Apr 6th, 2025 15:30 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- How I made an Ultimate Cooling Guide (18)
- The easiest way to connect the BOOTSEL test metal terminal and the GND terminal.... (0)
- What local LLM-s you use? (147)
- All Intel DG1 needs special bios? (30)
- Regarding Arctic's new Lineup of MAX fans! (1)
- TPU's F@H Team (20421)
- RX 9000 series GPU Owners Club (192)
- Clicks & Pops in Mic Audio due to buffer underruns. Please send help. (0)
- What are you playing? (23348)
- 9070XT or 7900XT (25)
Popular Reviews
- ASUS Prime X870-P Wi-Fi Review
- UPERFECT UStation Delta Max Review - Two Screens In One
- PowerColor Radeon RX 9070 Hellhound Review
- Corsair RM750x Shift 750 W Review
- DDR5 CUDIMM Explained & Benched - The New Memory Standard
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Pwnage Trinity CF Review
Controversial News Posts
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (124)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (97)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (92)
News Posts matching #MLPerf
Return to Keyword Browsing
AMD Instinct GPUs are Ready to Take on Today's Most Demanding AI Models
Customers evaluating AI infrastructure today rely on a combination of industry-standard benchmarks and real-world model performance metrics—such as those from Llama 3.1 405B, DeepSeek-R1, and other leading open-source models—to guide their GPU purchase decisions. At AMD, we believe that delivering value across both dimensions is essential to driving broader AI adoption and real-world deployment at scale. That's why we take a holistic approach—optimizing performance for rigorous industry benchmarks like MLperf while also enabling Day 0 support and rapid tuning for the models most widely used in production by our customers.
This strategy helps ensure AMD Instinct GPUs deliver not only strong, standardized performance, but also high-throughput, scalable AI inferencing across the latest generative and language models used by customers. We will explore how AMD's continued investment in benchmarking, open model enablement, software and ecosystem tools helps unlock greater value for customers—from MLPerf Inference 5.0 results to Llama 3.1 405B and DeepSeek-R1 performance, ROCm software advances, and beyond.



This strategy helps ensure AMD Instinct GPUs deliver not only strong, standardized performance, but also high-throughput, scalable AI inferencing across the latest generative and language models used by customers. We will explore how AMD's continued investment in benchmarking, open model enablement, software and ecosystem tools helps unlock greater value for customers—from MLPerf Inference 5.0 results to Llama 3.1 405B and DeepSeek-R1 performance, ROCm software advances, and beyond.





Intel Arc GPU Graphics Drivers 101.6732 Beta Released
Intel today released the latest version of its Arc GPU Graphics Drivers. Version 101.6732 Beta comes with optimization for The Last of Us Part II Remastered. It also comes with a performance enhancement for Call of Duty: Black Ops 6, with up to 15% performance increases to be had with "balanced" settings at 1080p. Among the issues fixed with this release are lower than expected performance with Returnal in Arc A-series and B-series discrete GPUs; a game corruption seen with FragPunk on Core Ultra Series 2 integrated graphics; a display corruption seen with Plants vs. Zombies GOTY Edition in windowed mode; and intermittent game crashes seen with Call of Duty Modern Warfare 2 Campaign Remastered.
DOWNLOAD: Intel Arc GPU Graphics Drivers 101.6732 Beta

DOWNLOAD: Intel Arc GPU Graphics Drivers 101.6732 Beta



Intel Xeon Remains Only Server CPU on MLPerf
Today, MLCommons released its latest MLPerf Inference v5.0 benchmarks, showcasing Intel Xeon 6 with Performance-cores (P-cores) across six key benchmarks. The results reveal a remarkable 1.9x boost in AI performance over the previous generation of processors, affirming Xeon 6 as a top solution for modern AI systems.
"The latest MLPerf results demonstrate Intel Xeon 6 as the ideal CPU for AI workloads, offering a perfect balance of performance and energy efficiency. Intel Xeon remains the leading CPU for AI systems, with consistent gen-over-gen performance improvements across a variety of AI benchmarks." - Karin Eibschitz Segal, Intel corporate vice president and interim general manager of the Data Center and AI Group

"The latest MLPerf results demonstrate Intel Xeon 6 as the ideal CPU for AI workloads, offering a perfect balance of performance and energy efficiency. Intel Xeon remains the leading CPU for AI systems, with consistent gen-over-gen performance improvements across a variety of AI benchmarks." - Karin Eibschitz Segal, Intel corporate vice president and interim general manager of the Data Center and AI Group


MLCommons Releases New MLPerf Inference v5.0 Benchmark Results
Today, MLCommons announced new results for its industry-standard MLPerf Inference v5.0 benchmark suite, which delivers machine learning (ML) system performance benchmarking in an architecture-neutral, representative, and reproducible manner. The results highlight that the AI community is focusing much of its attention and efforts on generative AI scenarios, and that the combination of recent hardware and software advances optimized for generative AI have led to dramatic performance improvements over the past year.
The MLPerf Inference benchmark suite, which encompasses both datacenter and edge systems, is designed to measure how quickly systems can run AI and ML models across a variety of workloads. The open-source and peer-reviewed benchmark suite creates a level playing field for competition that drives innovation, performance, and energy efficiency for the entire industry. It also provides critical technical information for customers who are procuring and tuning AI systems. This round of MLPerf Inference results also includes tests for four new benchmarks: Llama 3.1 405B, Llama 2 70B Interactive for low-latency applications, RGAT, and Automotive PointPainting for 3D object detection.
The MLPerf Inference benchmark suite, which encompasses both datacenter and edge systems, is designed to measure how quickly systems can run AI and ML models across a variety of workloads. The open-source and peer-reviewed benchmark suite creates a level playing field for competition that drives innovation, performance, and energy efficiency for the entire industry. It also provides critical technical information for customers who are procuring and tuning AI systems. This round of MLPerf Inference results also includes tests for four new benchmarks: Llama 3.1 405B, Llama 2 70B Interactive for low-latency applications, RGAT, and Automotive PointPainting for 3D object detection.


NVIDIA Blackwell Takes Pole Position in Latest MLPerf Inference Results
In the latest MLPerf Inference V5.0 benchmarks, which reflect some of the most challenging inference scenarios, the NVIDIA Blackwell platform set records - and marked NVIDIA's first MLPerf submission using the NVIDIA GB200 NVL72 system, a rack-scale solution designed for AI reasoning. Delivering on the promise of cutting-edge AI takes a new kind of compute infrastructure, called AI factories. Unlike traditional data centers, AI factories do more than store and process data - they manufacture intelligence at scale by transforming raw data into real-time insights. The goal for AI factories is simple: deliver accurate answers to queries quickly, at the lowest cost and to as many users as possible.
The complexity of pulling this off is significant and takes place behind the scenes. As AI models grow to billions and trillions of parameters to deliver smarter replies, the compute required to generate each token increases. This requirement reduces the number of tokens that an AI factory can generate and increases cost per token. Keeping inference throughput high and cost per token low requires rapid innovation across every layer of the technology stack, spanning silicon, network systems and software.

