Apr 6th, 2025 21:46 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- No idea how many watts this USB-C port will supply? (2)
- I dont think the HT-Omega sound card company has anyone running it anymore. Cant get responses from customer service for last 2 years. (2)
- A dozen drivers for HD4670, and which do I choose? (10)
- What's your latest tech purchase? (23486)
- gpu heirarchy/performance/benchmarks- whos lying? (38)
- What are you playing? (23349)
- i7-13700HX capped at 25 watts (13)
- 9070XT or 7900XT (39)
- Weird games on rtx 3070ti (1)
- RX 9000 series GPU Owners Club (198)
Popular Reviews
- ASUS Prime X870-P Wi-Fi Review
- UPERFECT UStation Delta Max Review - Two Screens In One
- PowerColor Radeon RX 9070 Hellhound Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Corsair RM750x Shift 750 W Review
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- DDR5 CUDIMM Explained & Benched - The New Memory Standard
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- AMD Ryzen 9 9950X3D Review - Great for Gaming and Productivity
Controversial News Posts
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (134)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (97)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (92)
News Posts matching #ML
Return to Keyword Browsing
Google Cloud and NVIDIA Expand Partnership to Advance AI Computing, Software and Services
Google Cloud Next—Google Cloud and NVIDIA today announced new AI infrastructure and software for customers to build and deploy massive models for generative AI and speed data science workloads.
In a fireside chat at Google Cloud Next, Google Cloud CEO Thomas Kurian and NVIDIA founder and CEO Jensen Huang discussed how the partnership is bringing end-to-end machine learning services to some of the largest AI customers in the world—including by making it easy to run AI supercomputers with Google Cloud offerings built on NVIDIA technologies. The new hardware and software integrations utilize the same NVIDIA technologies employed over the past two years by Google DeepMind and Google research teams.
In a fireside chat at Google Cloud Next, Google Cloud CEO Thomas Kurian and NVIDIA founder and CEO Jensen Huang discussed how the partnership is bringing end-to-end machine learning services to some of the largest AI customers in the world—including by making it easy to run AI supercomputers with Google Cloud offerings built on NVIDIA technologies. The new hardware and software integrations utilize the same NVIDIA technologies employed over the past two years by Google DeepMind and Google research teams.

Tachyum Achieves 192-Core Chip After Switch to New EDA Tools
Tachyum today announced that new EDA tools, utilized during the physical design phase of the Prodigy Universal Processor, have allowed the company to achieve significantly better results with chip specifications than previously anticipated, after the successful change in physical design tools - including an increase in the number of Prodigy cores to 192.
After RTL design coding, Tachyum began work on completing the physical design (the actual placement of transistors and wires) for Prodigy. After the Prodigy design team had to replace IPs, it also had to replace RTL simulation and physical design tools. Armed with a new set of EDA tools, Tachyum was able to optimize settings and options that increased the number of cores by 50 percent, and SERDES from 64 to 96 on each chip. Die size grew minimally, from 500mm2 to 600mm2 to accommodate improved physical capabilities. While Tachyum could add more of its very efficient cores and still fit into the 858mm2 reticle limit, these cores would be memory bandwidth limited, even with 16 DDR5 controllers running in excess of 7200MT/s. Tachyum cores have much higher performance than any other processor cores.
After RTL design coding, Tachyum began work on completing the physical design (the actual placement of transistors and wires) for Prodigy. After the Prodigy design team had to replace IPs, it also had to replace RTL simulation and physical design tools. Armed with a new set of EDA tools, Tachyum was able to optimize settings and options that increased the number of cores by 50 percent, and SERDES from 64 to 96 on each chip. Die size grew minimally, from 500mm2 to 600mm2 to accommodate improved physical capabilities. While Tachyum could add more of its very efficient cores and still fit into the 858mm2 reticle limit, these cores would be memory bandwidth limited, even with 16 DDR5 controllers running in excess of 7200MT/s. Tachyum cores have much higher performance than any other processor cores.

Lightelligence Introduces Optical Interconnect for Composable Data Center Architectures
Lightelligence, the global leader in photonic computing and connectivity systems, today announced Photowave, the first optical communications hardware designed for PCIe and Compute Express Link (CXL) connectivity, unleashing next-generation workload efficiency.
Photowave, an Optical Networking (oNET) transceiver leveraging the significant latency and energy efficiency of photonics technology, empowers data center managers to scale resources within or across server racks. The first public demonstration of Photowave will be at Flash Memory Summit today through Thursday, August 10, in Santa Clara, Calif.
Photowave, an Optical Networking (oNET) transceiver leveraging the significant latency and energy efficiency of photonics technology, empowers data center managers to scale resources within or across server racks. The first public demonstration of Photowave will be at Flash Memory Summit today through Thursday, August 10, in Santa Clara, Calif.

