Wednesday, November 8th 2023

NVIDIA Turbocharges Generative AI Training in MLPerf Benchmarks
NVIDIA's AI platform raised the bar for AI training and high performance computing in the latest MLPerf industry benchmarks. Among many new records and milestones, one in generative AI stands out: NVIDIA Eos - an AI supercomputer powered by a whopping 10,752 NVIDIA H100 Tensor Core GPUs and NVIDIA Quantum-2 InfiniBand networking - completed a training benchmark based on a GPT-3 model with 175 billion parameters trained on one billion tokens in just 3.9 minutes. That's a nearly 3x gain from 10.9 minutes, the record NVIDIA set when the test was introduced less than six months ago.
The benchmark uses a portion of the full GPT-3 data set behind the popular ChatGPT service that, by extrapolation, Eos could now train in just eight days, 73x faster than a prior state-of-the-art system using 512 A100 GPUs. The acceleration in training time reduces costs, saves energy and speeds time-to-market. It's heavy lifting that makes large language models widely available so every business can adopt them with tools like NVIDIA NeMo, a framework for customizing LLMs. In a new generative AI test this round, 1,024 NVIDIA Hopper architecture GPUs completed a training benchmark based on the Stable Diffusion text-to-image model in 2.5 minutes, setting a high bar on this new workload. By adopting these two tests, MLPerf reinforces its leadership as the industry standard for measuring AI performance, since generative AI is the most transformative technology of our time.


 System Scaling Soars
System Scaling Soars
The latest results were due in part to the use of the most accelerators ever applied to an MLPerf benchmark. The 10,752 H100 GPUs far surpassed the scaling in AI training in June, when NVIDIA used 3,584 Hopper GPUs.
The 3x scaling in GPU numbers delivered a 2.8x scaling in performance, a 93% efficiency rate thanks in part to software optimizations.
Efficient scaling is a key requirement in generative AI because LLMs are growing by an order of magnitude every year. The latest results show NVIDIA's ability to meet this unprecedented challenge for even the world's largest data centers.
The achievement is thanks to a full-stack platform of innovations in accelerators, systems and software that both Eos and Microsoft Azure used in the latest round.
Eos and Azure both employed 10,752 H100 GPUs in separate submissions. They achieved within 2% of the same performance, demonstrating the efficiency of NVIDIA AI in data center and public-cloud deployments.
NVIDIA relies on Eos for a wide array of critical jobs. It helps advance initiatives like NVIDIA DLSS, AI-powered software for state-of-the-art computer graphics and NVIDIA Research projects like ChipNeMo, generative AI tools that help design next-generation GPUs.
Advances Across Workloads
NVIDIA set several new records in this round in addition to making advances in generative AI.
For example, H100 GPUs were 1.6x faster than the prior-round training recommender models widely employed to help users find what they're looking for online. Performance was up 1.8x on RetinaNet, a computer vision model.
These increases came from a combination of advances in software and scaled-up hardware.
NVIDIA was once again the only company to run all MLPerf tests. H100 GPUs demonstrated the fastest performance and the greatest scaling in each of the nine benchmarks.
Speedups translate to faster time to market, lower costs and energy savings for users training massive LLMs or customizing them with frameworks like NeMo for the specific needs of their business.
Eleven systems makers used the NVIDIA AI platform in their submissions this round, including ASUS, Dell Technologies, Fujitsu, GIGABYTE, Lenovo, QCT and Supermicro.
NVIDIA partners participate in MLPerf because they know it's a valuable tool for customers evaluating AI platforms and vendors.
HPC Benchmarks Expand
In MLPerf HPC, a separate benchmark for AI-assisted simulations on supercomputers, H100 GPUs delivered up to twice the performance of NVIDIA A100 Tensor Core GPUs in the last HPC round. The results showed up to 16x gains since the first MLPerf HPC round in 2019.
The benchmark included a new test that trains OpenFold, a model that predicts the 3D structure of a protein from its sequence of amino acids. OpenFold can do in minutes vital work for healthcare that used to take researchers weeks or months.