The complexity of pulling this off is significant and takes place behind the scenes. As AI models grow to billions and trillions of parameters to deliver smarter replies, the compute required to generate each token increases. This requirement reduces the number of tokens that an AI factory can generate and increases cost per token. Keeping inference throughput high and cost per token low requires rapid innovation across every layer of the technology stack, spanning silicon, network systems and software.


AMD MI300X Accelerators are Competitive with NVIDIA H100, Crunch MLPerf Inference v4.1
The MLCommons consortium on Wednesday posted MLPerf Inference v4.1 benchmark results for popular AI inferencing accelerators available in the market, across brands that include NVIDIA, AMD, and Intel. AMD's Instinct MI300X accelerators emerged competitive to NVIDIA's "Hopper" H100 series AI GPUs. AMD also used the opportunity to showcase the kind of AI inferencing performance uplifts customers can expect from its next-generation EPYC "Turin" server processors powering these MI300X machines. "Turin" features "Zen 5" CPU cores, sporting a 512-bit FPU datapath, and improved performance in AI-relevant 512-bit SIMD instruction-sets, such as AVX-512, and VNNI. The MI300X, on the other hand, banks on the strengths of its memory sub-system, FP8 data format support, and efficient KV cache management.
The MLPerf Inference v4.1 benchmark focused on the 70 billion-parameter LLaMA2-70B model. AMD's submissions included machines featuring the Instinct MI300X, powered by the current EPYC "Genoa" (Zen 4), and next-gen EPYC "Turin" (Zen 5). The GPUs are backed by AMD's ROCm open-source software stack. The benchmark evaluated inference performance using 24,576 Q&A samples from the OpenORCA dataset, with each sample containing up to 1024 input and output tokens. Two scenarios were assessed: the offline scenario, focusing on batch processing to maximize throughput in tokens per second, and the server scenario, which simulates real-time queries with strict latency limits (TTFT ≤ 2 seconds, TPOT ≤ 200 ms). This lets you see the chip's mettle in both high-throughput and low-latency queries.



The MLPerf Inference v4.1 benchmark focused on the 70 billion-parameter LLaMA2-70B model. AMD's submissions included machines featuring the Instinct MI300X, powered by the current EPYC "Genoa" (Zen 4), and next-gen EPYC "Turin" (Zen 5). The GPUs are backed by AMD's ROCm open-source software stack. The benchmark evaluated inference performance using 24,576 Q&A samples from the OpenORCA dataset, with each sample containing up to 1024 input and output tokens. Two scenarios were assessed: the offline scenario, focusing on batch processing to maximize throughput in tokens per second, and the server scenario, which simulates real-time queries with strict latency limits (TTFT ≤ 2 seconds, TPOT ≤ 200 ms). This lets you see the chip's mettle in both high-throughput and low-latency queries.




NVIDIA Blackwell Sets New Standard for Generative AI in MLPerf Inference Benchmark
As enterprises race to adopt generative AI and bring new services to market, the demands on data center infrastructure have never been greater. Training large language models is one challenge, but delivering LLM-powered real-time services is another. In the latest round of MLPerf industry benchmarks, Inference v4.1, NVIDIA platforms delivered leading performance across all data center tests. The first-ever submission of the upcoming NVIDIA Blackwell platform revealed up to 4x more performance than the NVIDIA H100 Tensor Core GPU on MLPerf's biggest LLM workload, Llama 2 70B, thanks to its use of a second-generation Transformer Engine and FP4 Tensor Cores.
The NVIDIA H200 Tensor Core GPU delivered outstanding results on every benchmark in the data center category - including the latest addition to the benchmark, the Mixtral 8x7B mixture of experts (MoE) LLM, which features a total of 46.7 billion parameters, with 12.9 billion parameters active per token. MoE models have gained popularity as a way to bring more versatility to LLM deployments, as they're capable of answering a wide variety of questions and performing more diverse tasks in a single deployment. They're also more efficient since they only activate a few experts per inference - meaning they deliver results much faster than dense models of a similar size.
The NVIDIA H200 Tensor Core GPU delivered outstanding results on every benchmark in the data center category - including the latest addition to the benchmark, the Mixtral 8x7B mixture of experts (MoE) LLM, which features a total of 46.7 billion parameters, with 12.9 billion parameters active per token. MoE models have gained popularity as a way to bring more versatility to LLM deployments, as they're capable of answering a wide variety of questions and performing more diverse tasks in a single deployment. They're also more efficient since they only activate a few experts per inference - meaning they deliver results much faster than dense models of a similar size.

Intel Xeon 6 Delivers up to 17x AI Performance Gains over 4 Years of MLPerf Results
Today, MLCommons published results of its industry-standard AI performance benchmark suite, MLPerf Inference v4.1. Intel submitted results across six MLPerf benchmarks for 5th Gen Intel Xeon Scalable processors and, for the first time, Intel Xeon 6 processors with Performance-cores (P-cores). Intel Xeon 6 processors with P-cores achieved about 1.9x geomean performance improvement in AI performance compared with 5th Gen Xeon processors.
"The newest MLPerf results show how continued investment and resourcing is critical for improving AI performance. Over the past four years, we have raised the bar for AI performance on Intel Xeon processors by up to 17x based on MLPerf. As we near general availability later this year, we look forward to ramping Xeon 6 with our customers and partners," said Pallavi Mahajan, Intel corporate vice president and general manager of Data Center and AI Software.
"The newest MLPerf results show how continued investment and resourcing is critical for improving AI performance. Over the past four years, we have raised the bar for AI performance on Intel Xeon processors by up to 17x based on MLPerf. As we near general availability later this year, we look forward to ramping Xeon 6 with our customers and partners," said Pallavi Mahajan, Intel corporate vice president and general manager of Data Center and AI Software.

