Apr 16th, 2025 09:47 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- The TPU UK Clubhouse (26116)
- Help me identify Chip of this DDR4 RAM (21)
- Last game you purchased? (772)
- 5070ti overclock...what are your settings? (5)
- Windows 11 fresh install to do list (23)
- How to relubricate a fan and/or service a troublesome/noisy fan. (229)
- GPU Memory Temprature is always high (16)
- Help For XFX RX 590 GME Chinese - Vbios (4)
- PCGH: "hidden site" to see total money spend on steam (3)
- Share your AIDA 64 cache and memory benchmark here (3053)
Popular Reviews
- G.SKILL Trident Z5 NEO RGB DDR5-6000 32 GB CL26 Review - AMD EXPO
- ASUS GeForce RTX 5080 TUF OC Review
- DAREU A950 Wing Review
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Thermaltake TR100 Review
- Zotac GeForce RTX 5070 Ti Amp Extreme Review
- TerraMaster F8 SSD Plus Review - Compact and quiet
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (124)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)
- NVIDIA Pushes GeForce RTX 5060 Ti Launch to Mid-April, RTX 5060 to May (77)
News Posts matching #OpenCL
Return to Keyword Browsing
NVIDIA GeForce RTX 50 Series Faces Compute Performance Issues Due to Dropped 32-bit Support
PassMark Software has identified the root cause behind unexpectedly low compute performance in NVIDIA's new GeForce RTX 5090, RTX 5080, and RTX 5070 Ti GPUs. The culprit: NVIDIA has silently discontinued support for 32-bit OpenCL and CUDA in its "Blackwell" architecture, causing compatibility issues with existing benchmarking tools and applications. The issue manifested when PassMark's DirectCompute benchmark returned the error code "CL_OUT_OF_RESOURCES (-5)" on RTX 5000 series cards. After investigation, developers confirmed that while the benchmark's primary application has been 64-bit for years, several compute sub-benchmarks still utilize 32-bit code that previously functioned correctly on RTX 4000 and earlier GPUs. This architectural change wasn't clearly documented by NVIDIA, whose developer website continues to display 32-bit code samples and documentation despite the removal of actual support.
The impact extends beyond benchmarking software. Applications built on legacy CUDA infrastructure, including technologies like PhysX, will experience significant performance degradation as computational tasks fall back to CPU processing rather than utilizing the GPU's parallel architecture. While this fallback mechanism allows older applications to run on the RTX 40 series and prior hardware, the RTX 5000 series handles these tasks exclusively through the CPU, resulting in substantially lower performance. PassMark is currently working to port the affected OpenCL code to 64-bit, allowing proper testing of the new GPUs' compute capabilities. However, they warn that many existing applications containing 32-bit OpenCL components may never function properly on RTX 5000 series cards without source code modifications. The benchmark developer also notes this change doesn't fully explain poor DirectX9 performance, suggesting additional architectural changes may affect legacy rendering pathways. PassMark updated its software today, but legacy benchmarks could still suffer. Below is an older benchmark run without the latest PassMark V11.1 build 1004 patches, showing just how much the newest generations suffers without a proper software support.

The impact extends beyond benchmarking software. Applications built on legacy CUDA infrastructure, including technologies like PhysX, will experience significant performance degradation as computational tasks fall back to CPU processing rather than utilizing the GPU's parallel architecture. While this fallback mechanism allows older applications to run on the RTX 40 series and prior hardware, the RTX 5000 series handles these tasks exclusively through the CPU, resulting in substantially lower performance. PassMark is currently working to port the affected OpenCL code to 64-bit, allowing proper testing of the new GPUs' compute capabilities. However, they warn that many existing applications containing 32-bit OpenCL components may never function properly on RTX 5000 series cards without source code modifications. The benchmark developer also notes this change doesn't fully explain poor DirectX9 performance, suggesting additional architectural changes may affect legacy rendering pathways. PassMark updated its software today, but legacy benchmarks could still suffer. Below is an older benchmark run without the latest PassMark V11.1 build 1004 patches, showing just how much the newest generations suffers without a proper software support.


