Moore Threads Teases Excellent Performance of DeepSeek-R1 Model on MTT GPUs
Moore Threads, a Chinese manufacturer of proprietary GPU designs is (reportedly) the latest company to jump onto the DeepSeek-R1 bandwagon. Since late January, NVIDIA, Microsoft and AMD have swooped in with their own interpretations/deployments. By global standards, Moore Threads GPUs trail behind Western-developed offerings—early 2024 evaluations presented the firm's MTT S80 dedicated desktop graphics card struggling against an AMD integrated solution: Radeon 760M. The recent emergence of DeepSeek's open source models has signalled a shift away from reliance on extremely powerful and expensive AI-crunching hardware (often accessed via the cloud)—widespread excitement has been generated by DeepSeek solutions being relatively frugal, in terms of processing requirements. Tom's Hardware has observed cases of open source AI models running (locally) on: "inexpensive hardware, like the Raspberry Pi."
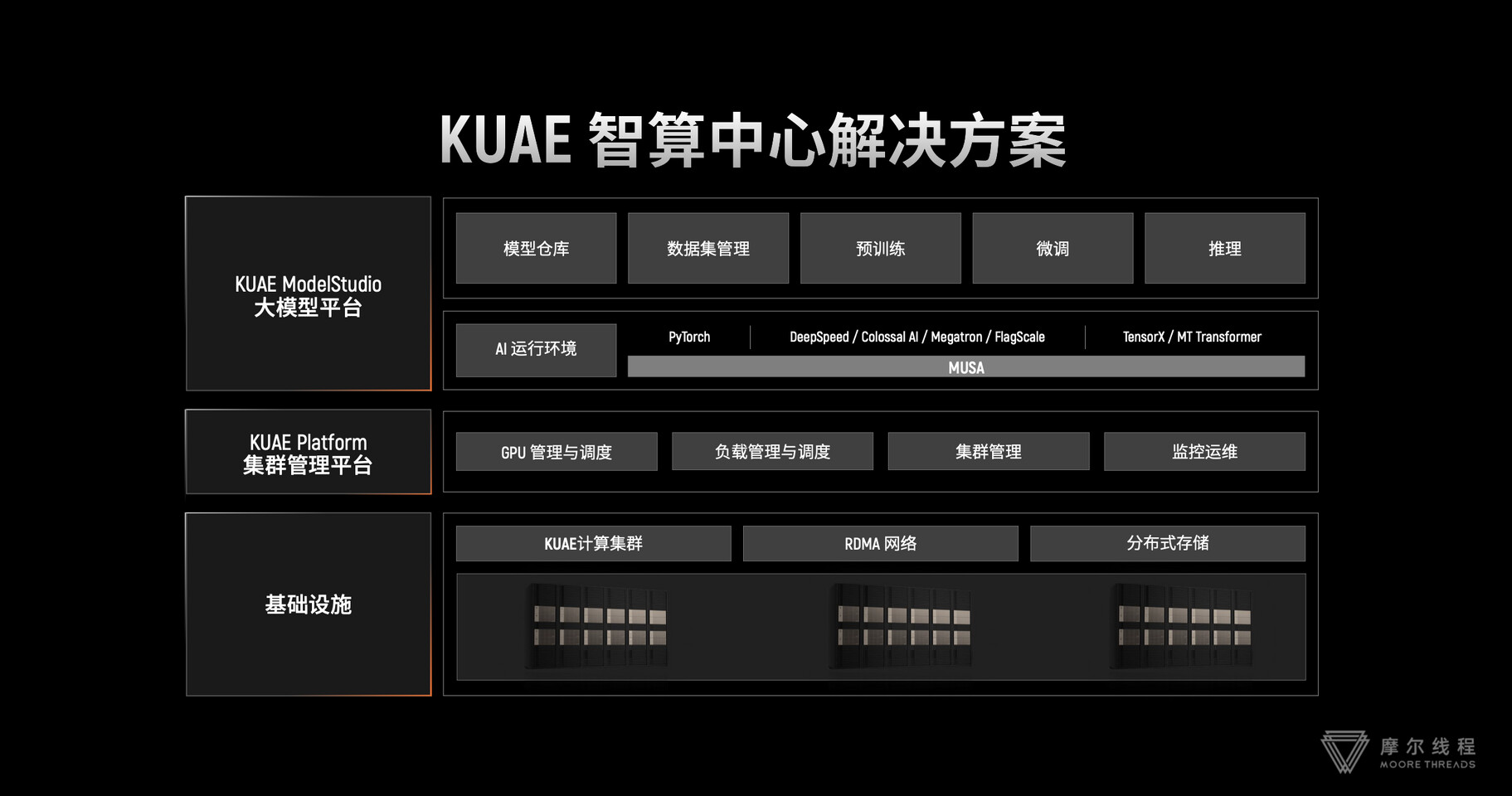
According to recent Chinese press coverage, Moore Threads has announced a successful deployment of DeepSeek's R1-Distill-Qwen-7B distilled model on the aforementioned MTT S80 GPU. The company also revealed that it had taken similar steps with its MTT S4000 datacenter-oriented graphics hardware. On the subject of adaptation, a Moore Threads spokesperson stated: "based on the Ollama open source framework, Moore Threads completed the deployment of the DeepSeek-R1-Distill-Qwen-7B distillation model and demonstrated excellent performance in a variety of Chinese tasks, verifying the versatility and CUDA compatibility of Moore Threads' self-developed full-featured GPU." Exact performance figures, benchmark results and technical details were not disclosed to the Chinese public, so Moore Threads appears to be teasing the prowess of its MTT GPU designs. ITHome reported that: "users can also perform inference deployment of the DeepSeek-R1 distillation model based on MTT S80 and MTT S4000. Some users have previously completed the practice manually on MTT S80." Moore Threads believes that its: "self-developed high-performance inference engine, combined with software and hardware co-optimization technology, significantly improves the model's computing efficiency and resource utilization through customized operator acceleration and memory management. This engine not only supports the efficient operation of the DeepSeek distillation model, but also provides technical support for the deployment of more large-scale models in the future."


According to recent Chinese press coverage, Moore Threads has announced a successful deployment of DeepSeek's R1-Distill-Qwen-7B distilled model on the aforementioned MTT S80 GPU. The company also revealed that it had taken similar steps with its MTT S4000 datacenter-oriented graphics hardware. On the subject of adaptation, a Moore Threads spokesperson stated: "based on the Ollama open source framework, Moore Threads completed the deployment of the DeepSeek-R1-Distill-Qwen-7B distillation model and demonstrated excellent performance in a variety of Chinese tasks, verifying the versatility and CUDA compatibility of Moore Threads' self-developed full-featured GPU." Exact performance figures, benchmark results and technical details were not disclosed to the Chinese public, so Moore Threads appears to be teasing the prowess of its MTT GPU designs. ITHome reported that: "users can also perform inference deployment of the DeepSeek-R1 distillation model based on MTT S80 and MTT S4000. Some users have previously completed the practice manually on MTT S80." Moore Threads believes that its: "self-developed high-performance inference engine, combined with software and hardware co-optimization technology, significantly improves the model's computing efficiency and resource utilization through customized operator acceleration and memory management. This engine not only supports the efficient operation of the DeepSeek distillation model, but also provides technical support for the deployment of more large-scale models in the future."