Supermicro Expands AMD Product Lines with New Servers and New Processors Optimized for Cloud Native Infrastructure
Supermicro, Inc., a Total IT Solution Provider for Cloud, AI/ML, Storage, and 5G/Edge, is announcing that its entire line of H13 AMD based-systems is now available with support for 4th Gen AMD EPYC processors, based on "Zen 4c" architecture, and 4th Gen AMD EPYC processors with AMD 3D V-Cache technology. Supermicro servers powered by 4th Gen AMD EPYC processors for cloud-native computing, with leading thread density and 128 cores per socket, deliver impressive rack density and scalable performance with energy efficiency to deploy cloud native workloads in more consolidated infrastructure. These systems are targeted for cloud operators to meet the ever-growing demands of user sessions and deliver AI-enabled new services. Servers featuring AMD 3D V-Cache technology excel in running technical applications in FEA, CFD, and EDA. The large Level 3 cache enables these types of applications to run faster than ever before. Over 50 world record benchmarks have been set with AMD EPYC processors over the past few years.
"Supermicro continues to push the boundary of our product lines to meet customers' requirements. We design and deliver resource-saving, application-optimized servers with rack scale integration for rapid deployments," said Charles Liang, president, and CEO of Supermicro. "With our growing broad portfolio of systems fully optimized for the latest 4th Gen AMD EPYC processors, cloud operators can now achieve extreme density and efficiency for numerous users and cloud-native services even in space-constrained data centers. In addition, our enhanced high performance, multi-socket, multi-node systems address a wide range of technical computing workloads and dramatically reduce time-to-market for manufacturing companies to design, develop, and validate new products leveraging the accelerated performance of memory intensive applications."
"Supermicro continues to push the boundary of our product lines to meet customers' requirements. We design and deliver resource-saving, application-optimized servers with rack scale integration for rapid deployments," said Charles Liang, president, and CEO of Supermicro. "With our growing broad portfolio of systems fully optimized for the latest 4th Gen AMD EPYC processors, cloud operators can now achieve extreme density and efficiency for numerous users and cloud-native services even in space-constrained data centers. In addition, our enhanced high performance, multi-socket, multi-node systems address a wide range of technical computing workloads and dramatically reduce time-to-market for manufacturing companies to design, develop, and validate new products leveraging the accelerated performance of memory intensive applications."


Arm Launches the Cortex-X4, A720 and A520, Immortalis-G715 GPU
Mobile devices touch every aspect of our digital lives. In the palm of your hand is the ability to both create and consume increasingly immersive, AI-accelerated experiences that continue to drive the need for more compute. Arm is at the heart of many of these, bringing unlimited delight, productivity and success to more people than ever. Every year we build foundational platforms designed to meet these increasing compute demands, with a relentless focus on high performance and efficiency. Working closely with our broader ecosystem, we're delivering the performance, efficiency and intelligence needed on every generation of consumer device to expand our digital lifestyles.
Today we are announcing Arm Total Compute Solutions 2023 (TCS23), which will be the platform for mobile computing, offering our best ever premium solution for smartphones. TCS23 delivers a complete package of the latest IP designed and optimized for specific workloads to work seamlessly together as a complete system. This includes a new world-class Arm Immortalis GPU based on our brand-new 5th Generation GPU architecture for ultimate visual experiences, a new cluster of Armv9 CPUs that continue our performance leadership for next-gen artificial intelligence (AI), and new enhancements to deliver more accessible software for the millions of Arm developers.



Today we are announcing Arm Total Compute Solutions 2023 (TCS23), which will be the platform for mobile computing, offering our best ever premium solution for smartphones. TCS23 delivers a complete package of the latest IP designed and optimized for specific workloads to work seamlessly together as a complete system. This includes a new world-class Arm Immortalis GPU based on our brand-new 5th Generation GPU architecture for ultimate visual experiences, a new cluster of Armv9 CPUs that continue our performance leadership for next-gen artificial intelligence (AI), and new enhancements to deliver more accessible software for the millions of Arm developers.





Google Merges its AI Subsidiaries into Google DeepMind
Google has announced that the company is officially merging its subsidiaries focused on artificial intelligence to form a single group. More specifically, Google Brain and DeepMind companies are now joining forces to become a single unit called Google DeepMind. As Google CEO Sundar Pichai notes: "This group, called Google DeepMind, will bring together two leading research groups in the AI field: the Brain team from Google Research, and DeepMind. Their collective accomplishments in AI over the last decade span AlphaGo, Transformers, word2vec, WaveNet, AlphaFold, sequence to sequence models, distillation, deep reinforcement learning, and distributed systems and software frameworks like TensorFlow and JAX for expressing, training and deploying large scale ML models."
As a CEO of this group, Demis Hassabis, a previous CEO of DeepMind, will work together with Jeff Dean, now promoted to Google's Chief Scientist, where he will report to the Sundar. In the spirit of a new role, Jeff Dean will work as a Chief Scientist at Google Research and Google DeepMind, where he will set the goal for AI research at both units. This corporate restructuring will help the two previously separate teams work together on a single plan and help advance AI capabilities faster. We are eager to see the upcoming developments these teams accomplish.
As a CEO of this group, Demis Hassabis, a previous CEO of DeepMind, will work together with Jeff Dean, now promoted to Google's Chief Scientist, where he will report to the Sundar. In the spirit of a new role, Jeff Dean will work as a Chief Scientist at Google Research and Google DeepMind, where he will set the goal for AI research at both units. This corporate restructuring will help the two previously separate teams work together on a single plan and help advance AI capabilities faster. We are eager to see the upcoming developments these teams accomplish.