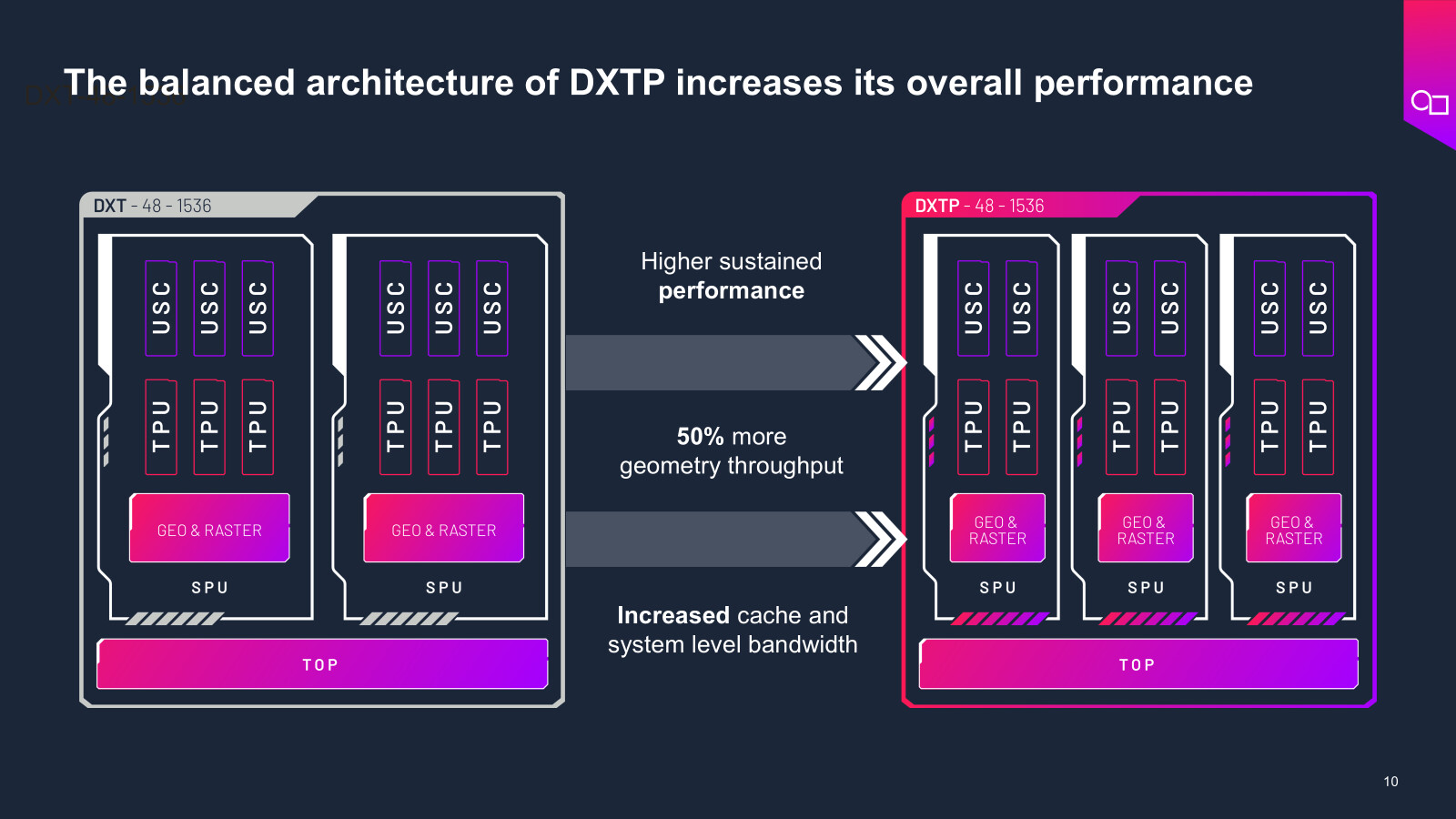
Imagination's New DXTP GPU for Mobile and Laptop: 20% More Power Efficient
Today Imagination Technologies announces its latest GPU IP, Imagination DXTP, which sets a new standard for the efficient acceleration of graphics and compute workloads on smartphones and other power-constrained devices. Thanks to an array of micro-architectural improvements, DXTP delivers up to 20% improved power efficiency (FPS/W) on popular graphics workloads when compared to its DXT equivalent.
"The global smartphone market is experiencing a resurgence, propelled by cutting-edge AI features such as personal agents and enhanced photography," says Peter Richardson, Partner & VP at Counterpoint Research. "However, the success of this AI-driven revolution hinges on maintaining the high standards users expect: smooth interfaces, sleek designs, and all-day battery life. As the market matures, consumers are gravitating towards premium devices that seamlessly integrate these advanced AI capabilities without compromising on essential smartphone qualities."