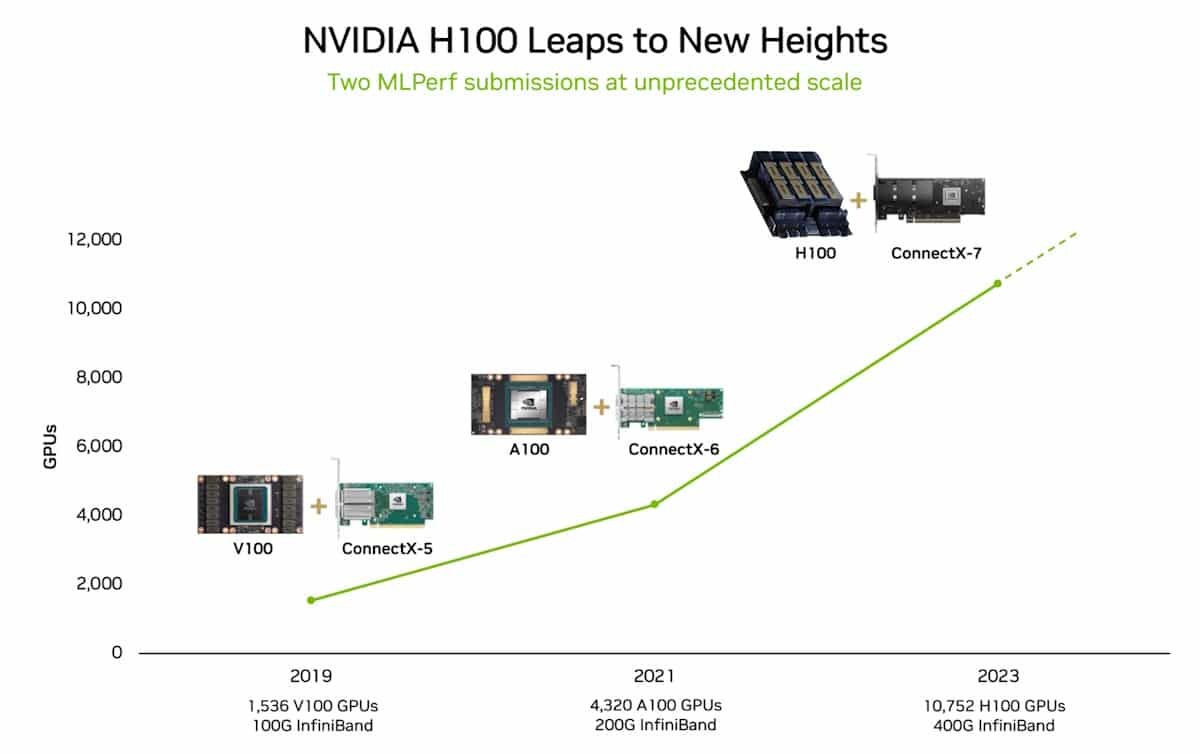
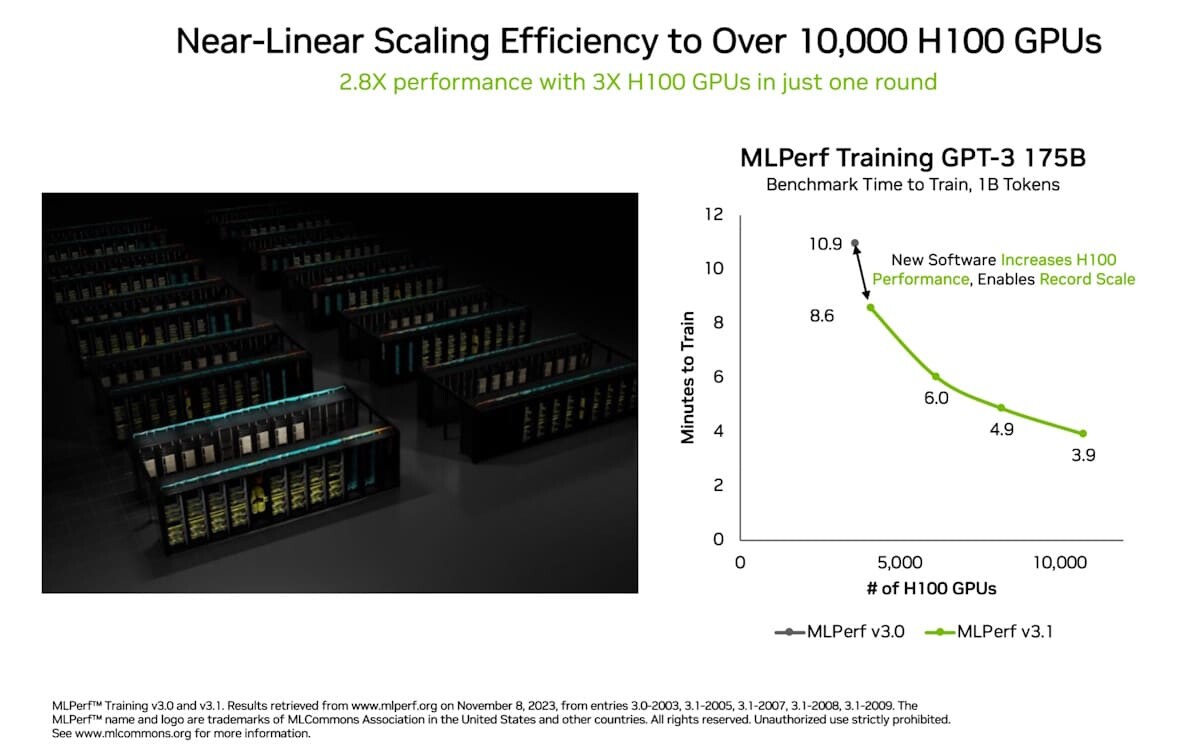
NVIDIA MLPerf Training Results Showcase Unprecedented Performance and Elasticity
The full-stack NVIDIA accelerated computing platform has once again demonstrated exceptional performance in the latest MLPerf Training v4.0 benchmarks. NVIDIA more than tripled the performance on the large language model (LLM) benchmark, based on GPT-3 175B, compared to the record-setting NVIDIA submission made last year. Using an AI supercomputer featuring 11,616 NVIDIA H100 Tensor Core GPUs connected with NVIDIA Quantum-2 InfiniBand networking, NVIDIA achieved this remarkable feat through larger scale - more than triple that of the 3,584 H100 GPU submission a year ago - and extensive full-stack engineering.
Thanks to the scalability of the NVIDIA AI platform, Eos can now train massive AI models like GPT-3 175B even faster, and this great AI performance translates into significant business opportunities. For example, in NVIDIA's recent earnings call, we described how LLM service providers can turn a single dollar invested into seven dollars in just four years running the Llama 3 70B model on NVIDIA HGX H200 servers. This return assumes an LLM service provider serving Llama 3 70B at $0.60/M tokens, with an HGX H200 server throughput of 24,000 tokens/second.
Thanks to the scalability of the NVIDIA AI platform, Eos can now train massive AI models like GPT-3 175B even faster, and this great AI performance translates into significant business opportunities. For example, in NVIDIA's recent earnings call, we described how LLM service providers can turn a single dollar invested into seven dollars in just four years running the Llama 3 70B model on NVIDIA HGX H200 servers. This return assumes an LLM service provider serving Llama 3 70B at $0.60/M tokens, with an HGX H200 server throughput of 24,000 tokens/second.

Intel Submits Gaudi 2 Results on MLCommons' Newest Benchmark
Today, MLCommons published results of its industry AI performance benchmark, MLPerf Training v4.0. Intel's results demonstrate the choice that Intel Gaudi 2 AI accelerators give enterprises and customers. Community-based software simplifies generative AI (GenAI) development and industry-standard Ethernet networking enables flexible scaling of AI systems. For the first time on the MLPerf benchmark, Intel submitted results on a large Gaudi 2 system (1,024 Gaudi 2 accelerators) trained in Intel Tiber Developer Cloud to demonstrate Gaudi 2 performance and scalability and Intel's cloud capacity for training MLPerf's GPT-3 175B1 parameter benchmark model.
"The industry has a clear need: address the gaps in today's generative AI enterprise offerings with high-performance, high-efficiency compute options. The latest MLPerf results published by MLCommons illustrate the unique value Intel Gaudi brings to market as enterprises and customers seek more cost-efficient, scalable systems with standard networking and open software, making GenAI more accessible to more customers," said Zane Ball, Intel corporate vice president and general manager, DCAI Product Management.
"The industry has a clear need: address the gaps in today's generative AI enterprise offerings with high-performance, high-efficiency compute options. The latest MLPerf results published by MLCommons illustrate the unique value Intel Gaudi brings to market as enterprises and customers seek more cost-efficient, scalable systems with standard networking and open software, making GenAI more accessible to more customers," said Zane Ball, Intel corporate vice president and general manager, DCAI Product Management.

