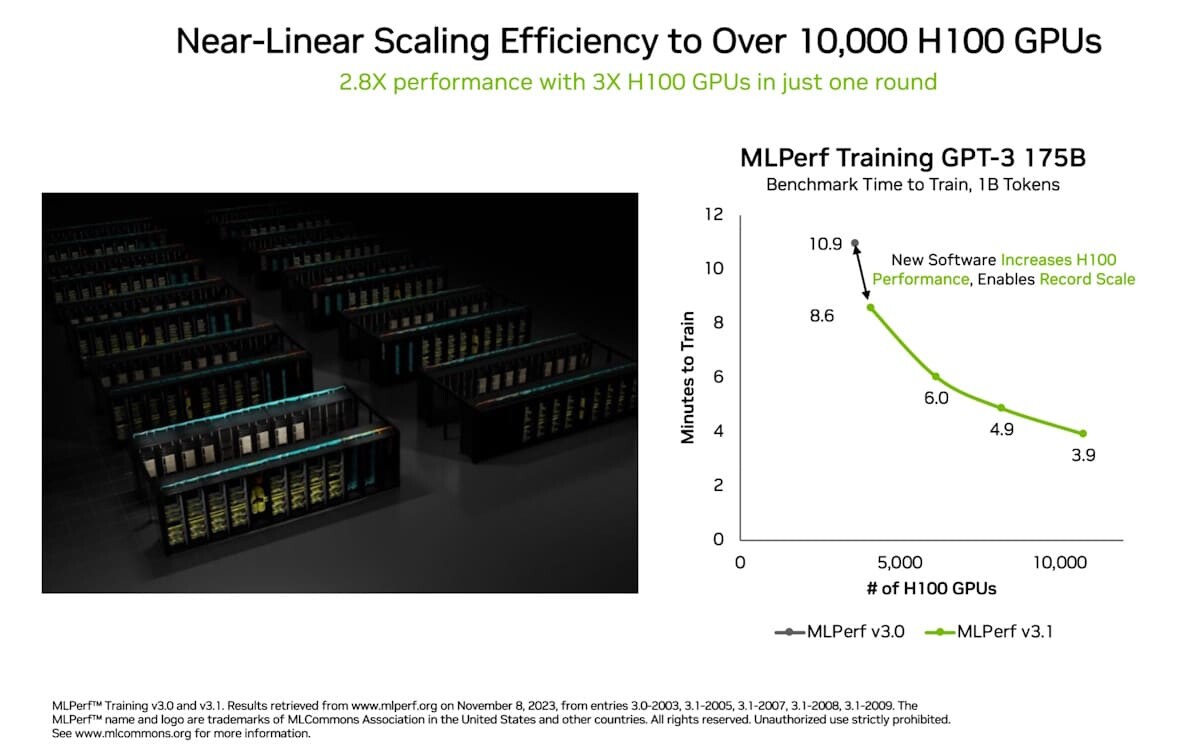
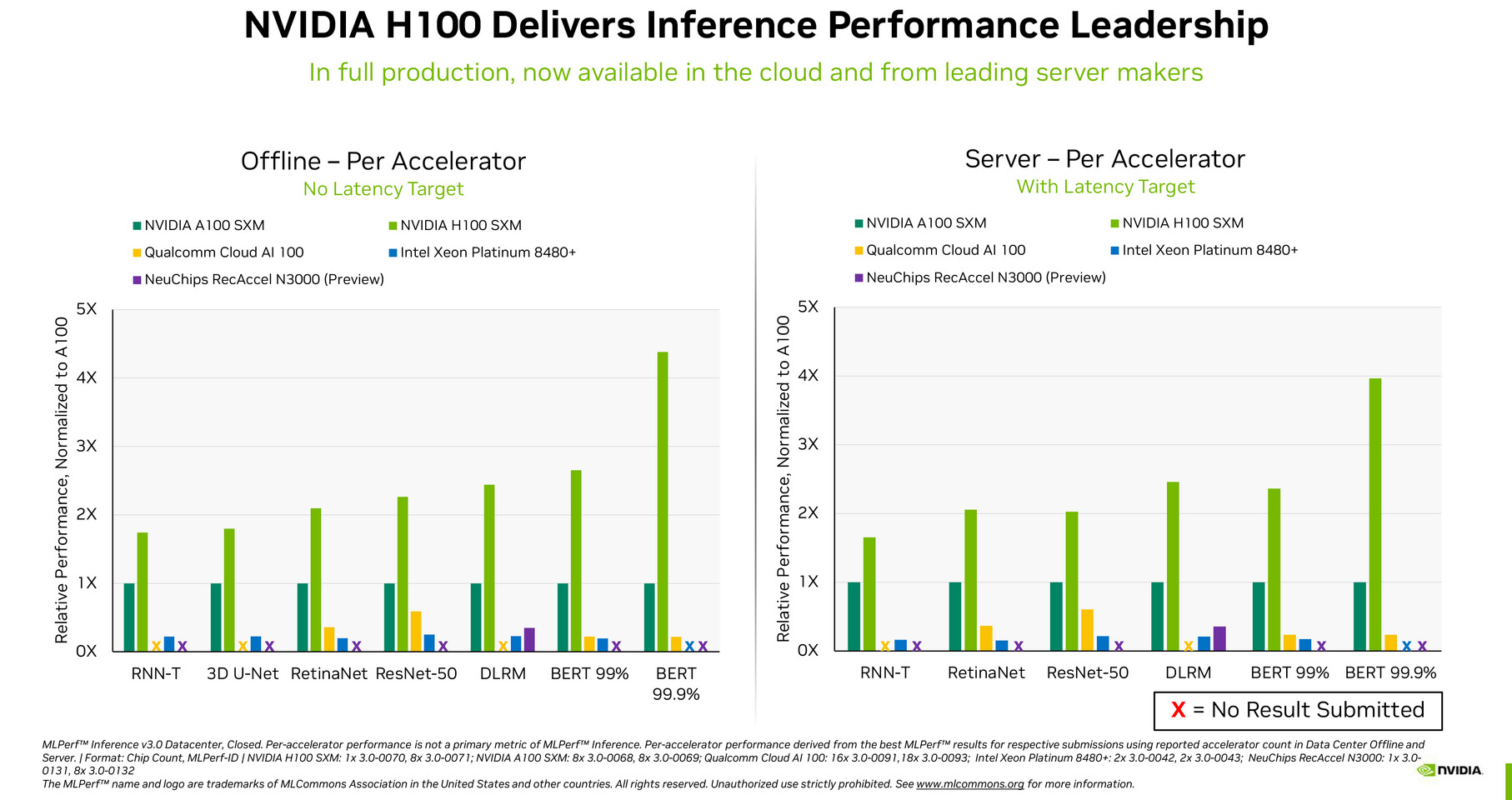
UL Announces the Procyon AI Image Generation Benchmark Based on Stable Diffusion
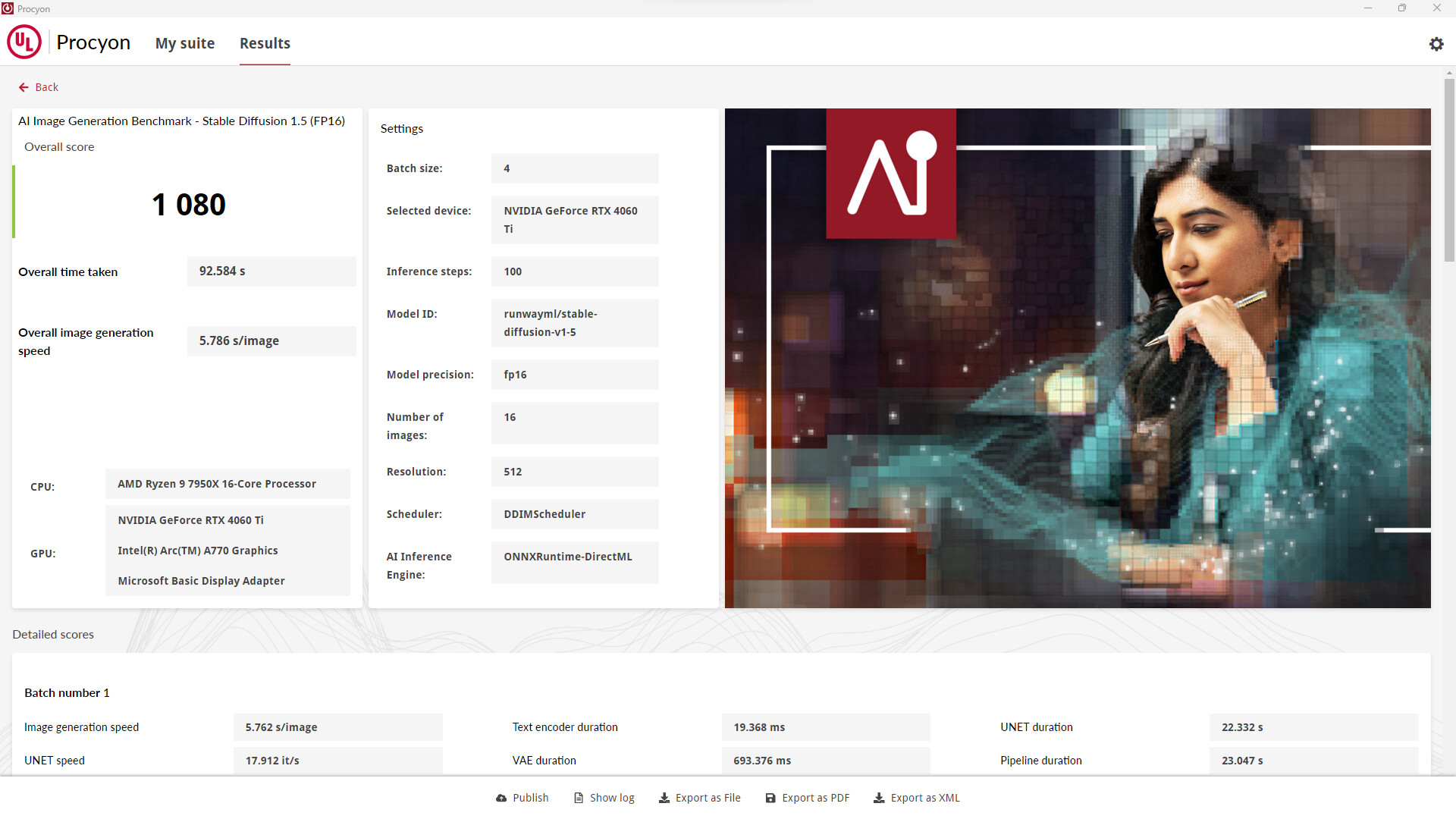
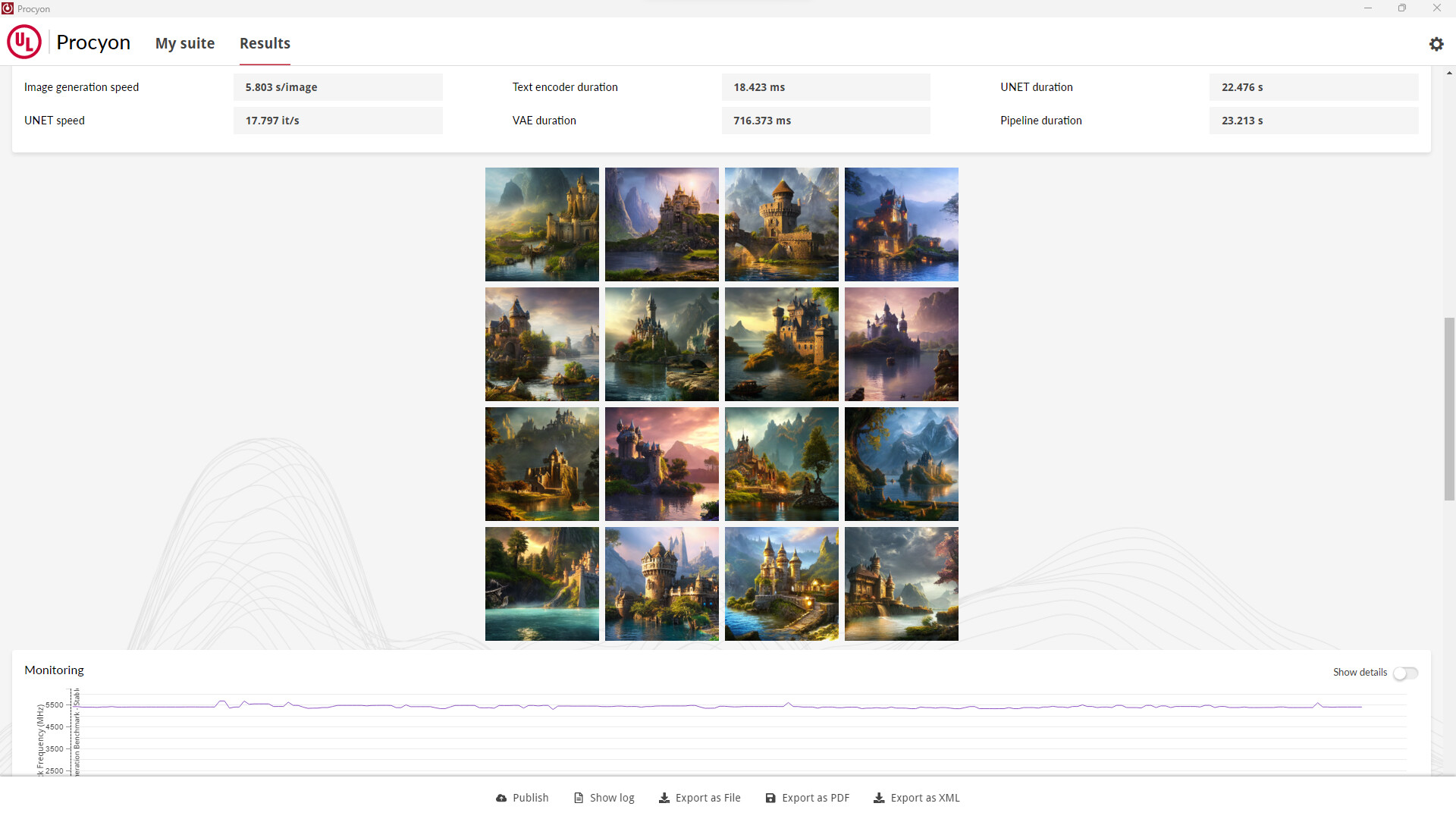
We're excited to announce we're expanding our AI Inference benchmark offerings with the UL Procyon AI Image Generation Benchmark, coming Monday, 25th March. AI has the potential to be one of the most significant new technologies hitting the mainstream this decade, and many industry leaders are competing to deliver the best AI Inference performance through their hardware. Last year, we launched the first of our Procyon AI Inference Benchmarks for Windows, which measured AI Inference performance with a workload using Computer Vision.
The upcoming UL Procyon AI Image Generation Benchmark provides a consistent, accurate and understandable workload for measuring the AI performance of high-end hardware, built with input from members of the industry to ensure fair and comparable results across all supported hardware.

The upcoming UL Procyon AI Image Generation Benchmark provides a consistent, accurate and understandable workload for measuring the AI performance of high-end hardware, built with input from members of the industry to ensure fair and comparable results across all supported hardware.