U.S. Government Restricts Export of AI Compute GPUs to China and Russia (Affects NVIDIA, AMD, and Others)
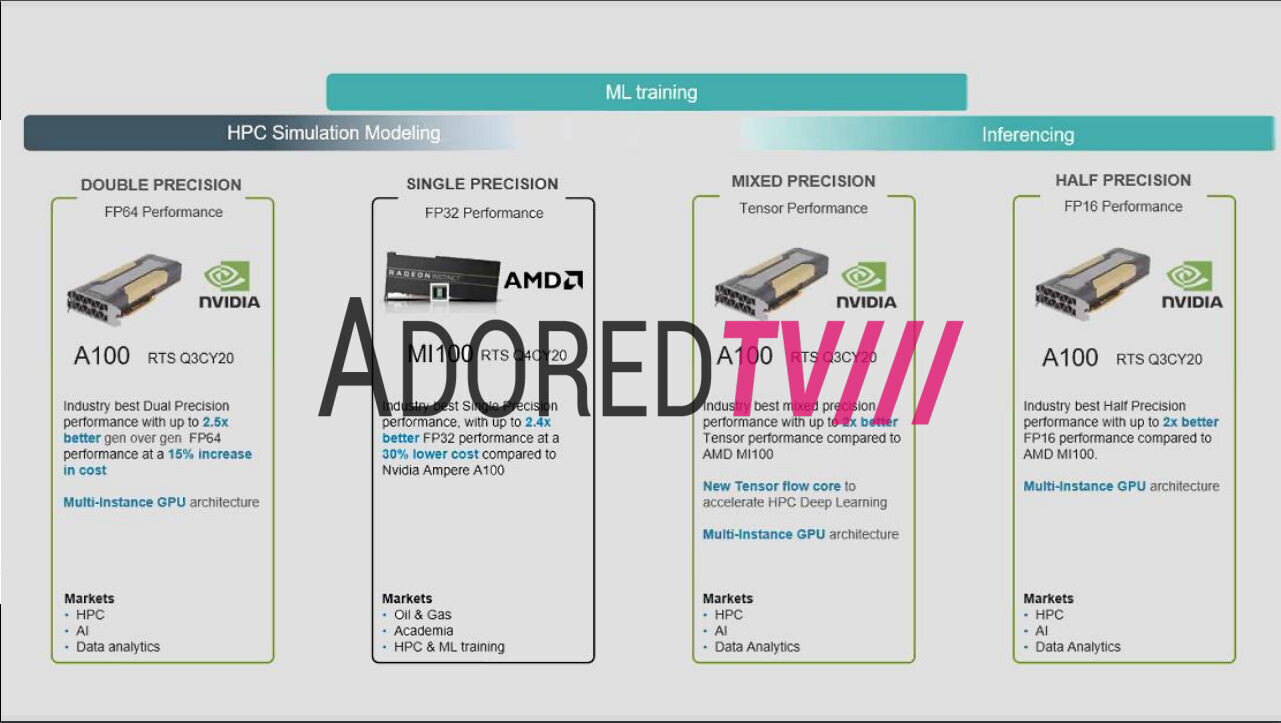
The U.S. Government has imposed restrictions on the export of AI compute GPUs to China and Russia without Government-authorization in the form of a waiver or a license. This impacts sales of products such as the NVIDIA A100, H100; AMD Instinct MI100, MI200; and the upcoming Intel "Ponte Vecchio," among others. The restrictions came to light when NVIDIA on Wednesday disclosed that it has received a Government notification about licensing requirements for export of its AI compute GPUs to Russia and China.
The notification doesn't specify the A100 and H100 by name, but defines AI inference performance thresholds to meet the licensing requirements. The Government wouldn't single out NVIDIA, and so competing products such as the AMD MI200 and the upcoming Intel Xe-HP "Ponte Vecchio" would fall within these restrictions. For NVIDIA, this is impacts $400 million in TAM, unless the Government licenses specific Russian and Chinese customers to purchase these GPUs from NVIDIA. Such trade restrictions usually come with riders to prevent resale or transshipment by companies outside the restricted region (eg: a distributor in a third waived country importing these chips in bulk and reselling them to these countries).
The notification doesn't specify the A100 and H100 by name, but defines AI inference performance thresholds to meet the licensing requirements. The Government wouldn't single out NVIDIA, and so competing products such as the AMD MI200 and the upcoming Intel Xe-HP "Ponte Vecchio" would fall within these restrictions. For NVIDIA, this is impacts $400 million in TAM, unless the Government licenses specific Russian and Chinese customers to purchase these GPUs from NVIDIA. Such trade restrictions usually come with riders to prevent resale or transshipment by companies outside the restricted region (eg: a distributor in a third waived country importing these chips in bulk and reselling them to these countries).