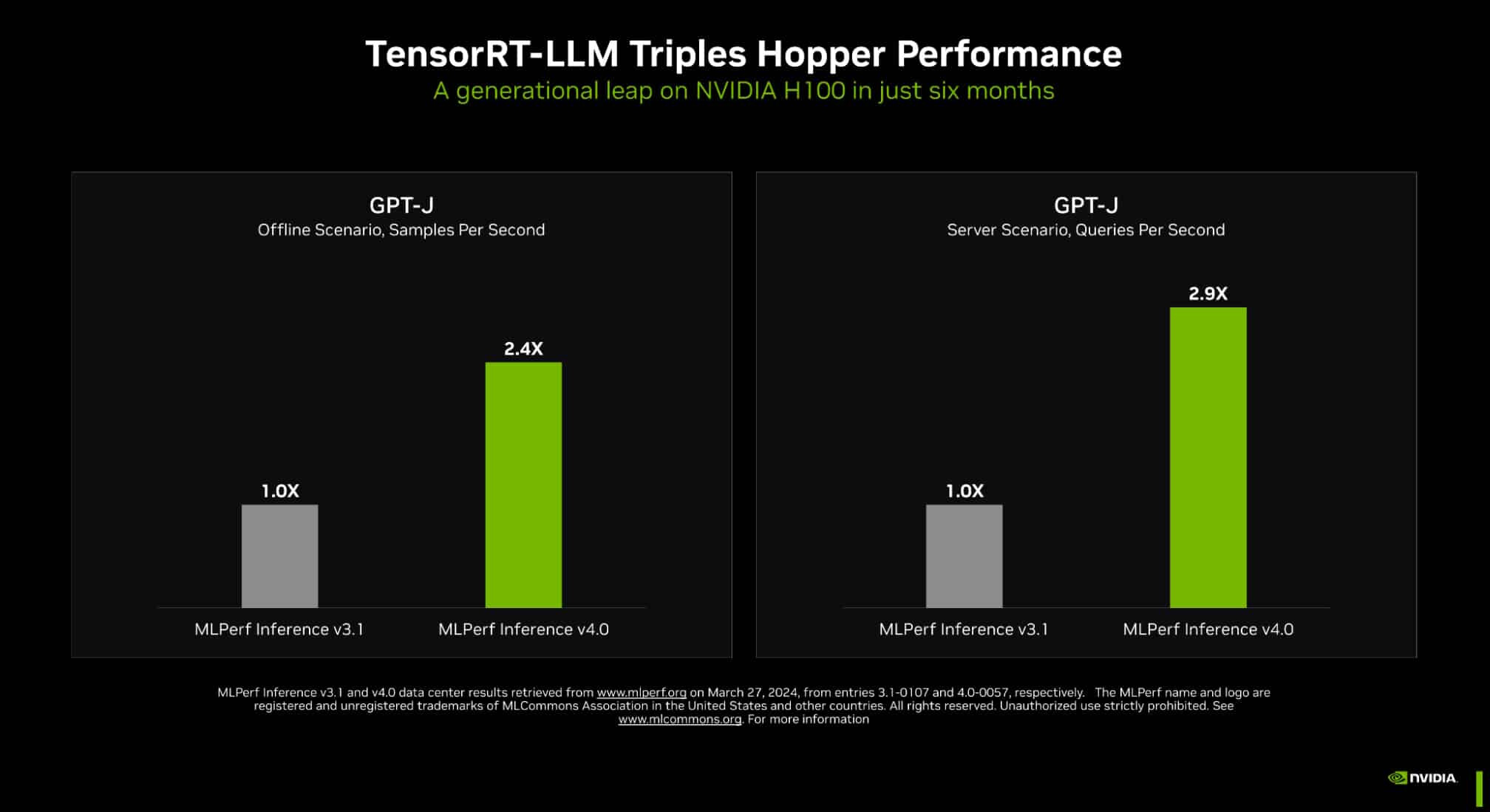
NVIDIA Hopper Leaps Ahead in Generative AI at MLPerf
It's official: NVIDIA delivered the world's fastest platform in industry-standard tests for inference on generative AI. In the latest MLPerf benchmarks, NVIDIA TensorRT-LLM—software that speeds and simplifies the complex job of inference on large language models—boosted the performance of NVIDIA Hopper architecture GPUs on the GPT-J LLM nearly 3x over their results just six months ago. The dramatic speedup demonstrates the power of NVIDIA's full-stack platform of chips, systems and software to handle the demanding requirements of running generative AI. Leading companies are using TensorRT-LLM to optimize their models. And NVIDIA NIM—a set of inference microservices that includes inferencing engines like TensorRT-LLM—makes it easier than ever for businesses to deploy NVIDIA's inference platform.
Raising the Bar in Generative AI
TensorRT-LLM running on NVIDIA H200 Tensor Core GPUs—the latest, memory-enhanced Hopper GPUs—delivered the fastest performance running inference in MLPerf's biggest test of generative AI to date. The new benchmark uses the largest version of Llama 2, a state-of-the-art large language model packing 70 billion parameters. The model is more than 10x larger than the GPT-J LLM first used in the September benchmarks. The memory-enhanced H200 GPUs, in their MLPerf debut, used TensorRT-LLM to produce up to 31,000 tokens/second, a record on MLPerf's Llama 2 benchmark. The H200 GPU results include up to 14% gains from a custom thermal solution. It's one example of innovations beyond standard air cooling that systems builders are applying to their NVIDIA MGX designs to take the performance of Hopper GPUs to new heights.


Raising the Bar in Generative AI
TensorRT-LLM running on NVIDIA H200 Tensor Core GPUs—the latest, memory-enhanced Hopper GPUs—delivered the fastest performance running inference in MLPerf's biggest test of generative AI to date. The new benchmark uses the largest version of Llama 2, a state-of-the-art large language model packing 70 billion parameters. The model is more than 10x larger than the GPT-J LLM first used in the September benchmarks. The memory-enhanced H200 GPUs, in their MLPerf debut, used TensorRT-LLM to produce up to 31,000 tokens/second, a record on MLPerf's Llama 2 benchmark. The H200 GPU results include up to 14% gains from a custom thermal solution. It's one example of innovations beyond standard air cooling that systems builders are applying to their NVIDIA MGX designs to take the performance of Hopper GPUs to new heights.