Understanding a protein's structure is key to finding effective drugs fast because most drugs act on proteins, the cellular machinery that helps control many biological processes.
In the MLPerf HPC test, H100 GPUs trained OpenFold in 7.5 minutes. The OpenFold test is a representative part of the entire AlphaFold training process that two years ago took 11 days using 128 accelerators.
A version of the OpenFold model and the software NVIDIA used to train it will be available soon in NVIDIA BioNeMo, a generative AI platform for drug discovery.
Several partners made submissions on the NVIDIA AI platform in this round. They included Dell Technologies and supercomputing centers at Clemson University, the Texas Advanced Computing Center and - with assistance from Hewlett Packard Enterprise (HPE) - Lawrence Berkeley National Laboratory.
Benchmarks With Broad Backing
Since its inception in May 2018, the MLPerf benchmarks have enjoyed broad backing from both industry and academia. Organizations that support them include Amazon, Arm, Baidu, Google, Harvard, HPE, Intel, Lenovo, Meta, Microsoft, NVIDIA, Stanford University and the University of Toronto.
MLPerf tests are transparent and objective, so users can rely on the results to make informed buying decisions.
All the software NVIDIA used is available from the MLPerf repository, so all developers can get the same world-class results. These software optimizations get continuously folded into containers available on NGC, NVIDIA's software hub for GPU applications.
Source:
NVIDIA Blog
The benchmark uses a portion of the full GPT-3 data set behind the popular ChatGPT service that, by extrapolation, Eos could now train in just eight days, 73x faster than a prior state-of-the-art system using 512 A100 GPUs. The acceleration in training time reduces costs, saves energy and speeds time-to-market. It's heavy lifting that makes large language models widely available so every business can adopt them with tools like NVIDIA NeMo, a framework for customizing LLMs. In a new generative AI test this round, 1,024 NVIDIA Hopper architecture GPUs completed a training benchmark based on the Stable Diffusion text-to-image model in 2.5 minutes, setting a high bar on this new workload. By adopting these two tests, MLPerf reinforces its leadership as the industry standard for measuring AI performance, since generative AI is the most transformative technology of our time.
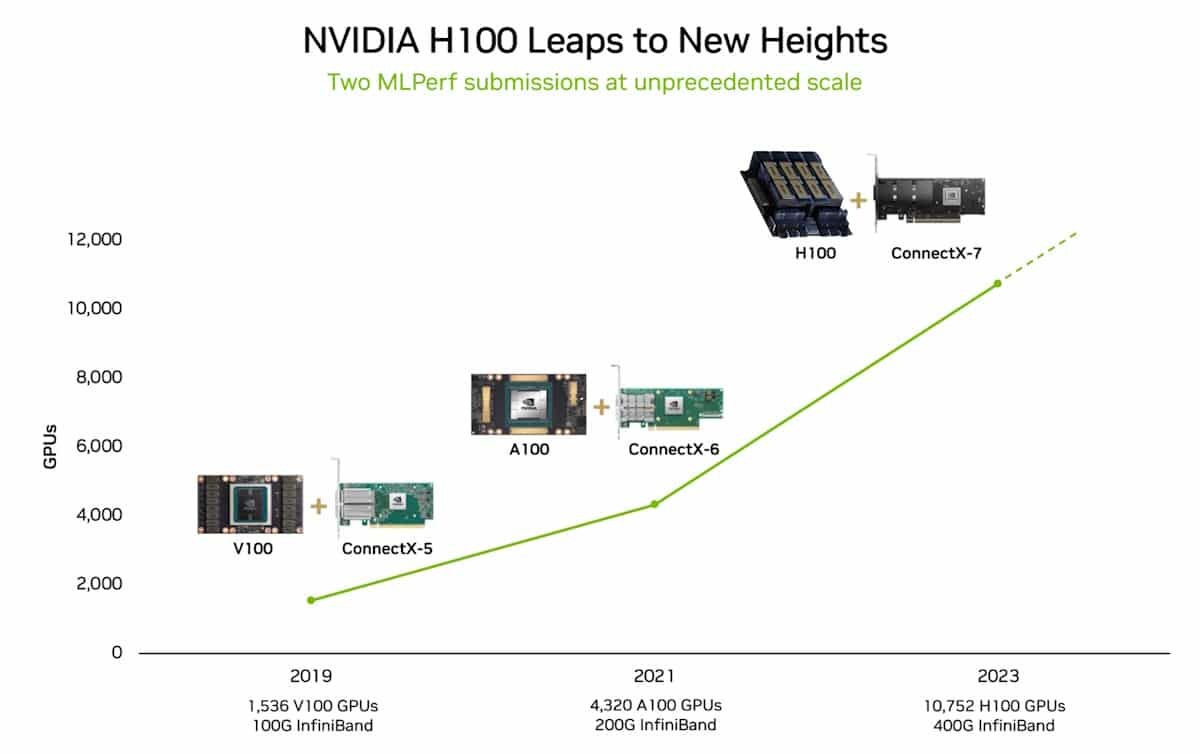
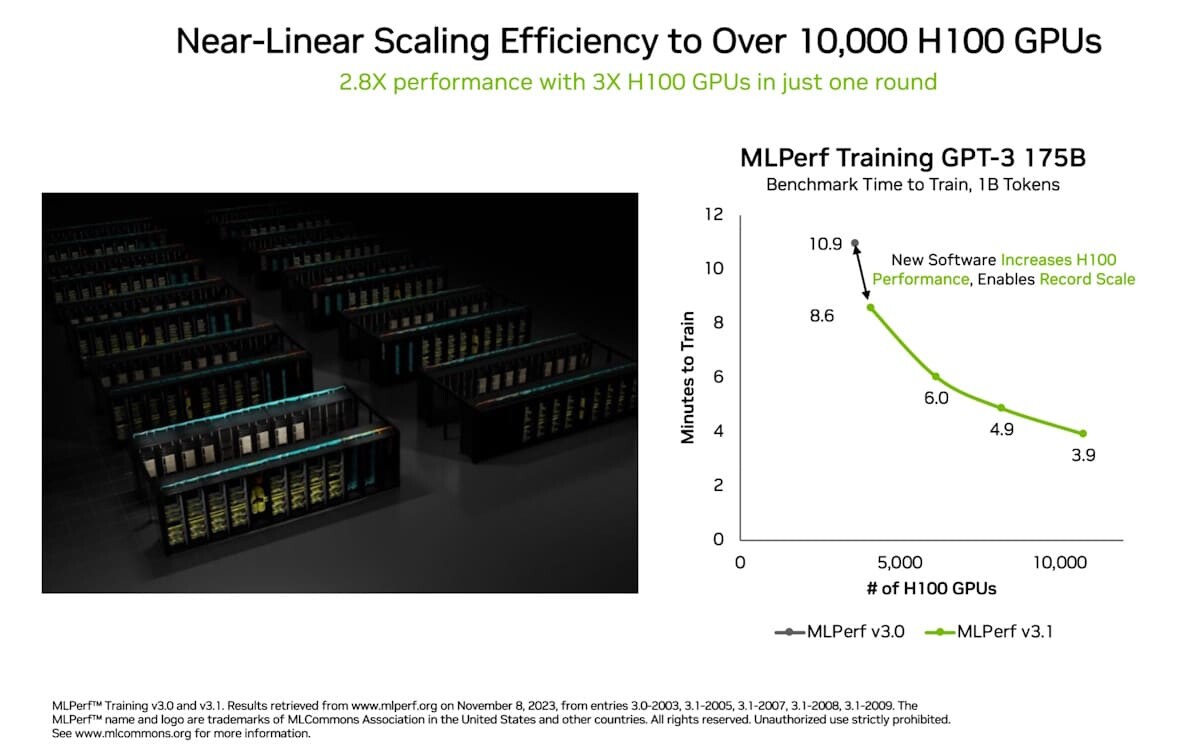


The latest results were due in part to the use of the most accelerators ever applied to an MLPerf benchmark. The 10,752 H100 GPUs far surpassed the scaling in AI training in June, when NVIDIA used 3,584 Hopper GPUs.