"The global smartphone market is experiencing a resurgence, propelled by cutting-edge AI features such as personal agents and enhanced photography," says Peter Richardson, Partner & VP at Counterpoint Research. "However, the success of this AI-driven revolution hinges on maintaining the high standards users expect: smooth interfaces, sleek designs, and all-day battery life. As the market matures, consumers are gravitating towards premium devices that seamlessly integrate these advanced AI capabilities without compromising on essential smartphone qualities."


NVIDIA GeForce RTX 5070 Ti Edges Out RTX 4080 in OpenCL Benchmark
A recently surfaced Geekbench OpenCL listing has revealed the performance improvements that the GeForce RTX 5070 Ti is likely to bring to the table, and the numbers sure look promising - that is, coming from the disappointment of the GeForce RTX 5080, which manages roughly 260,000 points in the benchmark, portraying a paltry 8% improvement over its predecessor. The GeForce RTX 5070 Ti, however, managed an impressive 248,000 points, putting it a substantial 20% ahead of the GeForce RTX 4070 Ti. Hilariously enough, the RTX 5080 is merely 4% ahead, making the situation even worse for the somewhat contentious GPU. NVIDIA has claimed similar performance improvements in its marketing material, which does seem quiet plausible.
Of course, an OpenCL benchmark is hardly representative of real-world gaming performance. That being said, there is no denying that raw benchmarks will certainly help buyers temper expectations and make decisions. Previous leaks and speculations have hinted at a roughly 10% improvement over its predecessor in raster performance and up to 15% improvements in ray tracing performance, although the OpenCL listing does indicate the RTX 5070 ti might be capable of a larger generational jump, neck-and-neck with NVIDIA's claims. For those in need of a refresher, the RTX 5070 Ti boasts 8960 CUDA cores paired with 16 GB of GDDR7 memory on a 256-bit bus. Like its siblings, the RTX 5070 is also rumored to face "extremely limited" supply at launch. With its official launch less than a week away, we won't have much waiting to do to find out for ourselves.


Of course, an OpenCL benchmark is hardly representative of real-world gaming performance. That being said, there is no denying that raw benchmarks will certainly help buyers temper expectations and make decisions. Previous leaks and speculations have hinted at a roughly 10% improvement over its predecessor in raster performance and up to 15% improvements in ray tracing performance, although the OpenCL listing does indicate the RTX 5070 ti might be capable of a larger generational jump, neck-and-neck with NVIDIA's claims. For those in need of a refresher, the RTX 5070 Ti boasts 8960 CUDA cores paired with 16 GB of GDDR7 memory on a 256-bit bus. Like its siblings, the RTX 5070 is also rumored to face "extremely limited" supply at launch. With its official launch less than a week away, we won't have much waiting to do to find out for ourselves.