Intel Gaudi 2 Remains Only Benchmarked Alternative to NV H100 for Generative AI Performance
Today, MLCommons published results of the industry-standard MLPerf v4.0 benchmark for inference. Intel's results for Intel Gaudi 2 accelerators and 5th Gen Intel Xeon Scalable processors with Intel Advanced Matrix Extensions (Intel AMX) reinforce the company's commitment to bring "AI Everywhere" with a broad portfolio of competitive solutions. The Intel Gaudi 2 AI accelerator remains the only benchmarked alternative to Nvidia H100 for generative AI (GenAI) performance and provides strong performance-per-dollar. Further, Intel remains the only server CPU vendor to submit MLPerf results. Intel's 5th Gen Xeon results improved by an average of 1.42x compared with 4th Gen Intel Xeon processors' results in MLPerf Inference v3.1.
"We continue to improve AI performance on industry-standard benchmarks across our portfolio of accelerators and CPUs. Today's results demonstrate that we are delivering AI solutions that deliver to our customers' dynamic and wide-ranging AI requirements. Both Intel Gaudi and Xeon products provide our customers with options that are ready to deploy and offer strong price-to-performance advantages," said Zane Ball, Intel corporate vice president and general manager, DCAI Product Management.

"We continue to improve AI performance on industry-standard benchmarks across our portfolio of accelerators and CPUs. Today's results demonstrate that we are delivering AI solutions that deliver to our customers' dynamic and wide-ranging AI requirements. Both Intel Gaudi and Xeon products provide our customers with options that are ready to deploy and offer strong price-to-performance advantages," said Zane Ball, Intel corporate vice president and general manager, DCAI Product Management.


Tiny Corp. Prepping Separate AMD & NVIDIA GPU-based AI Compute Systems
George Hotz and his startup operation (Tiny Corporation) appeared ready to completely abandon AMD Radeon GPUs last week, after experiencing a period of firmware-related headaches. The original plan involved the development of a pre-orderable $15,000 TinyBox AI compute cluster that housed six XFX Speedster MERC310 RX 7900 XTX graphics cards, but software/driver issues prompted experimentation via alternative hardware routes. A lot of media coverage has focused on the unusual adoption of consumer-grade GPUs—Tiny Corp.'s struggles with RDNA 3 (rather than CDNA 3) were maneuvered further into public view, after top AMD brass pitched in.
The startup's social media feed is very transparent about showcasing everyday tasks, problem-solving and important decision-making. Several Acer Predator BiFrost Arc A770 OC cards were purchased and promptly integrated into a colorfully-lit TinyBox prototype, but Hotz & Co. swiftly moved onto Team Green pastures. Tiny Corp. has begrudgingly adopted NVIDIA GeForce RTX 4090 GPUs. Earlier today, it was announced that work on the AMD-based system has resumed—although customers were forewarned about anticipated teething problems. The surprising message arrived in the early hours: "a hard to find 'umr' repo has turned around the feasibility of the AMD TinyBox. It will be a journey, but it gives us an ability to debug. We're going to sell both, red for $15,000 and green for $25,000. When you realize your pre-order you'll choose your color. Website has been updated. If you like to tinker and feel pain, buy red. The driver still crashes the GPU and hangs sometimes, but we can work together to improve it."



The startup's social media feed is very transparent about showcasing everyday tasks, problem-solving and important decision-making. Several Acer Predator BiFrost Arc A770 OC cards were purchased and promptly integrated into a colorfully-lit TinyBox prototype, but Hotz & Co. swiftly moved onto Team Green pastures. Tiny Corp. has begrudgingly adopted NVIDIA GeForce RTX 4090 GPUs. Earlier today, it was announced that work on the AMD-based system has resumed—although customers were forewarned about anticipated teething problems. The surprising message arrived in the early hours: "a hard to find 'umr' repo has turned around the feasibility of the AMD TinyBox. It will be a journey, but it gives us an ability to debug. We're going to sell both, red for $15,000 and green for $25,000. When you realize your pre-order you'll choose your color. Website has been updated. If you like to tinker and feel pain, buy red. The driver still crashes the GPU and hangs sometimes, but we can work together to improve it."



NVIDIA Grace Hopper Systems Gather at GTC
The spirit of software pioneer Grace Hopper will live on at NVIDIA GTC. Accelerated systems using powerful processors - named in honor of the pioneer of software programming - will be on display at the global AI conference running March 18-21, ready to take computing to the next level. System makers will show more than 500 servers in multiple configurations across 18 racks, all packing NVIDIA GH200 Grace Hopper Superchips. They'll form the largest display at NVIDIA's booth in the San Jose Convention Center, filling the MGX Pavilion.
MGX Speeds Time to Market
NVIDIA MGX is a blueprint for building accelerated servers with any combination of GPUs, CPUs and data processing units (DPUs) for a wide range of AI, high performance computing and NVIDIA Omniverse applications. It's a modular reference architecture for use across multiple product generations and workloads. GTC attendees can get an up-close look at MGX models tailored for enterprise, cloud and telco-edge uses, such as generative AI inference, recommenders and data analytics. The pavilion will showcase accelerated systems packing single and dual GH200 Superchips in 1U and 2U chassis, linked via NVIDIA BlueField-3 DPUs and NVIDIA Quantum-2 400 Gb/s InfiniBand networks over LinkX cables and transceivers. The systems support industry standards for 19- and 21-inch rack enclosures, and many provide E1.S bays for nonvolatile storage.
MGX Speeds Time to Market
NVIDIA MGX is a blueprint for building accelerated servers with any combination of GPUs, CPUs and data processing units (DPUs) for a wide range of AI, high performance computing and NVIDIA Omniverse applications. It's a modular reference architecture for use across multiple product generations and workloads. GTC attendees can get an up-close look at MGX models tailored for enterprise, cloud and telco-edge uses, such as generative AI inference, recommenders and data analytics. The pavilion will showcase accelerated systems packing single and dual GH200 Superchips in 1U and 2U chassis, linked via NVIDIA BlueField-3 DPUs and NVIDIA Quantum-2 400 Gb/s InfiniBand networks over LinkX cables and transceivers. The systems support industry standards for 19- and 21-inch rack enclosures, and many provide E1.S bays for nonvolatile storage.

Intel Accelerates AI Everywhere with Launch of Powerful Next-Gen Products
At its "AI Everywhere" launch in New York City today, Intel introduced an unmatched portfolio of AI products to enable customers' AI solutions everywhere—across the data center, cloud, network, edge and PC. "AI innovation is poised to raise the digital economy's impact up to as much as one-third of global gross domestic product," Gelsinger said. "Intel is developing the technologies and solutions that empower customers to seamlessly integrate and effectively run AI in all their applications—in the cloud and, increasingly, locally at the PC and edge, where data is generated and used."
Gelsinger showcased Intel's expansive AI footprint, spanning cloud and enterprise servers to networks, volume clients and ubiquitous edge environments. He also reinforced that Intel is on track to deliver five new process technology nodes in four years. "Intel is on a mission to bring AI everywhere through exceptionally engineered platforms, secure solutions and support for open ecosystems. Our AI portfolio gets even stronger with today's launch of Intel Core Ultra ushering in the age of the AI PC and AI-accelerated 5th Gen Xeon for the enterprise," Gelsinger said.