NVIDIA H100 AI Performance Receives up to 54% Uplift with Optimizations
On Wednesday, the MLCommons team released the MLPerf 3.0 Inference numbers, and there was an exciting submission from NVIDIA. Reportedly, NVIDIA has used software optimization to improve the already staggering performance of its latest H100 GPU by up to 54%. For reference, NVIDIA's H100 GPU first appeared on MLPerf 2.1 back in September of 2022. In just six months, NVIDIA engineers worked on AI optimizations for the MLPerf 3.0 release to find that basic software optimization can catalyze performance increases anywhere from 7-54%. The workloads for measuring the inferencing speed suite included RNN-T speech recognition, 3D U-Net medical imaging, RetinaNet object detection, ResNet-50 object classification, DLRM recommendation, and BERT 99/99.9% natural language processing.
What is interesting is that NVIDIA's submission is a bit modified. There are open and closed categories that vendors have to compete in, where closed is the mathematical equivalent of a neural network. In contrast, the open category is flexible and allows vendors to submit results based on optimizations for their hardware. The closed submission aims to provide an "apples-to-apples" hardware comparison. Given that NVIDIA opted to use the closed category, performance optimization of other vendors such as Intel and Qualcomm are not accounted for here. Still, it is interesting that optimization can lead to a performance increase of up to 54% in NVIDIA's case with its H100 GPU. Another interesting takeaway is that some comparable hardware, like Qualcomm Cloud AI 100, Intel Xeon Platinum 8480+, and NeuChips's ReccAccel N3000, failed to finish all the workloads. This is shown as "X" on the slides made by NVIDIA, stressing the need for proper ML system software support, which is NVIDIA's strength and an extensive marketing claim.


What is interesting is that NVIDIA's submission is a bit modified. There are open and closed categories that vendors have to compete in, where closed is the mathematical equivalent of a neural network. In contrast, the open category is flexible and allows vendors to submit results based on optimizations for their hardware. The closed submission aims to provide an "apples-to-apples" hardware comparison. Given that NVIDIA opted to use the closed category, performance optimization of other vendors such as Intel and Qualcomm are not accounted for here. Still, it is interesting that optimization can lead to a performance increase of up to 54% in NVIDIA's case with its H100 GPU. Another interesting takeaway is that some comparable hardware, like Qualcomm Cloud AI 100, Intel Xeon Platinum 8480+, and NeuChips's ReccAccel N3000, failed to finish all the workloads. This is shown as "X" on the slides made by NVIDIA, stressing the need for proper ML system software support, which is NVIDIA's strength and an extensive marketing claim.