New Leak Reveals NVIDIA RTX 5080 Is Slower Than RTX 4090
A set of newly leaked benchmarks has revealed the performance capabilities of NVIDIA's upcoming RTX 5080 GPU. Scheduled to launch alongside the RTX 5090 on January 30, the GPU was spotted on Geekbench under OpenCL and Vulkan benchmark tests—and based on the performance, it might not make it among the best graphics cards. The tested device was an MSI-branded RTX 5080 labeled as model MS-7E62. This setup had AMD's Ryzen 7 9800X3D processor, which many consider one of the best CPUs for gaming. It also included an MSI MPG 850 Edge TI Wi-Fi motherboard and 32 GB of DDR5-6000 memory.
The benchmark results show that the RTX 5080 scored 261,836 points in Vulkan and 256,138 points in OpenCL tests. Compared to the RTX 4080, its previous version, the RTX 5080 has a 22% boost in Vulkan performance and a small 6.7% gain in OpenCL. Reddit user TruthPhoenixV found that on the Blender Open Data platform, the GPU got a median score of 9,063.77. This score is 9.4% higher than the RTX 4080 and 8.2% better than the RTX 4080 Super. Even with these improvements, the RTX 5080 might not outperform the current-gen top-tier RTX 4090. In the past, NVIDIA's 80-class GPUs have beaten the 90-class GPUs from the previous generation, but these early numbers suggest this trend might not continue for the RTX 5080.



The benchmark results show that the RTX 5080 scored 261,836 points in Vulkan and 256,138 points in OpenCL tests. Compared to the RTX 4080, its previous version, the RTX 5080 has a 22% boost in Vulkan performance and a small 6.7% gain in OpenCL. Reddit user TruthPhoenixV found that on the Blender Open Data platform, the GPU got a median score of 9,063.77. This score is 9.4% higher than the RTX 4080 and 8.2% better than the RTX 4080 Super. Even with these improvements, the RTX 5080 might not outperform the current-gen top-tier RTX 4090. In the past, NVIDIA's 80-class GPUs have beaten the 90-class GPUs from the previous generation, but these early numbers suggest this trend might not continue for the RTX 5080.




Heavily Throttled NVIDIA RTX 5090 Laptop GPU Gets Benchmarked in Geekbench OpenCL
Another day, another Blackwell performance leak. As we inch closer to their official release, more and more benchmark results keep popping up on the internet. Now, a fresh Geekbench OpenCL listing seemingly sheds light on the performance brought to the table by the RTX 5090 Laptop GPU, housed in a Razer Blade 16 alongside a Strix Point APU. However, be warned - the following results depict the RTX 5090 laptop running at only 1515 MHz, which makes it significantly slower than what it is capable of when allowed to run at full tilt, likely to be somewhere around 2100 MHz.
As such, the RTX 5090 Laptop managed a score of only around 91,000 points - almost half that of its predecessor's typical score of 179,000 points according to Geekbench. This likely indicates that the laptop was running on battery power, which would make sense considering the abysmal result. At least, thanks to this listing, we do get to confirm the specifications of the RTX 5090 Laptop GPU - 82 SMs, which means a total of 10,496 CUDA cores, and 24 GB of GDDR7 VRAM. The RTX 4090 Laptop, on the other hand, packs 9728 CUDA cores, putting the RTX 5090 Laptop ahead by around 7.87%. The 150-watt RTX 5090 Laptop also clocks at 1455 MHz at an 80-watt TGP, and 2040 MHz at 150 watts. This does align with what we are witnessing from the aforementioned RTX 5090 Laptop listing, confirming that it is indeed in some kind of low-power mode.


As such, the RTX 5090 Laptop managed a score of only around 91,000 points - almost half that of its predecessor's typical score of 179,000 points according to Geekbench. This likely indicates that the laptop was running on battery power, which would make sense considering the abysmal result. At least, thanks to this listing, we do get to confirm the specifications of the RTX 5090 Laptop GPU - 82 SMs, which means a total of 10,496 CUDA cores, and 24 GB of GDDR7 VRAM. The RTX 4090 Laptop, on the other hand, packs 9728 CUDA cores, putting the RTX 5090 Laptop ahead by around 7.87%. The 150-watt RTX 5090 Laptop also clocks at 1455 MHz at an 80-watt TGP, and 2040 MHz at 150 watts. This does align with what we are witnessing from the aforementioned RTX 5090 Laptop listing, confirming that it is indeed in some kind of low-power mode.




