NVIDIA Unveils "Eos" to Public - a Top Ten Supercomputer
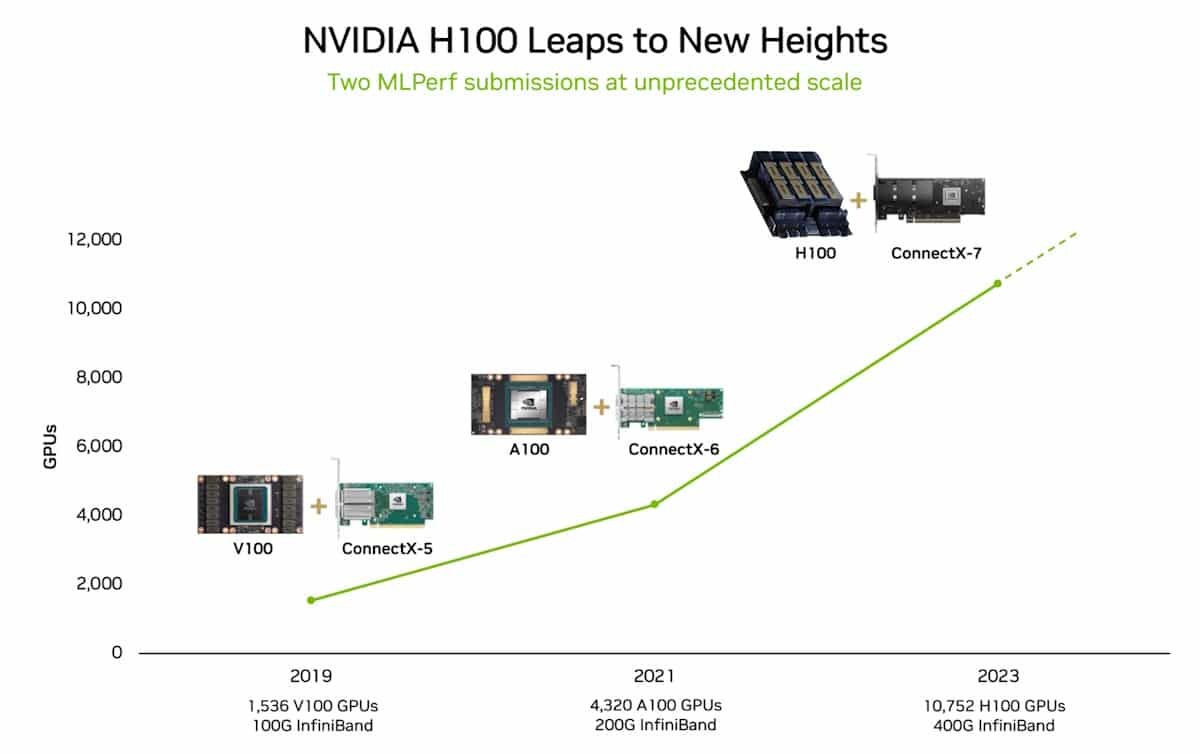
Providing a peek at the architecture powering advanced AI factories, NVIDIA released a video that offers the first public look at Eos, its latest data-center-scale supercomputer. An extremely large-scale NVIDIA DGX SuperPOD, Eos is where NVIDIA developers create their AI breakthroughs using accelerated computing infrastructure and fully optimized software. Eos is built with 576 NVIDIA DGX H100 systems, NVIDIA Quantum-2 InfiniBand networking and software, providing a total of 18.4 exaflops of FP8 AI performance. Revealed in November at the Supercomputing 2023 trade show, Eos—named for the Greek goddess said to open the gates of dawn each day—reflects NVIDIA's commitment to advancing AI technology.
