Thursday, April 23rd 2020

AMD's Next-Generation Radeon Instinct "Arcturus" Test Board Features 120 CUs
AMD is preparing to launch its next-generation of Radeon Instinct GPUs based on the new CDNA architecture designed for enterprise deployments. Thanks to the popular hardware leaker _rogame (@_rogame) we have some information about the configuration of the upcoming Radeon Instinct MI100 "Arcturus" server GPU. Previously, we obtained the BIOS of the Arcturus GPU that showed a configuration of 128 Compute Units (CUs), which resulted in 8,192 of CDNA cores. That configuration had a specific setup of 1334 MHz GPU clock, SoC frequency of 1091 MHz, and memory speed of 1000 MHz. However, there was another GPU test board spotted which featured a bit different specification.
The reported configuration is an Arcturus GPU with 120 CUs, resulting in a CDNA core count of 7,680 cores. These cores are running at frequencies of 878 MHz for the core clock, 750 MHz SoC clock, and a surprising 1200 MHz memory clock. While the SoC and core clocks are lower than the previous report, along with the CU count, the memory clock is up by 200 MHz. It is important to note that this is just a test board/variation of the MI100, and actual frequencies should be different.

Source:
@_rogame (Twitter)
The reported configuration is an Arcturus GPU with 120 CUs, resulting in a CDNA core count of 7,680 cores. These cores are running at frequencies of 878 MHz for the core clock, 750 MHz SoC clock, and a surprising 1200 MHz memory clock. While the SoC and core clocks are lower than the previous report, along with the CU count, the memory clock is up by 200 MHz. It is important to note that this is just a test board/variation of the MI100, and actual frequencies should be different.
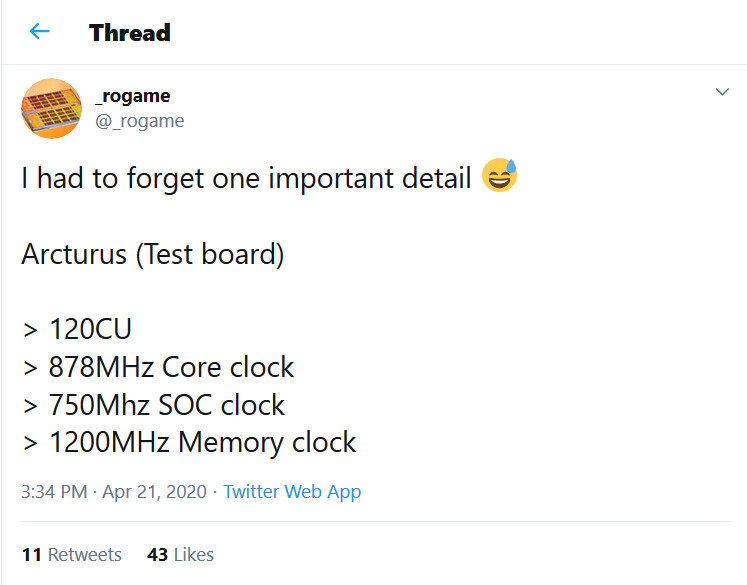