First Taste of Intel Arc B570: OpenCL Benchmark Reports Good Price-to-Performance
In the past few weeks, all eyes have on NVIDIA's and AMD's next-gen GPU offerings, and rightly so. Now, it's about time to turn our attention to what appears to be the third major player in the GPU industry - Intel. This is, of course, all thanks to the Blue Camp's wildly successful Arc B580 launch, which propelled the beleaguered chip giant to the favorable side of the GPU price-to-performance line.
Now, it appears that a fresh leak has revealed how its soon-to-be sibling, the Arc B570, is about to perform. The leaked performance data, courtesy of Geekbench OpenCL, reveals that the Arc B570 is right around 11% slower than the Arc B580 in the synthetic OpenCL benchmark, which makes complete sense, because the card is also expected to be around 12% cheaper than its more powerful sibling, as noted by Wccftech. With a score of 86,716, the Arc B570 is well ahead of the RX 7600 XT, which manages around 84000 points, and well behind the RTX 4060, which rakes in just above 100000.


Now, it appears that a fresh leak has revealed how its soon-to-be sibling, the Arc B570, is about to perform. The leaked performance data, courtesy of Geekbench OpenCL, reveals that the Arc B570 is right around 11% slower than the Arc B580 in the synthetic OpenCL benchmark, which makes complete sense, because the card is also expected to be around 12% cheaper than its more powerful sibling, as noted by Wccftech. With a score of 86,716, the Arc B570 is well ahead of the RX 7600 XT, which manages around 84000 points, and well behind the RTX 4060, which rakes in just above 100000.




Latest Asahi Linux Brings AAA Windows Games to Apple M1 MacBooks With Intricate Graphics Driver and Translation Stack
While Apple laptops have never really been the first stop for PC gaming, Linux is slowly shaping up to be an excellent gaming platform, largely thanks to open-source development efforts as well as work from the likes of AMD and NVIDIA, who have both put significant work into their respective Linux drivers in recent years. This makes efforts like the Asahi Linux Project all the more intriguing. Asahi Linux is a project that aims to bring Linux to Apple Silicon Macs—a task that has proven rather difficult, thanks to the intricacies of developing a bespoke GPU driver for Apple's custom ARM GPUs. In a recent blog post, the graphics developer behind the Asahi Linux Project showed off a number of AAA games, albeit older titles, running on an Apple M1 processor on the latest Asahi Linux build.
To run the games on Apple Silicon, Asahi Linux uses a "game playing toolkit," which relies on a number of custom graphics drivers and emulators, including tools from Valve's Proton translation layer, which ironically was also the foundation for Apple's Game Porting Toolkit. Asahi uses FEX to emulate x86 on ARM, Wine as a translation layer for Windows apps, and DXVK and vkd3d-proton for DirectX-Vulkan translation. In the blog post, the Asahi developer claims that the alpha is capable of running games like Control, The Witcher 3, and Cyberpunk 2077 at playable frame rates. Unfortunately, 60 FPS is not yet attainable in the majority of new high-fidelity games, there are a number of indie titles that run quite well on Asahi Linux, including Hollow Knight, Ghostrunner, and Portal 2.




To run the games on Apple Silicon, Asahi Linux uses a "game playing toolkit," which relies on a number of custom graphics drivers and emulators, including tools from Valve's Proton translation layer, which ironically was also the foundation for Apple's Game Porting Toolkit. Asahi uses FEX to emulate x86 on ARM, Wine as a translation layer for Windows apps, and DXVK and vkd3d-proton for DirectX-Vulkan translation. In the blog post, the Asahi developer claims that the alpha is capable of running games like Control, The Witcher 3, and Cyberpunk 2077 at playable frame rates. Unfortunately, 60 FPS is not yet attainable in the majority of new high-fidelity games, there are a number of indie titles that run quite well on Asahi Linux, including Hollow Knight, Ghostrunner, and Portal 2.





