NVIDIA cuLitho Computational Lithography Platform is Moving to Production at TSMC
TSMC, the world leader in semiconductor manufacturing, is moving to production with NVIDIA's computational lithography platform, called cuLitho, to accelerate manufacturing and push the limits of physics for the next generation of advanced semiconductor chips. A critical step in the manufacture of computer chips, computational lithography is involved in the transfer of circuitry onto silicon. It requires complex computation - involving electromagnetic physics, photochemistry, computational geometry, iterative optimization and distributed computing. A typical foundry dedicates massive data centers for this computation, and yet this step has traditionally been a bottleneck in bringing new technology nodes and computer architectures to market.
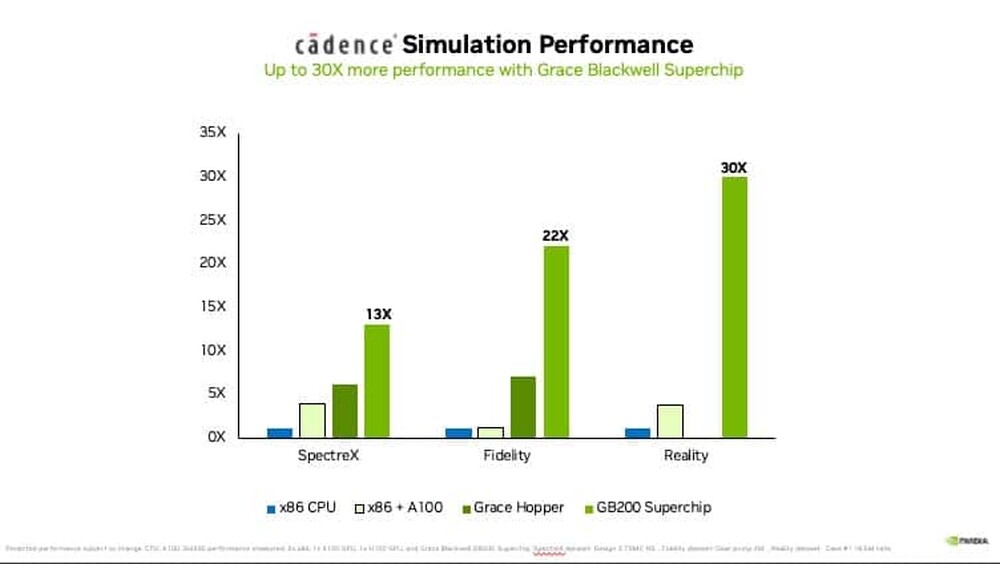
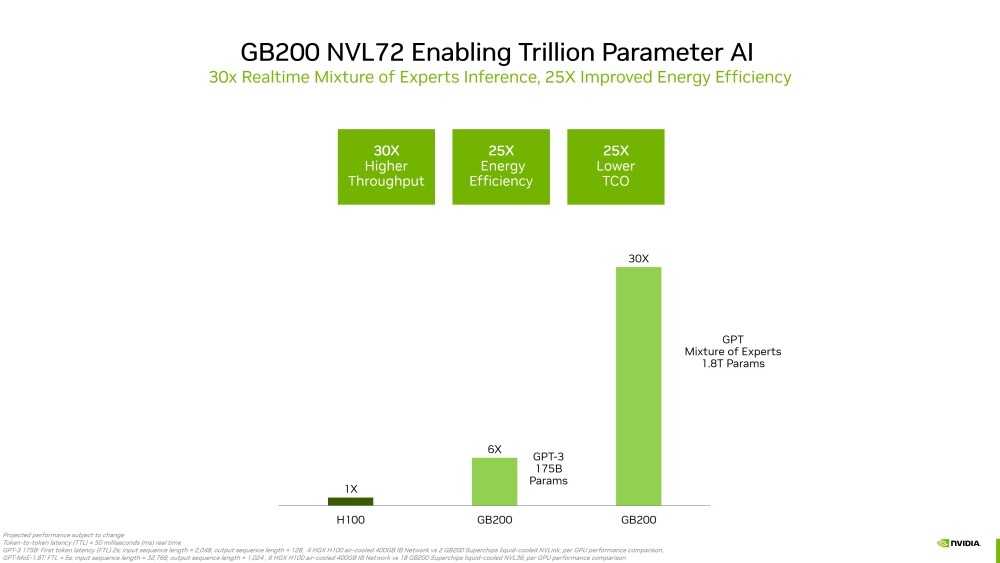
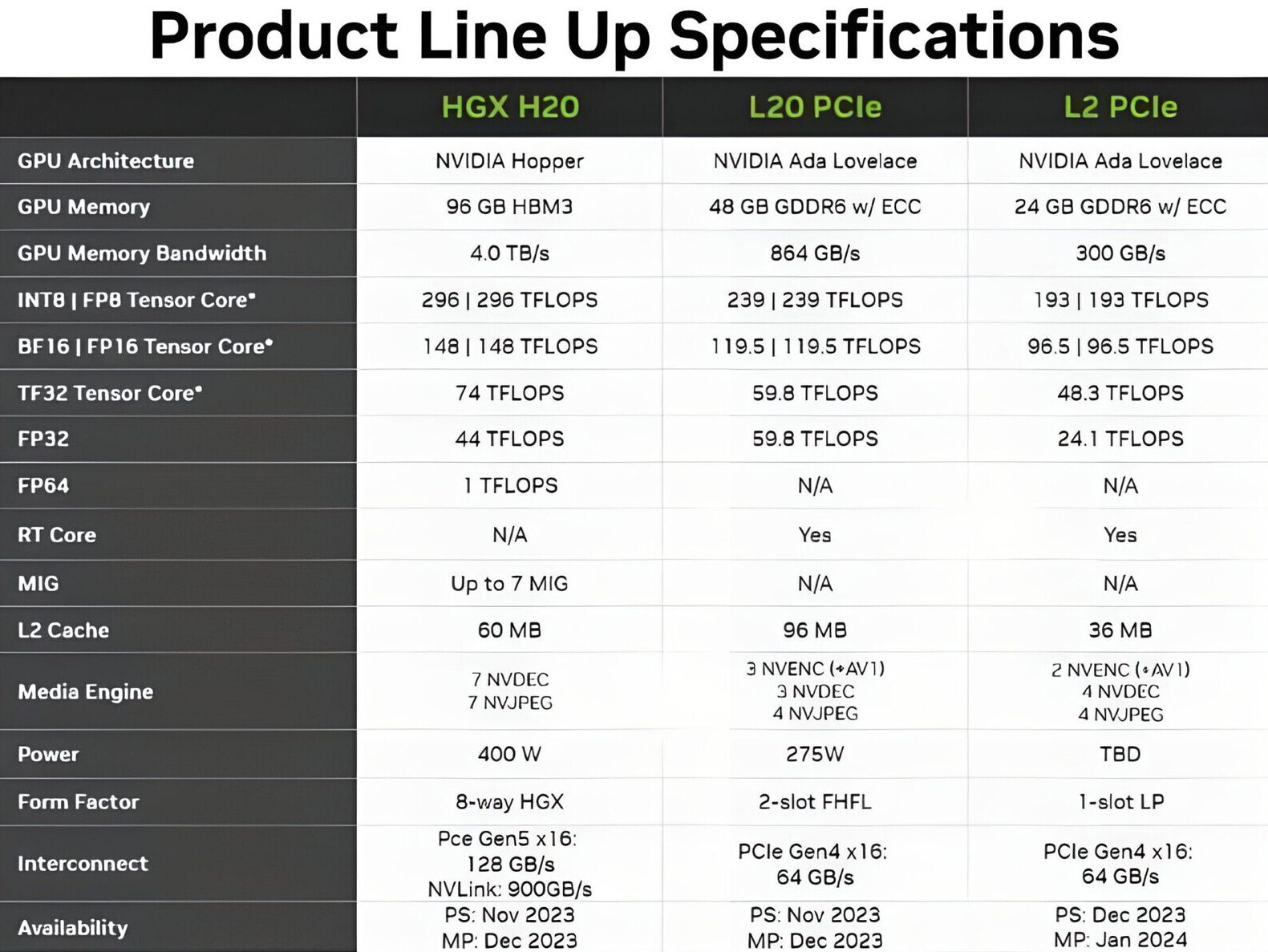
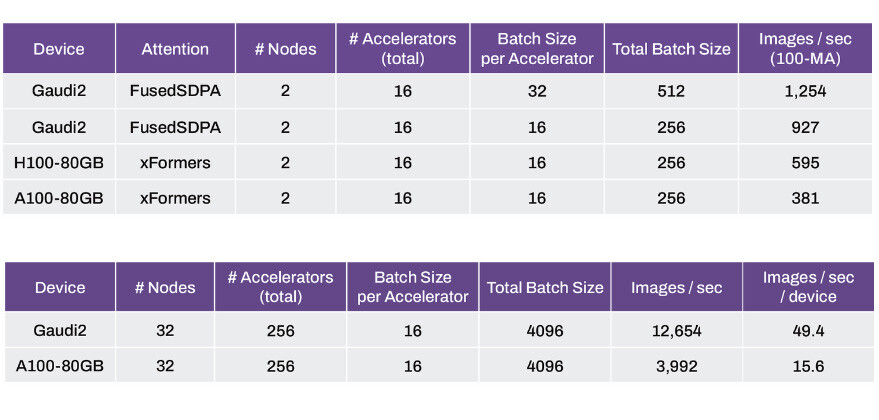
Computational lithography is also the most compute-intensive workload in the entire semiconductor design and manufacturing process. It consumes tens of billions of hours per year on CPUs in the leading-edge foundries. A typical mask set for a chip can take 30 million or more hours of CPU compute time, necessitating large data centers within semiconductor foundries. With accelerated computing, 350 NVIDIA H100 Tensor Core GPU-based systems can now replace 40,000 CPU systems, accelerating production time, while reducing costs, space and power.
Computational lithography is also the most compute-intensive workload in the entire semiconductor design and manufacturing process. It consumes tens of billions of hours per year on CPUs in the leading-edge foundries. A typical mask set for a chip can take 30 million or more hours of CPU compute time, necessitating large data centers within semiconductor foundries. With accelerated computing, 350 NVIDIA H100 Tensor Core GPU-based systems can now replace 40,000 CPU systems, accelerating production time, while reducing costs, space and power.