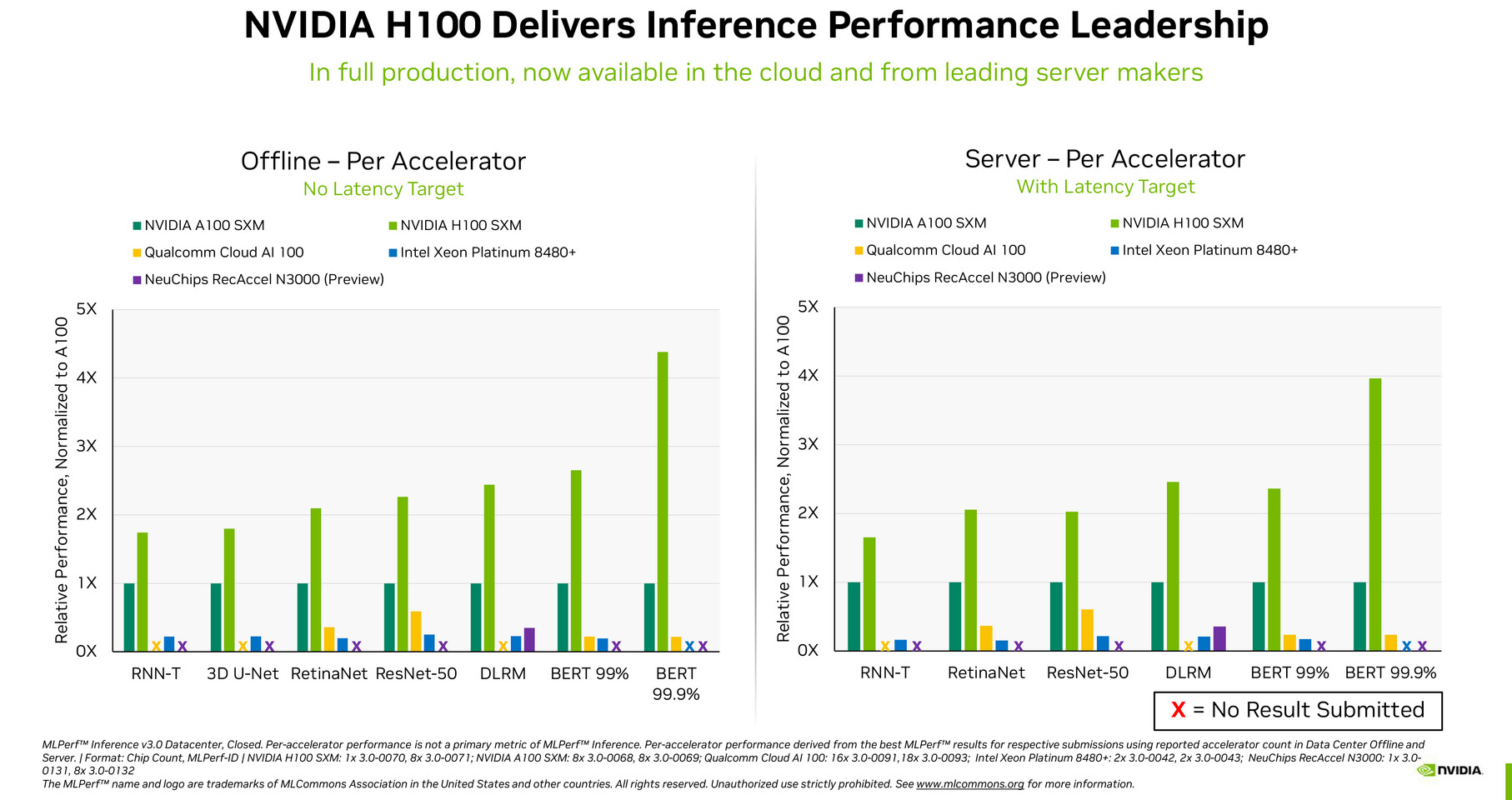

NVIDIA Hopper GPUs Expand Reach as Demand for AI Grows
NVIDIA and key partners today announced the availability of new products and services featuring the NVIDIA H100 Tensor Core GPU—the world's most powerful GPU for AI—to address rapidly growing demand for generative AI training and inference. Oracle Cloud Infrastructure (OCI) announced the limited availability of new OCI Compute bare-metal GPU instances featuring H100 GPUs. Additionally, Amazon Web Services announced its forthcoming EC2 UltraClusters of Amazon EC2 P5 instances, which can scale in size up to 20,000 interconnected H100 GPUs. This follows Microsoft Azure's private preview announcement last week for its H100 virtual machine, ND H100 v5.
Additionally, Meta has now deployed its H100-powered Grand Teton AI supercomputer internally for its AI production and research teams. NVIDIA founder and CEO Jensen Huang announced during his GTC keynote today that NVIDIA DGX H100 AI supercomputers are in full production and will be coming soon to enterprises worldwide.
Additionally, Meta has now deployed its H100-powered Grand Teton AI supercomputer internally for its AI production and research teams. NVIDIA founder and CEO Jensen Huang announced during his GTC keynote today that NVIDIA DGX H100 AI supercomputers are in full production and will be coming soon to enterprises worldwide.

Supermicro Expands Storage Solutions Portfolio for Intensive I/O Workloads with Industry Standard Based All-Flash Servers Utilizing EDSFF E3.S, and E1
Supermicro, Inc., a Total IT Solution Provider for Cloud, AI/ML, Storage, and 5G/Edge, is announcing the latest addition to its revolutionary ultra-high performance, high-density petascale class all-flash NVMe server family. Supermicro systems in this high-performance storage product family will support the next-generation EDSFF form factor, including the E3.S and E1.S devices, in form factors that accommodate 16- and 32 high-performance PCIe Gen 5 NVMe drive bays.
The initial offering of the updated product line will support up to one-half of a petabyte of storage space in a 1U 16 bay rackmount system, followed by a full petabyte of storage space in a 2U 32 bay rackmount system for both Intel and AMD PCIe Gen 5 platforms. All of the Supermicro systems that support either the E1.S or E3.s form factors enable customers to realize the benefits in various application-optimized servers.
The initial offering of the updated product line will support up to one-half of a petabyte of storage space in a 1U 16 bay rackmount system, followed by a full petabyte of storage space in a 2U 32 bay rackmount system for both Intel and AMD PCIe Gen 5 platforms. All of the Supermicro systems that support either the E1.S or E3.s form factors enable customers to realize the benefits in various application-optimized servers.


Intel's Transition of OpenFL Primes Growth of Confidential AI
Today, Intel announced that the LF AI & Data Foundation Technical Advisory Council accepted Open Federated Learning (OpenFL) as an incubation project to further drive collaboration, standardization and interoperability. OpenFL is an open source framework for a type of distributed AI referred to as federated learning (FL) that incorporates privacy-preserving features called confidential computing. It was developed and hosted by Intel to help data scientists address the challenge of maintaining data privacy while bringing together insights from many disparate, confidential or regulated data sets.
"We are thrilled to welcome OpenFL to the LF AI & Data Foundation. This project's innovative approach to enabling organizations to collaboratively train machine learning models across multiple devices or data centers without the need to share raw data aligns perfectly with our mission to accelerate the growth and adoption of open source AI and data technologies. We look forward to collaborating with the talented individuals behind this project and helping to drive its success," said Dr. Ibrahim Haddad, executive director, LF AI & Data Foundation.
"We are thrilled to welcome OpenFL to the LF AI & Data Foundation. This project's innovative approach to enabling organizations to collaboratively train machine learning models across multiple devices or data centers without the need to share raw data aligns perfectly with our mission to accelerate the growth and adoption of open source AI and data technologies. We look forward to collaborating with the talented individuals behind this project and helping to drive its success," said Dr. Ibrahim Haddad, executive director, LF AI & Data Foundation.

Renesas to Demonstrate First AI Implementations on the Arm Cortex-M85 Processor Featuring Helium Technology
Renesas Electronics Corporation, a premier supplier of advanced semiconductor solutions, today announced that it will present the first live demonstrations of artificial intelligence (AI) and machine learning (ML) implementations on an MCU based on the Arm Cortex -M85 processor. The demos will show the performance uplift in AI/ML applications made possible by the new Cortex-M85 core and Arm's Helium technology. They will take place in the Renesas stand - Hall 1, Stand 234 (1-234) at the embedded world 2023 Exhibition and Conference in Nuremburg, Germany from March 14-16.
At embedded world in 2022, Renesas became the first company to demonstrate working silicon based on the Arm Cortex-M85 processor. This year, Renesas is extending its leadership by showcasing the features of the new processor in demanding AI use cases. The first demonstration showcases a people detection application developed in collaboration with Plumerai, a leader in Vision AI, that identifies and tracks persons in the camera frame in varying lighting and environmental conditions. The compact and efficient TinyML models used in this application lead to low-cost and lower power AI solutions for a wide range of IoT implementations. The second demo showcases a motor control predictive maintenance use case with an AI-based unbalanced load detection application using Tensorflow Lite for Microcontrollers with CMSIS-NN.
At embedded world in 2022, Renesas became the first company to demonstrate working silicon based on the Arm Cortex-M85 processor. This year, Renesas is extending its leadership by showcasing the features of the new processor in demanding AI use cases. The first demonstration showcases a people detection application developed in collaboration with Plumerai, a leader in Vision AI, that identifies and tracks persons in the camera frame in varying lighting and environmental conditions. The compact and efficient TinyML models used in this application lead to low-cost and lower power AI solutions for a wide range of IoT implementations. The second demo showcases a motor control predictive maintenance use case with an AI-based unbalanced load detection application using Tensorflow Lite for Microcontrollers with CMSIS-NN.