Intel Arc "Battlemage" GPU Surfaces with 20 Xe2 Cores, 2.85 GHz Clock Speed, and 12 GB VRAM
Intel's upcoming Arc "Battlemage" G21 GPU has made an appearance in Geekbench benchmarks, offering a glimpse into the future of the company's discrete graphics offerings. This next-generation GPU, part of Intel's Xe2 graphics architecture, shows promising performance that puts it almost on par with the current Arc A770 in initial tests. The benchmark results reveal a GPU with 20 Xe2 cores, translating to 160 CUs. Notably, the chip boasts a clock speed of 2,850 MHz. Equipped with 12 GB of memory, this particular model appears to be targeting the mid-range segment of the market.
Identified by the PCI ID "8086:E20B" and listed as "Intel Xe Graphics RI," the GPU scored 97,943 points in Geekbench 6's OpenCL test. This score places it near the Arc A770 and NVIDIA's GeForce RTX 4060, suggesting competitive performance in its class. The test system paired the Battlemage GPU with an Intel Core i5-13600K CPU and 32 GB of DDR5-4800 memory, providing a solid platform for evaluation. One interesting thing to note is that, while these early benchmarks show weak OpenCL performance, Intel didn't historically target this particular API, and the final performance will be higher in actual games that use DirectX 12 or Vulkan APIs, possibly worthy of competing with NVIDIA and AMD solutions.
Identified by the PCI ID "8086:E20B" and listed as "Intel Xe Graphics RI," the GPU scored 97,943 points in Geekbench 6's OpenCL test. This score places it near the Arc A770 and NVIDIA's GeForce RTX 4060, suggesting competitive performance in its class. The test system paired the Battlemage GPU with an Intel Core i5-13600K CPU and 32 GB of DDR5-4800 memory, providing a solid platform for evaluation. One interesting thing to note is that, while these early benchmarks show weak OpenCL performance, Intel didn't historically target this particular API, and the final performance will be higher in actual games that use DirectX 12 or Vulkan APIs, possibly worthy of competing with NVIDIA and AMD solutions.


Microsoft DirectX 12 Shifts to SPIR-V as Default Interchange Format
Microsoft's Direct3D and HLSL teams have unveiled plans to integrate SPIR-V support into DirectX 12 with the upcoming release of Shader Model 7. This significant transition marks a new era in GPU programmability, as it aims to unify the intermediate representation for graphical-shader stages and compute kernels. SPIR-V, an open standard intermediate representation for graphics and compute shaders, will replace the proprietary DirectX Intermediate Language (DXIL) as the shader interchange format for DirectX 12. The adoption of SPIR-V is expected to ease development processes across multiple GPU runtime environments. By embracing this open standard, Microsoft aims to enhance HLSL's position as the premier language for compiling graphics and compute shaders across various devices and APIs. This transition is part of a multi-year development process, during which Microsoft will work closely with The Khronos Group and the LLVM Project. The company has joined Khronos' SPIR and Vulkan working groups to ensure smooth collaboration and rapid feature adoption.
While the transition will take several years, Microsoft is providing early notice to allow developers and partners to plan accordingly. The company will offer translation tools between SPIR-V and DXIL to facilitate a gradual transition for both application and driver developers. For those not familiar with graphics development, graphics APIs ship with virtual instruction set architectures (ISA) that abstracts standard hardware features at a higher level. As GPUs don't follow the same ISA as CPUs (x86, Arm, RISC-V), this virtual ISA is needed to define some generics in the GPU architecture and allow various APIs like DirectX and Vulkan to run. Instead of focusing support on several formats like DXIL, Microsoft is embracing the open SPIR-V standard, which will become de facto for API developers in the future, allowing focus on more features instead of constantly replicating each other's functions. While DXIL is used mainly for gaming environments, SPIR-V has adoption in high-performance computing as well, with OpenCL and SYCL. Gaming presence is also there with Vulkan API, and we expect to see SPIR-V join DirectX 12 games.
While the transition will take several years, Microsoft is providing early notice to allow developers and partners to plan accordingly. The company will offer translation tools between SPIR-V and DXIL to facilitate a gradual transition for both application and driver developers. For those not familiar with graphics development, graphics APIs ship with virtual instruction set architectures (ISA) that abstracts standard hardware features at a higher level. As GPUs don't follow the same ISA as CPUs (x86, Arm, RISC-V), this virtual ISA is needed to define some generics in the GPU architecture and allow various APIs like DirectX and Vulkan to run. Instead of focusing support on several formats like DXIL, Microsoft is embracing the open SPIR-V standard, which will become de facto for API developers in the future, allowing focus on more features instead of constantly replicating each other's functions. While DXIL is used mainly for gaming environments, SPIR-V has adoption in high-performance computing as well, with OpenCL and SYCL. Gaming presence is also there with Vulkan API, and we expect to see SPIR-V join DirectX 12 games.