23 Comments on AMD's Next-Generation Radeon Instinct "Arcturus" Test Board Features 120 CUs
this is a datacenter only card.
Higher clockspeeds with fewer CUs is the route they will take (up to 64) as they will also add accelerator engines inside RDNA2 GPUs at the expense of CUs like Nvidia did with Tensor Cores. Fixed function accelerators are more important to performance rather than just more CUs after a certain point.
The 2020 drivers were initially terrible. They're very stable now, though the Radeon Software control panel still isn't 100% - why they feel the need to remove or rejig half its content with each Adrenaline release, then re-add it, I will never understand.You could buy one. But it probably won't be much good to you. It's not like Radeon VII or Titan Volta .. there's no raster engine. These are dedicated HPC / ML cards. Not rendering / graphics acceleration.
It will be interesting to see what form future Fire or Pro cards take from AMD.RDNA1 could have had more. This was confirmed almost a year ago at Computex. Changes in RDNA (& now CDNA) meant that configurations above 64 CUs would no longer suffer severe bottlenecks.
A good ecosystem is HW+SW. Get your shit together RTG on the software.
I also asked another person about his own experience. I am not even sure he has a running Radeon card to report about.
Zero issues. Best bang-for-buck at the moment.
My previous card was a GTX960 which was a bit flaky at first - but went on to give faultless service for 9 years.
I went the on the AMD forums to see any potential problems before I bought the rx5700, and most of the problems were down to Windows 10 silently updating the drivers
Or plain stupidity and user error.
It sounds like you've bought into Mark Cerny's stupid "faster clocks outperforms more CUs!" marketing nonsense - a statement disproved by any OC GPU benchmark (performance doesn't even increase linearly with clocks, while Cerny's statement would need performance to increase by more than clock speeds to be true). Look at how an 80W 2080 Max-Q performs compared to a 2060 (not max-Q) mobile - the 2080 is way faster at much lower clocks.
Vega scales really bad with higher shader count after a certain point.
To run a 80CU Vega (14nm) GPU at reasonable power levels you probably have to clock it at around 1.1 to 1.15GHz range which is just stupid and unbalanced for a gaming GPU, and the worse part is that instead of a 480~ mm squared die you have a much more expensive to make 600~ mm squared die. (and at the end of the day all you got was maybe 5-10% better gaming performance)
CU count was not the reason why Vega lagged so much behind Nvidia, It was purely down to efficiency deficit.
Just look at how good Radeon VII with fewer shaders performs in comparison to the Vega 64, that extra memory bandwidth helps of course but the extra 300MHz higher clock is the primary reason.
I've experienced the same issues when I had a HD 7870 "XT" (1536 shaders) Tahiti LE back in 2013. They eventually got better over time (addressing bugs) and had further improvements in some games ("Fine Wine").
I have no problems with the earlier 20.x releases, except for Enhanced Sync which AMD keeps messing up for some reason. However I've foregone the mainline release for the more stable Radeon Pro drivers (20.Q1.2) since I don't have to deal with any of the extra bloat that Adrenalin installs (which I've been reporting to keep separate during install).
Like I said, Adrenalin 2020 is not fine yet. Since you're running on GCN5 hardware, you shouldn't be experiencing any major issues compared to some of the Navi owners.Are you talking about me? Please review my System Specs if you're in doubt. I even have a "unique" configuration.
This is part because of its design with many compromises - it was designed for higher throughput which is good for pure number crunching in high performance computing loads but games unfortunately don't care too much about it.
Now this is of course not to say that Vega doesn't also have an architectural efficiency disadvantage to Pascal and Turing - it definitely does - but pushing it way past its efficiency sweet spot just compounded this issue, making it far worse than it might have been.
And of course this would also lead to increased die sizes - but then they would have some actual performance gains when moving to a new node, rather than the outright flop that was the Radeon VII. Now that GPU was never meant for gaming at all, but it nonetheless performs terribly for what it is - a full node shrink and then some over its predecessor. Why? Again, because the architecture didn't allow them to build a wider die, meaning that the only way of increasing performance was pushing clocks as high as they could. Now, the VII has 60 CUs and not 64, that is true, but that is solely down to it being a short-term niche card made for salvaging faulty chips, with all fully enabled dice going to the datacenter/HPC market where this GPU actually had some qualities.
If AMD could have moved past 64 CUs with Vega, that lineup would have been much more competitive in terms of absolute performance. It wouldn't have been cheap, but it would have been better than what we got - and we could have gotten a proper full lineup rather than the two GPUs AMD ended up making. Luckily it looks like this is happening with RDNA 2 now that the 64 CU limit is gone.
So, tl;dr: the 64 CU architectural limit of GCN has been a major problem for AMD GPUs ever since they maxed it out back in 2015 - it left them with no way forward outside of sacrificing efficiency at every turn.
My comment on Performance scaling with higher clocks doesn't have anything to do with what cerny says.
You clearly don't properly understand how GPUs work.
And no, The 80W 2080 Max-Q is nowhere near 50% faster than a Non-MaxQ mobile 2060, where are you getting that from? even if true, a big part of that efficiency difference could be due to binning and using higher quality chips for the higher-end GPU.
Just take a look at how an RX 5700 performs in comparison to the 5700 XT at similar clocks, the 5700 XT ends up being 6% faster while having 11% more shaders.
Another good example is how the 2080Ti with 41% more shaders performs compared the 2080 Super, only 20% faster at 4K.
Performance scaling with higher clocks have always been and will be more linear than performance increase with more shaders in gaming-like workloads. If not, the GTX 1070 with a massive 14CU deficit couldn't match or beat the 980Ti with a similar architecture.
Just do the math:
1070 => 1920 * 1800MHz*2= 6.9 TFLOPS
980Ti => 2816 * 1250MHz*2= 7 TFLOPS
Yet the 1070 performs around 12% better (when comparing reference vs reference, obviously the 980Ti has more OC headroom)
And while I never said that scaling with more shaders is even close to linear, increased shader counts is responsible for the majority of GPU performance uplift over the past decade - far more than clock speeds, which have increased by less than 3x while shader counts have increased by ~8x and total GPU performance by >5x. Any GPU OC exercise will show that performance scaling with clock speed increases is far below linear - often to the tune of half or less than half in terms of perf % increase vs. clock % increase even when also OC'ing memory. The best balance for increasing performance generation over generation is obviously a combination of both, but in the case of Vega AMD couldn't do that, and instead only pushed clocks higher. The lack of shader count increases forced them to push clocks far past the efficiency sweet spot of that arch+node combo, tanking efficiency in an effort to maximize absolute performance - they had nowhere else to go and a competitor with a significant lead in absolute performance, after all.
The same happened again with the VII; clocks were pushed far beyond the efficiency sweet spot as they couldn't increase the CU count (at this point we were looking at a 331 mm2 die, so they could easily have added 10-20 CUs if they had the ability and stayed within a reasonable die size). Now, the VII has 60 CUs active and not 64, but that is down to nothing more than this GPU being a PR move with likely zero margins utilizing salvaged dice, with all fully enabled Vega 20 dice going to compute accelerators where there was actual money to be made. On the other hand, comparing it with the Vega 56, you have 9.3% more shaders, ~20% higher clock speeds (base - the boost speed difference is larger) and >2x the memory bandwidth, yet it only delivers ~33% more performance. For a severely memory limited arch like Vega, that is a rather poor showing. And again, at the same wattage they could undoubtedly have increased performance more with some more shaders running at a lower speed.
As for AMD saying there was no hard architectural limit of 64 shaders: source, please? Not increasing shader counts at all across three generations and three production nodes while the competition increases theirs by 55% is proof enough that AMD couldn't increase theirs without moving away from GCN.