Revenue from Enterprise SSDs Totaled Just US$3.79 Billion for 4Q22 Due to Slumping Demand and Widening Decline in SSD Contract Prices, Says TrendForce
Looking back at 2H22, as server OEMs slowed down the momentum of their product shipments, Chinese server buyers also held a conservative outlook on future demand and focused on inventory reduction. Thus, the flow of orders for enterprise SSDs remained sluggish. However, NAND Flash suppliers had to step up shipments of enterprise SSDs during 2H22 because the demand for storage components equipped in notebook (laptop) computers and smartphones had undergone very large downward corrections. Compared with other categories of NAND Flash products, enterprise SSDs represented the only significant source of bit consumption. Ultimately, due to the imbalance between supply and demand, the QoQ decline in prices of enterprise SSDs widened to 25% for 4Q22. This price plunge, in turn, caused the quarterly total revenue from enterprise SSDs to drop by 27.4% QoQ to around US$3.79 billion. TrendForce projects that the NAND Flash industry will again post a QoQ decline in the revenue from this product category for 1Q23.

Ayar Labs Demonstrates Industry's First 4-Tbps Optical Solution, Paving Way for Next-Generation AI and Data Center Designs
Ayar Labs, a leader in the use of silicon photonics for chip-to-chip optical connectivity, today announced public demonstration of the industry's first 4 terabit-per-second (Tbps) bidirectional Wavelength Division Multiplexing (WDM) optical solution at the upcoming Optical Fiber Communication Conference (OFC) in San Diego on March 5-9, 2023. The company achieves this latest milestone as it works with leading high-volume manufacturing and supply partners including GlobalFoundries, Lumentum, Macom, Sivers Photonics and others to deliver the optical interconnects needed for data-intensive applications. Separately, the company was featured in an announcement with partner Quantifi Photonics on a CW-WDM-compliant test platform for its SuperNova light source, also at OFC.
In-package optical I/O uniquely changes the power and performance trajectories of system design by enabling compute, memory and network silicon to communicate with a fraction of the power and dramatically improved performance, latency and reach versus existing electrical I/O solutions. Delivered in a compact, co-packaged CMOS chiplet, optical I/O becomes foundational to next-generation AI, disaggregated data centers, dense 6G telecommunications systems, phased array sensory systems and more.
In-package optical I/O uniquely changes the power and performance trajectories of system design by enabling compute, memory and network silicon to communicate with a fraction of the power and dramatically improved performance, latency and reach versus existing electrical I/O solutions. Delivered in a compact, co-packaged CMOS chiplet, optical I/O becomes foundational to next-generation AI, disaggregated data centers, dense 6G telecommunications systems, phased array sensory systems and more.


Open Compute Project Foundation and JEDEC Announce a New Collaboration
Today, the Open Compute Project Foundation (OCP), the nonprofit organization bringing hyperscale innovations to all, and JEDEC Solid State Technology Association, the global leader in the development of standards for the microelectronics industry, announce a new collaboration to establish a framework for the transfer of technology captured in an OCP-approved specification to JEDEC for inclusion in one of its standards. This alliance brings together members from both the OCP and JEDEC communities to share efforts in developing and maintaining global standards needed to advance the electronics industry.
Under this new alliance, the current effort will be to provide a mechanism to standardize Chiplet part descriptions leveraging OCP Chiplet Data Extensible Markup Language (CDXML) specification to become part of JEDEC JEP30: Part Model Guidelines for use with today's EDA tools. With this updated JEDEC standard, expected to be published in 2023, Chiplet builders will be able to provide electronically a standardized Chiplet part description to their customers paving the way for automating System in Package (SiP) design and build using Chiplets. The description will include information needed by SiP builders such as Chiplet thermal properties, physical and mechanical requirements, behavior specifications, power and signal integrity properties, testing the Chiplet in package, and security parameters.
Under this new alliance, the current effort will be to provide a mechanism to standardize Chiplet part descriptions leveraging OCP Chiplet Data Extensible Markup Language (CDXML) specification to become part of JEDEC JEP30: Part Model Guidelines for use with today's EDA tools. With this updated JEDEC standard, expected to be published in 2023, Chiplet builders will be able to provide electronically a standardized Chiplet part description to their customers paving the way for automating System in Package (SiP) design and build using Chiplets. The description will include information needed by SiP builders such as Chiplet thermal properties, physical and mechanical requirements, behavior specifications, power and signal integrity properties, testing the Chiplet in package, and security parameters.