Gelsinger showcased Intel's expansive AI footprint, spanning cloud and enterprise servers to networks, volume clients and ubiquitous edge environments. He also reinforced that Intel is on track to deliver five new process technology nodes in four years. "Intel is on a mission to bring AI everywhere through exceptionally engineered platforms, secure solutions and support for open ecosystems. Our AI portfolio gets even stronger with today's launch of Intel Core Ultra ushering in the age of the AI PC and AI-accelerated 5th Gen Xeon for the enterprise," Gelsinger said.





NVIDIA Turbocharges Generative AI Training in MLPerf Benchmarks
NVIDIA's AI platform raised the bar for AI training and high performance computing in the latest MLPerf industry benchmarks. Among many new records and milestones, one in generative AI stands out: NVIDIA Eos - an AI supercomputer powered by a whopping 10,752 NVIDIA H100 Tensor Core GPUs and NVIDIA Quantum-2 InfiniBand networking - completed a training benchmark based on a GPT-3 model with 175 billion parameters trained on one billion tokens in just 3.9 minutes. That's a nearly 3x gain from 10.9 minutes, the record NVIDIA set when the test was introduced less than six months ago.
The benchmark uses a portion of the full GPT-3 data set behind the popular ChatGPT service that, by extrapolation, Eos could now train in just eight days, 73x faster than a prior state-of-the-art system using 512 A100 GPUs. The acceleration in training time reduces costs, saves energy and speeds time-to-market. It's heavy lifting that makes large language models widely available so every business can adopt them with tools like NVIDIA NeMo, a framework for customizing LLMs. In a new generative AI test this round, 1,024 NVIDIA Hopper architecture GPUs completed a training benchmark based on the Stable Diffusion text-to-image model in 2.5 minutes, setting a high bar on this new workload. By adopting these two tests, MLPerf reinforces its leadership as the industry standard for measuring AI performance, since generative AI is the most transformative technology of our time.



The benchmark uses a portion of the full GPT-3 data set behind the popular ChatGPT service that, by extrapolation, Eos could now train in just eight days, 73x faster than a prior state-of-the-art system using 512 A100 GPUs. The acceleration in training time reduces costs, saves energy and speeds time-to-market. It's heavy lifting that makes large language models widely available so every business can adopt them with tools like NVIDIA NeMo, a framework for customizing LLMs. In a new generative AI test this round, 1,024 NVIDIA Hopper architecture GPUs completed a training benchmark based on the Stable Diffusion text-to-image model in 2.5 minutes, setting a high bar on this new workload. By adopting these two tests, MLPerf reinforces its leadership as the industry standard for measuring AI performance, since generative AI is the most transformative technology of our time.


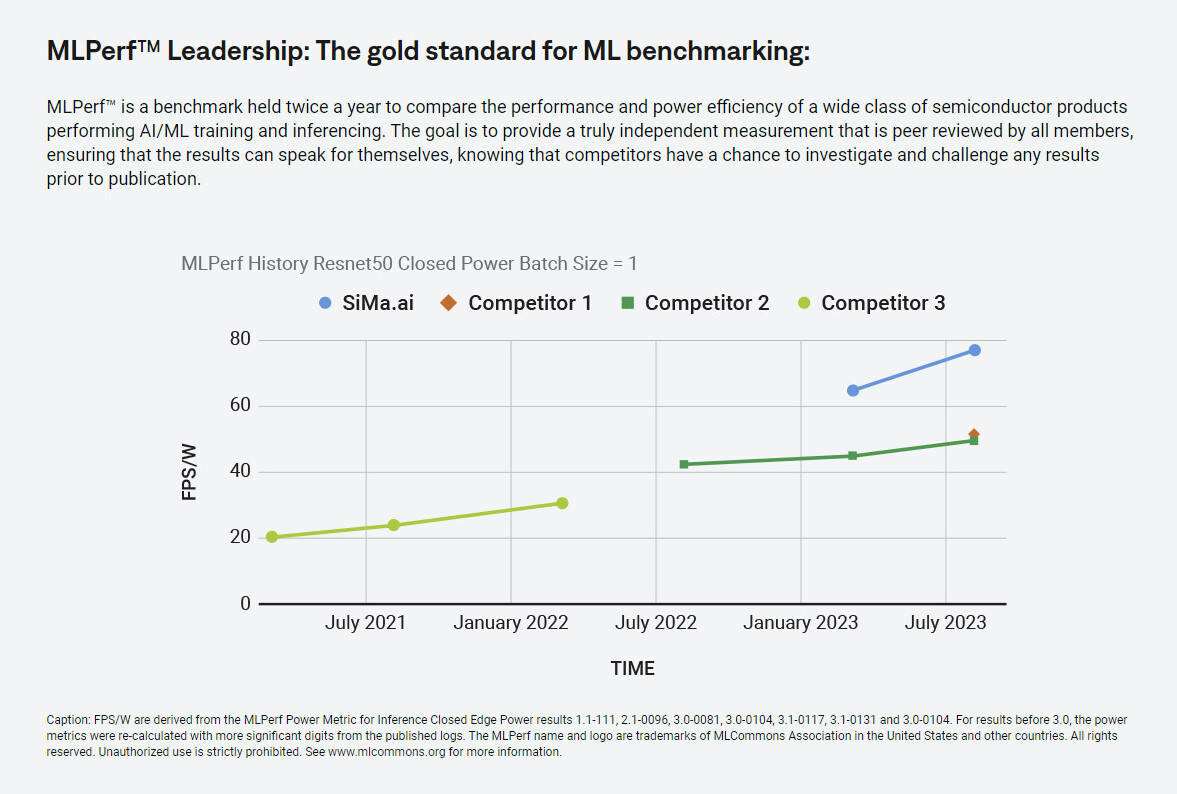
SiMa.ai Surpasses NVIDIA Again in MLPerf Closed Edge ResNet50 Benchmark
SiMa.ai, the machine learning company delivering solutions for the embedded edge, today announced the results of its second MLPerf submission, outperforming industry ML leader, NVIDIA's Orin NX and AGX Orin in the Closed Edge power category in the MLCommons ML Perf 3.1 benchmark. SiMa.ai participated in the MLPerf Inference 3.1 closed, edge, power division of this benchmarking process, focusing on the image classification benchmark Resnet50. Since the company's prior submission in April 2023, SiMa.ai achieved a 20 percent improvement in its results for Single Stream Resnet50 for performance and power, while exhibiting up to 85 percent greater Resnet50 MultiStream efficiency compared to NVIDIA. With frames per second per watt as the defacto performance standard for edge AI and ML, these results demonstrate SiMa.ai's pushbutton approach drives continued leadership in unrivaled power efficiency that does not compromise performance.
"Outperforming the industry leader not only once, but again for a second time is great validation for our technology. Our team at SiMa.ai will persistently pursue performance per watt leadership and new standards in ease of use for the embedded edge market as part of our core DNA," said Krishna Rangasayee, CEO and founder, SiMa.ai. "We are proud of the SiMa.ai team's leadership in the latest MLPerf benchmark and excited to extend these latest improvements to our customers' real-world needs and use cases."

