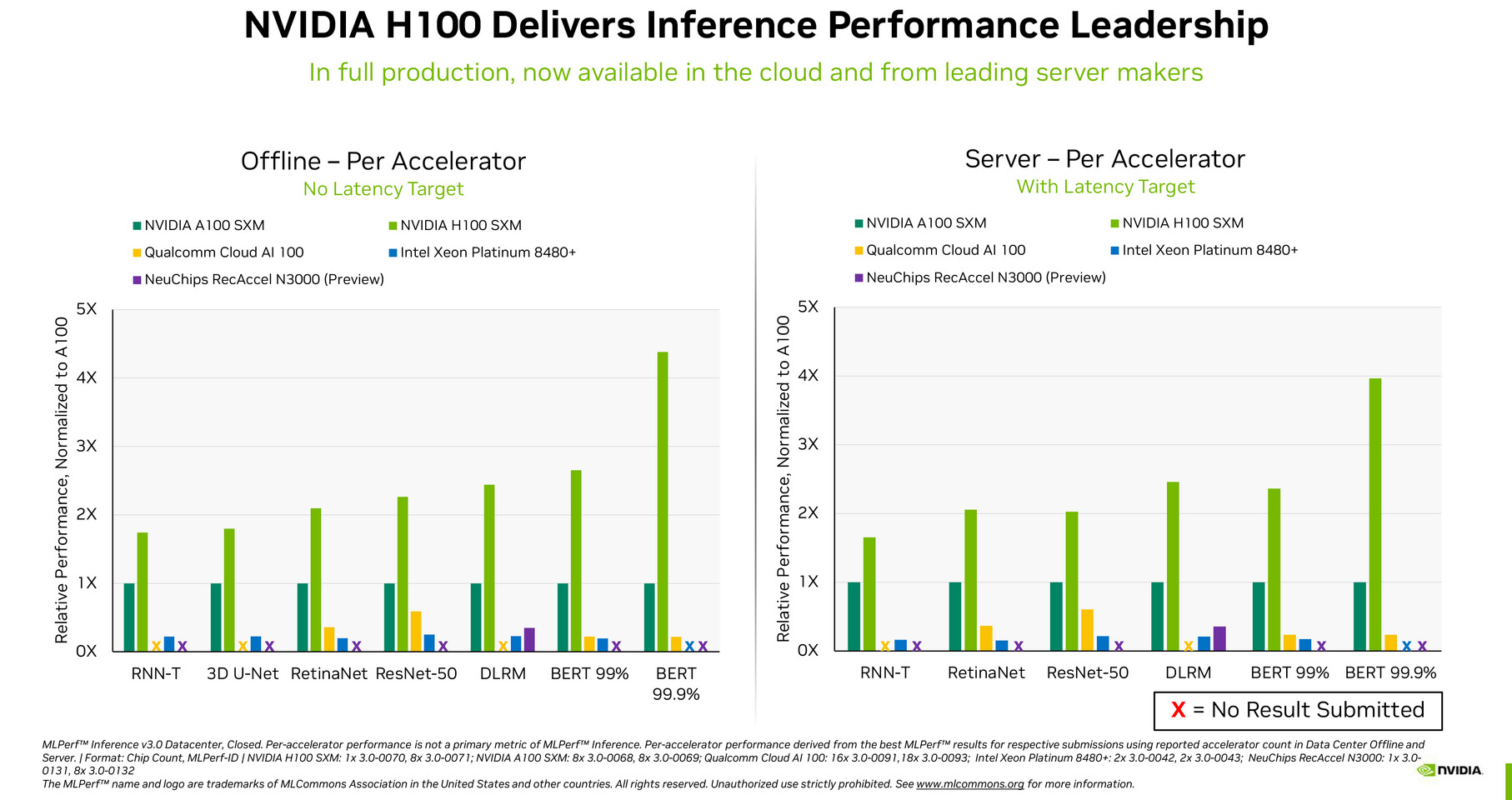
ASUS Unveils ESC N8-E11, an HGX H100 Eight-GPU Server
ASUS today announced ESC N8-E11, its most advanced HGX H100 eight-GPU AI server, along with a comprehensive PCI Express (PCIe) GPU server portfolio—the ESC8000 and ESC4000 series empowered by Intel and AMD platforms to support higher CPU and GPU TDPs to accelerate the development of AI and data science.
ASUS is one of the few HPC solution providers with its own all-dimensional resources that consist of the ASUS server business unit, Taiwan Web Service (TWS) and ASUS Cloud—all part of the ASUS group. This uniquely positions ASUS to deliver in-house AI server design, data-center infrastructure, and AI software-development capabilities, plus a diverse ecosystem of industrial hardware and software partners.


ASUS is one of the few HPC solution providers with its own all-dimensional resources that consist of the ASUS server business unit, Taiwan Web Service (TWS) and ASUS Cloud—all part of the ASUS group. This uniquely positions ASUS to deliver in-house AI server design, data-center infrastructure, and AI software-development capabilities, plus a diverse ecosystem of industrial hardware and software partners.