Supermicro and NVIDIA's new AI solutions strengthen leadership in AI by delivering breakthrough performance for the most compute-intensive AI workloads, including AI reasoning, agentic AI, and video inference applications.
"At Supermicro, we are excited to continue our long-standing partnership with NVIDIA to bring the latest AI technology to market with the NVIDIA Blackwell Ultra Platforms," said Charles Liang, president and CEO, Supermicro. "Our Data Center Building Block Solutions approach has streamlined the development of new air and liquid-cooled systems, optimized to the thermals and internal topology of the NVIDIA HGX B300 NVL16 and GB300 NVL72. Our advanced liquid-cooling solution delivers exceptional thermal efficiency, operating with 40℃ warm water in our 8-node rack configuration, or 35℃ warm water in double-density 16-node rack configuration, leveraging our latest CDUs. This innovative solution reduces power consumption by up to 40% while conserving water resources, providing both environmental and operational cost benefits for enterprise data centers."

"At Supermicro, we are excited to continue our long-standing partnership with NVIDIA to bring the latest AI technology to market with the NVIDIA Blackwell Ultra Platforms," said Charles Liang, president and CEO, Supermicro. "Our Data Center Building Block Solutions approach has streamlined the development of new air and liquid-cooled systems, optimized to the thermals and internal topology of the NVIDIA HGX B300 NVL16 and GB300 NVL72. Our advanced liquid-cooling solution delivers exceptional thermal efficiency, operating with 40℃ warm water in our 8-node rack configuration, or 35℃ warm water in double-density 16-node rack configuration, leveraging our latest CDUs. This innovative solution reduces power consumption by up to 40% while conserving water resources, providing both environmental and operational cost benefits for enterprise data centers."