NVIDIA Could Release AI-Optimized Drivers, Improving Overall Performance
NVIDIA is using artificial intelligence to design and develop parts of its chip designs, as we have seen in the past, making optimization much more efficient. However, today we have a new rumor that NVIDIA will use AI to optimize its driver performance to reach grounds that the human workforce can not. According to CapFrameX, NVIDIA is allegedly preparing special drivers with optimizations done by AI algorithms. As the source claims, the average improvement will yield a 10% performance increase with up to 30% in best-case scenarios. Presumably, AI can do optimization on two fronts: shader compiles / game optimization side or for power management, which includes clocks, voltages, and boost frequency curves.
It still needs to be made clear which aspect will company's AI optimize and work on; however, it can be a combination of two, given the expected drastic improvement in performance. Special tuning of code for more efficient execution and a better power/frequency curve will bring the efficiency level one notch above current releases. We have already seen AI solve these problems last year with the PrefixML model that compacted circuit design by 25%. We need to find out which cards NVIDIA plans to target, and we can only assume that the latest-generation GeForce RTX 40 series will be the goal if the project is made public in Q1 of this year.
It still needs to be made clear which aspect will company's AI optimize and work on; however, it can be a combination of two, given the expected drastic improvement in performance. Special tuning of code for more efficient execution and a better power/frequency curve will bring the efficiency level one notch above current releases. We have already seen AI solve these problems last year with the PrefixML model that compacted circuit design by 25%. We need to find out which cards NVIDIA plans to target, and we can only assume that the latest-generation GeForce RTX 40 series will be the goal if the project is made public in Q1 of this year.


AMD Shows Instinct MI300 Exascale APU with 146 Billion Transistors
During its CES 2023 keynote, AMD announced its latest Instinct MI300 APU, a first of its kind in the data center world. Combining the CPU, GPU, and memory elements into a single package eliminates latency imposed by long travel distances of data from CPU to memory and from CPU to GPU throughout the PCIe connector. In addition to solving some latency issues, less power is needed to move the data and provide greater efficiency. The Instinct MI300 features 24 Zen4 cores with simultaneous multi-threading enabled, CDNA3 GPU IP, and 128 GB of HBM3 memory on a single package. The memory bus is 8192-bit wide, providing unified memory access for CPU and GPU cores. CLX 3.0 is also supported, making cache-coherent interconnecting a reality.
The Instinct MI300 APU package is an engineering marvel of its own, with advanced chiplet techniques used. AMD managed to do 3D stacking and has nine 5 nm logic chiplets that are 3D stacked on top of four 6 nm chiplets with HBM surrounding it. All of this makes the transistor count go up to 146 billion, representing the sheer complexity of a such design. For performance figures, AMD provided a comparison to Instinct MI250X GPU. In raw AI performance, the MI300 features an 8x improvement over MI250X, while the performance-per-watt is "reduced" to a 5x increase. While we do not know what benchmark applications were used, there is a probability that some standard benchmarks like MLPerf were used. For availability, AMD targets the end of 2023, when the "El Capitan" exascale supercomputer will arrive using these Instinct MI300 APU accelerators. Pricing is unknown and will be unveiled to enterprise customers first around launch.



The Instinct MI300 APU package is an engineering marvel of its own, with advanced chiplet techniques used. AMD managed to do 3D stacking and has nine 5 nm logic chiplets that are 3D stacked on top of four 6 nm chiplets with HBM surrounding it. All of this makes the transistor count go up to 146 billion, representing the sheer complexity of a such design. For performance figures, AMD provided a comparison to Instinct MI250X GPU. In raw AI performance, the MI300 features an 8x improvement over MI250X, while the performance-per-watt is "reduced" to a 5x increase. While we do not know what benchmark applications were used, there is a probability that some standard benchmarks like MLPerf were used. For availability, AMD targets the end of 2023, when the "El Capitan" exascale supercomputer will arrive using these Instinct MI300 APU accelerators. Pricing is unknown and will be unveiled to enterprise customers first around launch.




DPVR E4 Announced with November Launch, Aims to Dominating the Consumer Market for Tethered PC VR Headsets
DPVR, a leading provider of virtual reality (VR) devices, has today announced the launch of its newest PC VR gaming headset with the introduction of the 'DPVR E4,' which is aimed at dominating the consumer market for tethered PC VR headsets. In a different category altogether from standalone VR headsets such as the Meta Quest 2 and Pico 4 devices, the DPVR E4 provides PC VR gamers with a tethered alternative that offers a wider field of view (FoV), in a more compact and lighter form factor, as well as offering a more affordable solution compared to high-price tag devices such as the VIVE Pro 2.
DPVR has been making VR headsets for seven years. Prior to E4's launch, the company's efforts were primarily directed towards the B2B market, with a specialized focus on the education and medical industries. Over the last decade, DPVR has completed three successful funding rounds, which the company has used for its research and development efforts into furthering its VR hardware and software offerings. This latest announcement from DPVR marks the company's first step into the consumer VR headset market.
DPVR has been making VR headsets for seven years. Prior to E4's launch, the company's efforts were primarily directed towards the B2B market, with a specialized focus on the education and medical industries. Over the last decade, DPVR has completed three successful funding rounds, which the company has used for its research and development efforts into furthering its VR hardware and software offerings. This latest announcement from DPVR marks the company's first step into the consumer VR headset market.

Cerebras Unveils Andromeda, a 13.5 Million Core AI Supercomputer that Delivers Near-Perfect Linear Scaling for Large Language Models
Cerebras Systems, the pioneer in accelerating artificial intelligence (AI) compute, today unveiled Andromeda, a 13.5 million core AI supercomputer, now available and being used for commercial and academic work. Built with a cluster of 16 Cerebras CS-2 systems and leveraging Cerebras MemoryX and SwarmX technologies, Andromeda delivers more than 1 Exaflop of AI compute and 120 Petaflops of dense compute at 16-bit half precision. It is the only AI supercomputer to ever demonstrate near-perfect linear scaling on large language model workloads relying on simple data parallelism alone.
With more than 13.5 million AI-optimized compute cores and fed by 18,176 3rd Gen AMD EPYC processors, Andromeda features more cores than 1,953 Nvidia A100 GPUs and 1.6 times as many cores as the largest supercomputer in the world, Frontier, which has 8.7 million cores. Unlike any known GPU-based cluster, Andromeda delivers near-perfect scaling via simple data parallelism across GPT-class large language models, including GPT-3, GPT-J and GPT-NeoX.
With more than 13.5 million AI-optimized compute cores and fed by 18,176 3rd Gen AMD EPYC processors, Andromeda features more cores than 1,953 Nvidia A100 GPUs and 1.6 times as many cores as the largest supercomputer in the world, Frontier, which has 8.7 million cores. Unlike any known GPU-based cluster, Andromeda delivers near-perfect scaling via simple data parallelism across GPT-class large language models, including GPT-3, GPT-J and GPT-NeoX.