The 3x scaling in GPU numbers delivered a 2.8x scaling in performance, a 93% efficiency rate thanks in part to software optimizations.
Efficient scaling is a key requirement in generative AI because LLMs are growing by an order of magnitude every year. The latest results show NVIDIA's ability to meet this unprecedented challenge for even the world's largest data centers.
The achievement is thanks to a full-stack platform of innovations in accelerators, systems and software that both Eos and Microsoft Azure used in the latest round.
Eos and Azure both employed 10,752 H100 GPUs in separate submissions. They achieved within 2% of the same performance, demonstrating the efficiency of NVIDIA AI in data center and public-cloud deployments.
NVIDIA relies on Eos for a wide array of critical jobs. It helps advance initiatives like NVIDIA DLSS, AI-powered software for state-of-the-art computer graphics and NVIDIA Research projects like ChipNeMo, generative AI tools that help design next-generation GPUs.
Advances Across Workloads
NVIDIA set several new records in this round in addition to making advances in generative AI.
For example, H100 GPUs were 1.6x faster than the prior-round training recommender models widely employed to help users find what they're looking for online. Performance was up 1.8x on RetinaNet, a computer vision model.
These increases came from a combination of advances in software and scaled-up hardware.
NVIDIA was once again the only company to run all MLPerf tests. H100 GPUs demonstrated the fastest performance and the greatest scaling in each of the nine benchmarks.
Speedups translate to faster time to market, lower costs and energy savings for users training massive LLMs or customizing them with frameworks like NeMo for the specific needs of their business.
Eleven systems makers used the NVIDIA AI platform in their submissions this round, including ASUS, Dell Technologies, Fujitsu, GIGABYTE, Lenovo, QCT and Supermicro.
NVIDIA partners participate in MLPerf because they know it's a valuable tool for customers evaluating AI platforms and vendors.
HPC Benchmarks Expand
In MLPerf HPC, a separate benchmark for AI-assisted simulations on supercomputers, H100 GPUs delivered up to twice the performance of NVIDIA A100 Tensor Core GPUs in the last HPC round. The results showed up to 16x gains since the first MLPerf HPC round in 2019.
The benchmark included a new test that trains OpenFold, a model that predicts the 3D structure of a protein from its sequence of amino acids. OpenFold can do in minutes vital work for healthcare that used to take researchers weeks or months.
Understanding a protein's structure is key to finding effective drugs fast because most drugs act on proteins, the cellular machinery that helps control many biological processes.
In the MLPerf HPC test, H100 GPUs trained OpenFold in 7.5 minutes. The OpenFold test is a representative part of the entire AlphaFold training process that two years ago took 11 days using 128 accelerators.
A version of the OpenFold model and the software NVIDIA used to train it will be available soon in NVIDIA BioNeMo, a generative AI platform for drug discovery.
Several partners made submissions on the NVIDIA AI platform in this round. They included Dell Technologies and supercomputing centers at Clemson University, the Texas Advanced Computing Center and - with assistance from Hewlett Packard Enterprise (HPE) - Lawrence Berkeley National Laboratory.
Benchmarks With Broad Backing
Since its inception in May 2018, the MLPerf benchmarks have enjoyed broad backing from both industry and academia. Organizations that support them include Amazon, Arm, Baidu, Google, Harvard, HPE, Intel, Lenovo, Meta, Microsoft, NVIDIA, Stanford University and the University of Toronto.
MLPerf tests are transparent and objective, so users can rely on the results to make informed buying decisions.
All the software NVIDIA used is available from the MLPerf repository, so all developers can get the same world-class results. These software optimizations get continuously folded into containers available on NGC, NVIDIA's software hub for GPU applications.
2 Comments on NVIDIA Turbocharges Generative AI Training in MLPerf Benchmarks