Eos Supercomputer Fuels Innovation
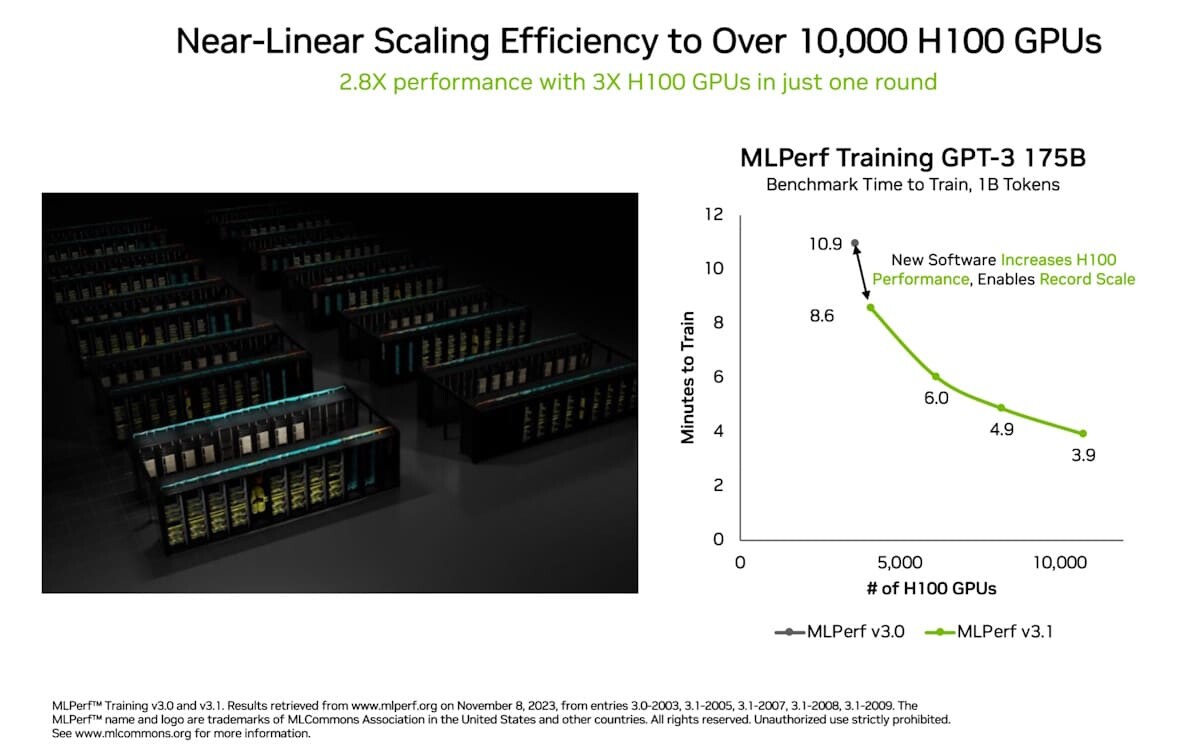
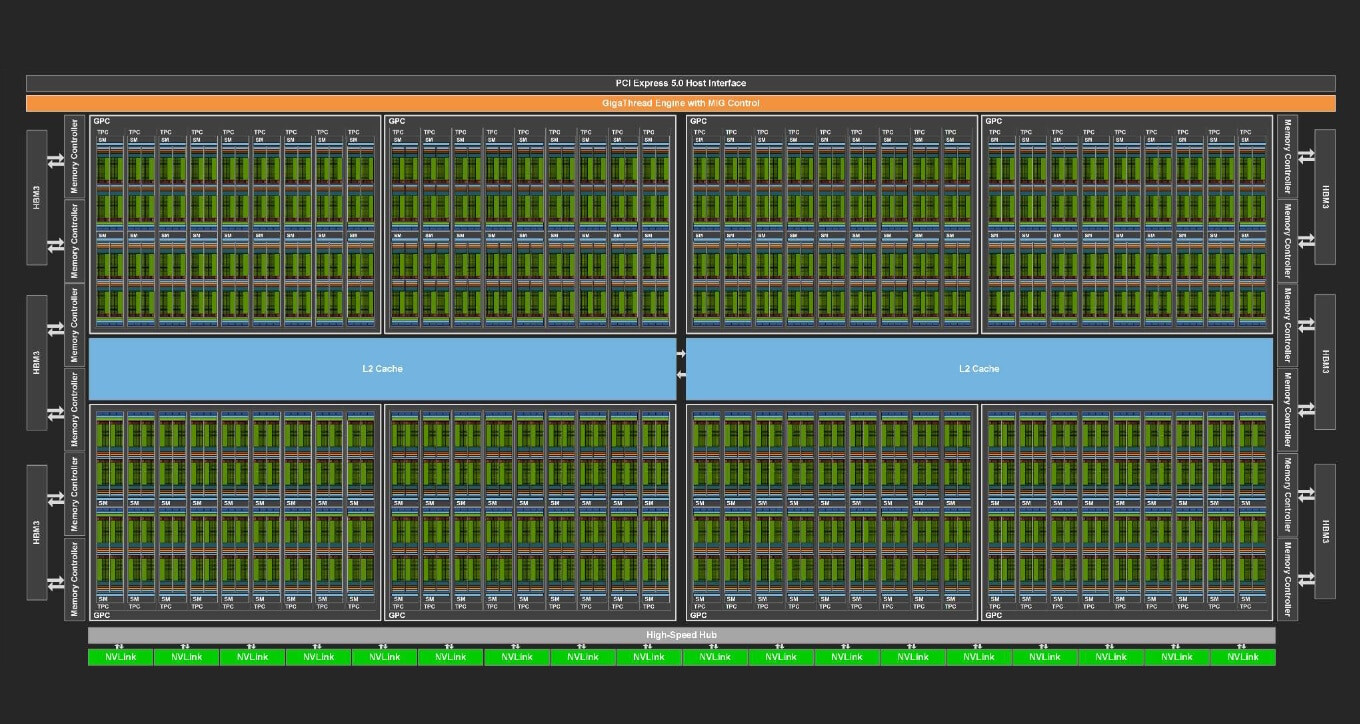
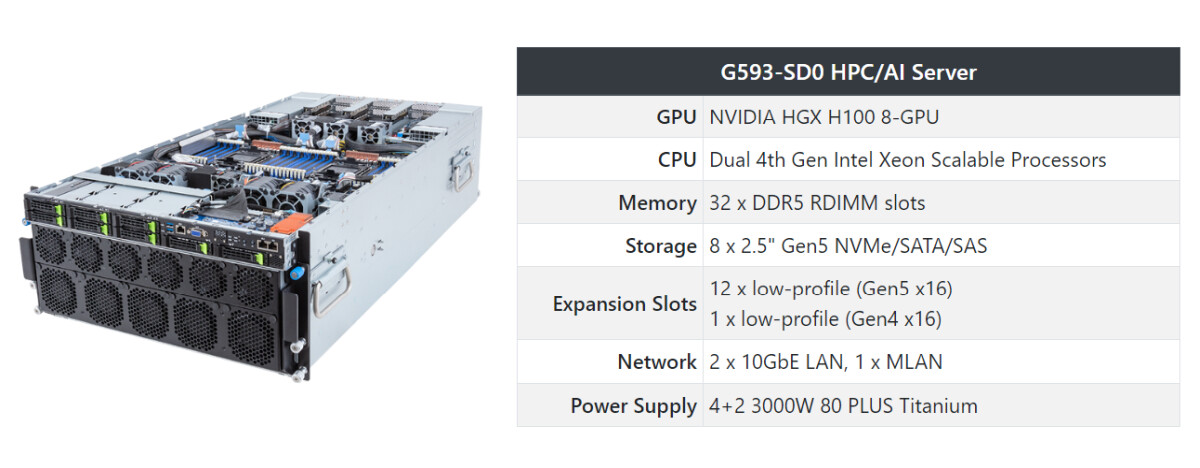
Each DGX H100 system is equipped with eight NVIDIA H100 Tensor Core GPUs. Eos features a total of 4,608 H100 GPUs. As a result, Eos can handle the largest AI workloads to train large language models, recommender systems, quantum simulations and more. It's a showcase of what NVIDIA's technologies can do, when working at scale. Eos is arriving at the perfect time. People are changing the world with generative AI, from drug discovery to chatbots to autonomous machines and beyond. To achieve these breakthroughs, they need more than AI expertise and development skills. They need an AI factory—a purpose-built AI engine that's always available and can help ramp their capacity to build AI models at scale Eos delivers. Ranked No. 9 in the TOP 500 list of the world's fastest supercomputers, Eos pushes the boundaries of AI technology and infrastructure.



Eos Supercomputer Fuels Innovation
Each DGX H100 system is equipped with eight NVIDIA H100 Tensor Core GPUs. Eos features a total of 4,608 H100 GPUs. As a result, Eos can handle the largest AI workloads to train large language models, recommender systems, quantum simulations and more. It's a showcase of what NVIDIA's technologies can do, when working at scale. Eos is arriving at the perfect time. People are changing the world with generative AI, from drug discovery to chatbots to autonomous machines and beyond. To achieve these breakthroughs, they need more than AI expertise and development skills. They need an AI factory—a purpose-built AI engine that's always available and can help ramp their capacity to build AI models at scale Eos delivers. Ranked No. 9 in the TOP 500 list of the world's fastest supercomputers, Eos pushes the boundaries of AI technology and infrastructure.