"Outperforming the industry leader not only once, but again for a second time is great validation for our technology. Our team at SiMa.ai will persistently pursue performance per watt leadership and new standards in ease of use for the embedded edge market as part of our core DNA," said Krishna Rangasayee, CEO and founder, SiMa.ai. "We are proud of the SiMa.ai team's leadership in the latest MLPerf benchmark and excited to extend these latest improvements to our customers' real-world needs and use cases."

Intel Shows Strong AI Inference Performance
Today, MLCommons published results of its MLPerf Inference v3.1 performance benchmark for GPT-J, the 6 billion parameter large language model, as well as computer vision and natural language processing models. Intel submitted results for Habana Gaudi 2 accelerators, 4th Gen Intel Xeon Scalable processors, and Intel Xeon CPU Max Series. The results show Intel's competitive performance for AI inference and reinforce the company's commitment to making artificial intelligence more accessible at scale across the continuum of AI workloads - from client and edge to the network and cloud.
"As demonstrated through the recent MLCommons results, we have a strong, competitive AI product portfolio, designed to meet our customers' needs for high-performance, high-efficiency deep learning inference and training, for the complete spectrum of AI models - from the smallest to the largest - with leading price/performance." -Sandra Rivera, Intel executive vice president and general manager of the Data Center and AI Group

"As demonstrated through the recent MLCommons results, we have a strong, competitive AI product portfolio, designed to meet our customers' needs for high-performance, high-efficiency deep learning inference and training, for the complete spectrum of AI models - from the smallest to the largest - with leading price/performance." -Sandra Rivera, Intel executive vice president and general manager of the Data Center and AI Group


NVIDIA GH200 Superchip Aces MLPerf Inference Benchmarks
In its debut on the MLPerf industry benchmarks, the NVIDIA GH200 Grace Hopper Superchip ran all data center inference tests, extending the leading performance of NVIDIA H100 Tensor Core GPUs. The overall results showed the exceptional performance and versatility of the NVIDIA AI platform from the cloud to the network's edge. Separately, NVIDIA announced inference software that will give users leaps in performance, energy efficiency and total cost of ownership.
GH200 Superchips Shine in MLPerf
The GH200 links a Hopper GPU with a Grace CPU in one superchip. The combination provides more memory, bandwidth and the ability to automatically shift power between the CPU and GPU to optimize performance. Separately, NVIDIA HGX H100 systems that pack eight H100 GPUs delivered the highest throughput on every MLPerf Inference test in this round. Grace Hopper Superchips and H100 GPUs led across all MLPerf's data center tests, including inference for computer vision, speech recognition and medical imaging, in addition to the more demanding use cases of recommendation systems and the large language models (LLMs) used in generative AI.
GH200 Superchips Shine in MLPerf
The GH200 links a Hopper GPU with a Grace CPU in one superchip. The combination provides more memory, bandwidth and the ability to automatically shift power between the CPU and GPU to optimize performance. Separately, NVIDIA HGX H100 systems that pack eight H100 GPUs delivered the highest throughput on every MLPerf Inference test in this round. Grace Hopper Superchips and H100 GPUs led across all MLPerf's data center tests, including inference for computer vision, speech recognition and medical imaging, in addition to the more demanding use cases of recommendation systems and the large language models (LLMs) used in generative AI.

NVIDIA H100 Tensor Core GPU Used on New Azure Virtual Machine Series Now Available
Microsoft Azure users can now turn to the latest NVIDIA accelerated computing technology to train and deploy their generative AI applications. Available today, the Microsoft Azure ND H100 v5 VMs using NVIDIA H100 Tensor Core GPUs and NVIDIA Quantum-2 InfiniBand networking—enables scaling generative AI, high performance computing (HPC) and other applications with a click from a browser. Available to customers across the U.S., the new instance arrives as developers and researchers are using large language models (LLMs) and accelerated computing to uncover new consumer and business use cases.
The NVIDIA H100 GPU delivers supercomputing-class performance through architectural innovations, including fourth-generation Tensor Cores, a new Transformer Engine for accelerating LLMs and the latest NVLink technology that lets GPUs talk to each other at 900 GB/s. The inclusion of NVIDIA Quantum-2 CX7 InfiniBand with 3,200 Gbps cross-node bandwidth ensures seamless performance across the GPUs at massive scale, matching the capabilities of top-performing supercomputers globally.
The NVIDIA H100 GPU delivers supercomputing-class performance through architectural innovations, including fourth-generation Tensor Cores, a new Transformer Engine for accelerating LLMs and the latest NVLink technology that lets GPUs talk to each other at 900 GB/s. The inclusion of NVIDIA Quantum-2 CX7 InfiniBand with 3,200 Gbps cross-node bandwidth ensures seamless performance across the GPUs at massive scale, matching the capabilities of top-performing supercomputers globally.


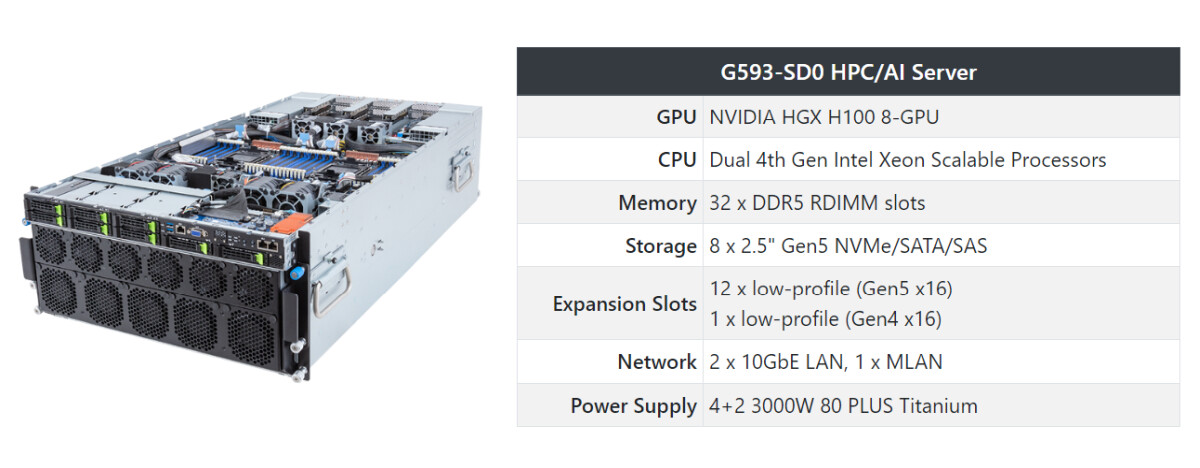
GIGABYTE Leads MLPerf Training v3.0 Benchmarks with Top-Performing Accelerators in GIGABYTE Servers
GIGABYTE Technology: The latest MLPerf Training v3.0 benchmark results are out, and the GIGABYTE G593-SD0 server has emerged as a leader in this round of testing. Going head-to-head against impressive systems, GIGABYTE's servers secured top positions in various categories, showcasing their prowess in handling real-world machine learning use cases. With an unparalleled focus on performance, efficiency, and reliability, GIGABYTE has once again proven its commitment to driving progress in the field of AI.
GIGABYTE, one of the founding members of MLCommons, has been actively contributing to the organization's efforts in designing and planning systems to benchmark fairly. Understanding the importance of replicating real-world scenarios in AI development, GIGABYTE's collaboration with MLCommons has been instrumental in shaping the benchmark tasks to encompass critical use cases such as image recognition, object detection, speech-to-text, natural language processing, and recommendation engines. By actively engaging with end applications, GIGABYTE ensures that its servers are designed to meet the highest standards, delivering supreme performance, and facilitating meaningful comparisons between different ML systems.