Intel Delivers Leading AI Performance Results on MLPerf v2.1 Industry Benchmark for DL Training
Today, MLCommons published results of its industry AI performance benchmark in which both the 4th Generation Intel Xeon Scalable processor (code-named Sapphire Rapids) and Habana Gaudi 2 dedicated deep learning accelerator logged impressive training results.
"I'm proud of our team's continued progress since we last submitted leadership results on MLPerf in June. Intel's 4th gen Xeon Scalable processor and Gaudi 2 AI accelerator support a wide array of AI functions and deliver leadership performance for customers who require deep learning training and large-scale workloads." Sandra Rivera, Intel executive vice president and general manager of the Datacenter and AI Group

"I'm proud of our team's continued progress since we last submitted leadership results on MLPerf in June. Intel's 4th gen Xeon Scalable processor and Gaudi 2 AI accelerator support a wide array of AI functions and deliver leadership performance for customers who require deep learning training and large-scale workloads." Sandra Rivera, Intel executive vice president and general manager of the Datacenter and AI Group


Rescale Teams with NVIDIA to Unite HPC and AI for Optimized Engineering in the Cloud
Rescale, the leader in high performance computing built for the cloud to accelerate engineering innovation, today announced it is teaming with NVIDIA to integrate the NVIDIA AI platform into Rescale's HPC-as-a-Service offering. The integration is designed to advance computational engineering simulation with AI and machine learning, helping enterprises commercialize new product innovations faster, more efficiently and at less cost.
Additionally, Rescale announced the world's first Compute Recommendation Engine (CRE) to power Intelligent Computing for HPC and AI workloads. Optimizing workload performance can be prohibitively complex as organizations seek to balance decisions among architectures, geographic regions, price points, scalability, service levels, compliance, and sustainability objectives. Developed using machine learning on NVIDIA architectures with infrastructure telemetry, industry benchmarks, and full-stack metadata spanning over 100 million production HPC workloads, Rescale CRE provides customers unprecedented insight to optimize overall performance.
Additionally, Rescale announced the world's first Compute Recommendation Engine (CRE) to power Intelligent Computing for HPC and AI workloads. Optimizing workload performance can be prohibitively complex as organizations seek to balance decisions among architectures, geographic regions, price points, scalability, service levels, compliance, and sustainability objectives. Developed using machine learning on NVIDIA architectures with infrastructure telemetry, industry benchmarks, and full-stack metadata spanning over 100 million production HPC workloads, Rescale CRE provides customers unprecedented insight to optimize overall performance.


ASUS Announces AMD EPYC 9004-Powered Rack Servers and Liquid-Cooling Solutions
ASUS, a leading provider of server systems, server motherboards and workstations, today announced new best-in-class server solutions powered by the latest AMD EPYC 9004 Series processors. ASUS also launched superior liquid-cooling solutions that dramatically improve the data-center power-usage effectiveness (PUE).
The breakthrough thermal design in this new generation delivers superior power and thermal capabilities to support class-leading features, including up to 400-watt CPUs, up to 350-watt GPUs, and 400 Gbps networking. All ASUS liquid-cooling solutions will be demonstrated in the ASUS booth (number 3816) at SC22 from November 14-17, 2022, at Kay Bailey Hutchison Convention Center in Dallas, Texas.


The breakthrough thermal design in this new generation delivers superior power and thermal capabilities to support class-leading features, including up to 400-watt CPUs, up to 350-watt GPUs, and 400 Gbps networking. All ASUS liquid-cooling solutions will be demonstrated in the ASUS booth (number 3816) at SC22 from November 14-17, 2022, at Kay Bailey Hutchison Convention Center in Dallas, Texas.



Cincoze's Embedded Computer DV-1000 Plays a Key Role in Predictive Maintenance
With the evolution of IIoT and AI technology, more and more manufacturing industries are introducing predictive maintenance to collect equipment data on-site. Predictive maintenance collects machine equipment data and uses AI and machine learning (ML) for data analysis, avoiding manual decision-making and strengthening automation to reduce the average cost and downtime of maintenance and increase the accuracy of machine downtime predictions. These factors extend machine lifetime and enhance efficiency, and in turn increase profits. Cincoze's Rugged Computing - DIAMOND product line includes the high-performance and essential embedded computer series DV-1000, integrating high-performance computing and flexible expansion capabilities into a small and compact body. The system can process large amounts of data in real time for data analytics. It is the ultimate system for bringing preventive maintenance to industrial sites with challenging conditions.
Performance is the top priority. It lies at the core of predictive maintenance, where data from different devices must be collected, processed, and analyzed in real-time, and then connected with a cloud platform. The high-performance and essential embedded computer series DV-1000 offers high-performance computing, supporting a 9/8th gen Intel Core i7/i5/i3 (Coffee Lake-R S series) processor and up to 32 GB of DDR4 2666 MHz memory. Storage options include a 2.5" SATA HDD/SSD tray, 2× mSATA slots, 1× M.2 Key M 2280, and NVMe high-speed SSD. The DV-1000 meets the performance requirements necessary for multi-tasking and on-site data analytics in smart manufacturing and can also be used in fields such as machine vision and railway transportation.


Performance is the top priority. It lies at the core of predictive maintenance, where data from different devices must be collected, processed, and analyzed in real-time, and then connected with a cloud platform. The high-performance and essential embedded computer series DV-1000 offers high-performance computing, supporting a 9/8th gen Intel Core i7/i5/i3 (Coffee Lake-R S series) processor and up to 32 GB of DDR4 2666 MHz memory. Storage options include a 2.5" SATA HDD/SSD tray, 2× mSATA slots, 1× M.2 Key M 2280, and NVMe high-speed SSD. The DV-1000 meets the performance requirements necessary for multi-tasking and on-site data analytics in smart manufacturing and can also be used in fields such as machine vision and railway transportation.




ASML Reports €5.4 Billion Net Sales and €1.4 Billion Net Income in Q2 2022
Today ASML Holding NV (ASML) has published its 2022 second-quarter results. Q2 net sales of €5.4 billion, gross margin of 49.1%, net income of €1.4 billion. Record quarterly net bookings in Q2 of €8.5 billion. ASML expects Q3 2022 net sales between €5.1 billion and €5.4 billion and a gross margin between 49% and 50%. Expected sales growth for the full year of around 10%.
The value of fast shipments*in 2022 leading to delayed revenue recognition into 2023 is expected to increase from around €1 billion to around €2.8 billion.
"Our second-quarter net sales came in at €5.4 billion with a gross margin of 49.1%. Demand from our customers remains very strong, as reflected by record net bookings in the second quarter of €8.5 billion, including €5.4 billion from 0.33 NA and 0.55 NA EUV systems as well as strong DUV bookings.
The value of fast shipments*in 2022 leading to delayed revenue recognition into 2023 is expected to increase from around €1 billion to around €2.8 billion.
"Our second-quarter net sales came in at €5.4 billion with a gross margin of 49.1%. Demand from our customers remains very strong, as reflected by record net bookings in the second quarter of €8.5 billion, including €5.4 billion from 0.33 NA and 0.55 NA EUV systems as well as strong DUV bookings.

Ayar Labs Partners with NVIDIA to Deliver Light-Based Interconnect for AI Architectures
Ayar Labs, the leader in chip-to-chip optical connectivity, is developing with NVIDIA groundbreaking artificial intelligence (AI) infrastructure based on optical I/O technology to meet future demands of AI and high performance computing (HPC) workloads. The collaboration will focus on integrating Ayar Labs' technology to develop scale-out architectures enabled by high-bandwidth, low-latency and ultra-low-power optical-based interconnects for future NVIDIA products. Together, the companies plan to accelerate the development and adoption of optical I/O technology to support the explosive growth of AI and machine learning (ML) applications and data volumes.
Optical I/O uniquely changes the performance and power trajectories of system designs by enabling compute, memory and networking ASICs to communicate with dramatically increased bandwidth, at lower latency, over longer distances and at a fraction of the power of existing electrical I/O solutions. The technology is also foundational to enabling emerging heterogeneous compute systems, disaggregated/pooled designs, and unified memory architectures that are critical to accelerating future data center innovation.
Optical I/O uniquely changes the performance and power trajectories of system designs by enabling compute, memory and networking ASICs to communicate with dramatically increased bandwidth, at lower latency, over longer distances and at a fraction of the power of existing electrical I/O solutions. The technology is also foundational to enabling emerging heterogeneous compute systems, disaggregated/pooled designs, and unified memory architectures that are critical to accelerating future data center innovation.

HPE Build Supercomputer Factory in Czech Republic
Hewlett Packard Enterprise (NYSE: HPE) today announced its ongoing commitment in Europe by building its first factory in the region for next-generation high performance computing (HPC) and artificial intelligence (AI) systems to accelerate delivery to customers and strengthen the region's supplier ecosystem. The new site will manufacture HPE's industry-leading systems as custom-designed solutions to advance scientific research, mature AL/ML initiatives, and bolster innovation.
The dedicated HPC factory, which will become the fourth of HPE's global HPC sites, will be located in Kutná Hora, Czech Republic, next to HPE's existing European site for manufacturing its industry-standard servers and storage solutions. Operations will begin in summer 2022.
The dedicated HPC factory, which will become the fourth of HPE's global HPC sites, will be located in Kutná Hora, Czech Republic, next to HPE's existing European site for manufacturing its industry-standard servers and storage solutions. Operations will begin in summer 2022.

Apr 6th, 2025 21:46 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- No idea how many watts this USB-C port will supply? (2)
- I dont think the HT-Omega sound card company has anyone running it anymore. Cant get responses from customer service for last 2 years. (2)
- A dozen drivers for HD4670, and which do I choose? (10)
- What's your latest tech purchase? (23486)
- gpu heirarchy/performance/benchmarks- whos lying? (38)
- What are you playing? (23349)
- i7-13700HX capped at 25 watts (13)
- 9070XT or 7900XT (39)
- Weird games on rtx 3070ti (1)
- RX 9000 series GPU Owners Club (198)
Popular Reviews
- ASUS Prime X870-P Wi-Fi Review
- UPERFECT UStation Delta Max Review - Two Screens In One
- PowerColor Radeon RX 9070 Hellhound Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Corsair RM750x Shift 750 W Review
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- DDR5 CUDIMM Explained & Benched - The New Memory Standard
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- AMD Ryzen 9 9950X3D Review - Great for Gaming and Productivity
Controversial News Posts
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (134)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (97)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (92)