GIGABYTE, one of the founding members of MLCommons, has been actively contributing to the organization's efforts in designing and planning systems to benchmark fairly. Understanding the importance of replicating real-world scenarios in AI development, GIGABYTE's collaboration with MLCommons has been instrumental in shaping the benchmark tasks to encompass critical use cases such as image recognition, object detection, speech-to-text, natural language processing, and recommendation engines. By actively engaging with end applications, GIGABYTE ensures that its servers are designed to meet the highest standards, delivering supreme performance, and facilitating meaningful comparisons between different ML systems.

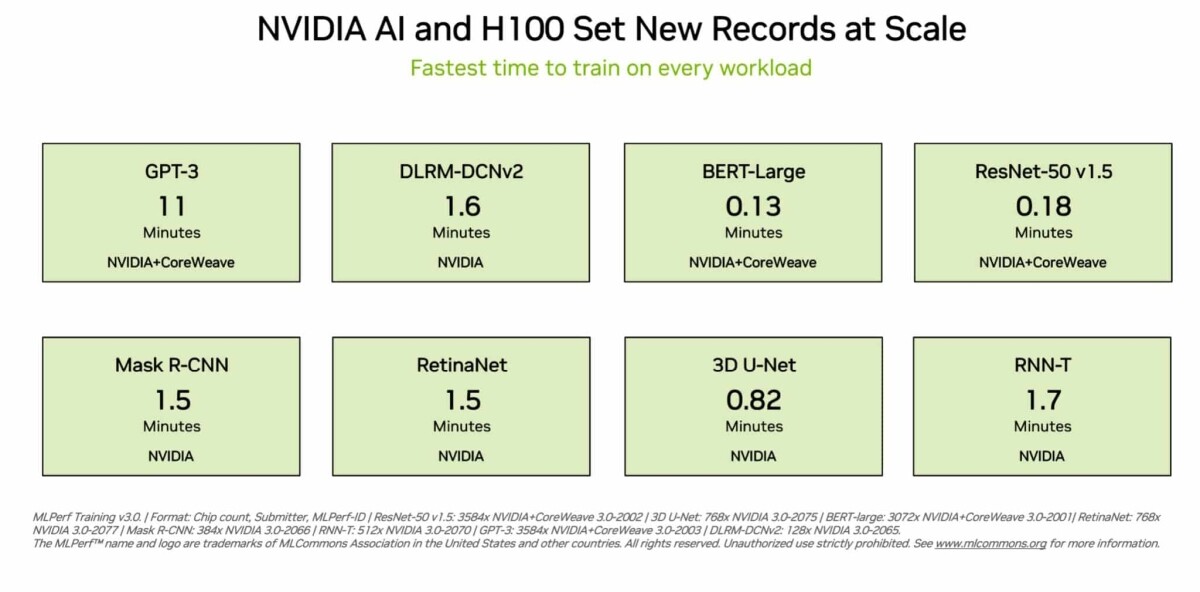
NVIDIA H100 GPUs Set Standard for Generative AI in Debut MLPerf Benchmark
In a new industry-standard benchmark, a cluster of 3,584 H100 GPUs at cloud service provider CoreWeave trained a massive GPT-3-based model in just 11 minutes. Leading users and industry-standard benchmarks agree: NVIDIA H100 Tensor Core GPUs deliver the best AI performance, especially on the large language models (LLMs) powering generative AI.
H100 GPUs set new records on all eight tests in the latest MLPerf training benchmarks released today, excelling on a new MLPerf test for generative AI. That excellence is delivered both per-accelerator and at-scale in massive servers. For example, on a commercially available cluster of 3,584 H100 GPUs co-developed by startup Inflection AI and operated by CoreWeave, a cloud service provider specializing in GPU-accelerated workloads, the system completed the massive GPT-3-based training benchmark in less than eleven minutes.


H100 GPUs set new records on all eight tests in the latest MLPerf training benchmarks released today, excelling on a new MLPerf test for generative AI. That excellence is delivered both per-accelerator and at-scale in massive servers. For example, on a commercially available cluster of 3,584 H100 GPUs co-developed by startup Inflection AI and operated by CoreWeave, a cloud service provider specializing in GPU-accelerated workloads, the system completed the massive GPT-3-based training benchmark in less than eleven minutes.


MLCommons Shares Intel Habana Gaudi2 and 4th Gen Intel Xeon Scalable AI Benchmark Results
Today, MLCommons published results of its industry AI performance benchmark, MLPerf Training 3.0, in which both the Habana Gaudi2 deep learning accelerator and the 4th Gen Intel Xeon Scalable processor delivered impressive training results.
"The latest MLPerf results published by MLCommons validates the TCO value Intel Xeon processors and Intel Gaudi deep learning accelerators provide to customers in the area of AI. Xeon's built-in accelerators make it an ideal solution to run volume AI workloads on general-purpose processors, while Gaudi delivers competitive performance for large language models and generative AI. Intel's scalable systems with optimized, easy-to-program open software lowers the barrier for customers and partners to deploy a broad array of AI-based solutions in the data center from the cloud to the intelligent edge." - Sandra Rivera, Intel executive vice president and general manager of the Data Center and AI Group

"The latest MLPerf results published by MLCommons validates the TCO value Intel Xeon processors and Intel Gaudi deep learning accelerators provide to customers in the area of AI. Xeon's built-in accelerators make it an ideal solution to run volume AI workloads on general-purpose processors, while Gaudi delivers competitive performance for large language models and generative AI. Intel's scalable systems with optimized, easy-to-program open software lowers the barrier for customers and partners to deploy a broad array of AI-based solutions in the data center from the cloud to the intelligent edge." - Sandra Rivera, Intel executive vice president and general manager of the Data Center and AI Group


Apr 6th, 2025 15:30 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- How I made an Ultimate Cooling Guide (18)
- The easiest way to connect the BOOTSEL test metal terminal and the GND terminal.... (0)
- What local LLM-s you use? (147)
- All Intel DG1 needs special bios? (30)
- Regarding Arctic's new Lineup of MAX fans! (1)
- TPU's F@H Team (20421)
- RX 9000 series GPU Owners Club (192)
- Clicks & Pops in Mic Audio due to buffer underruns. Please send help. (0)
- What are you playing? (23348)
- 9070XT or 7900XT (25)
Popular Reviews
- ASUS Prime X870-P Wi-Fi Review
- UPERFECT UStation Delta Max Review - Two Screens In One
- PowerColor Radeon RX 9070 Hellhound Review
- Corsair RM750x Shift 750 W Review
- DDR5 CUDIMM Explained & Benched - The New Memory Standard
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Pwnage Trinity CF Review
Controversial News Posts
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (124)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (97)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (92)