AAEON Unveils RICO-MX8P pITX Motherboard for Kiosks
Award-winning embedded solutions provider AAEON (stock code: 6579) has announced the launch of the RICO-MX8P, an NXP i.MX 8M Plus-powered fanless single-board built on the Pico-ITX Plus form factor. Utilizing the i.MX 8M Plus, the RICO-MX8P leverages a platform comprised of a quad-core Arm Cortex -A53 processor, a secondary core Arm Cortex M7, and an optional Neural Processing Unit (NPU) offering up to 2.3 TOPS of inference performance.
Equipped with an integrated Vivante GC7000 UltraLite 3D GPU, a dedicated VPU, MIPI DSI interface, and an HDMI 2.0 port, it is clear AAEON is positioning the RICO-MX8P as a candidate for multimedia applications, with digital signage, smart kiosk, and interactive Digital Out-of-Home (DOOH) advertising earmarked as potential uses. Further benefits to such use are evident from the board's support for APIs like OpenGL ES 3.1, Vulkan, and OpenCL 1.2, alongside its multiformat encoding and decoding capabilities.


Equipped with an integrated Vivante GC7000 UltraLite 3D GPU, a dedicated VPU, MIPI DSI interface, and an HDMI 2.0 port, it is clear AAEON is positioning the RICO-MX8P as a candidate for multimedia applications, with digital signage, smart kiosk, and interactive Digital Out-of-Home (DOOH) advertising earmarked as potential uses. Further benefits to such use are evident from the board's support for APIs like OpenGL ES 3.1, Vulkan, and OpenCL 1.2, alongside its multiformat encoding and decoding capabilities.



X-Silicon Startup Wants to Combine RISC-V CPU, GPU, and NPU in a Single Processor
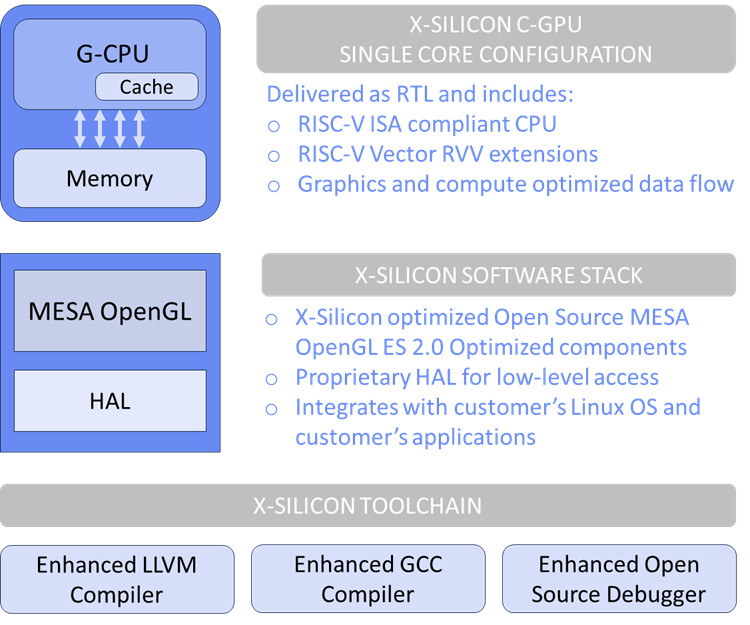
While we are all used to having a system with a CPU, GPU, and, recently, NPU—X-Silicon Inc. (XSi), a startup founded by former Silicon Valley veterans—has unveiled an interesting RISC-V processor that can simultaneously handle CPU, GPU, and NPU workloads in a chip. This innovative chip architecture, which will be open-source, aims to provide a flexible and efficient solution for a wide range of applications, including artificial intelligence, virtual reality, automotive systems, and IoT devices. The new microprocessor combines a RISC-V CPU core with vector capabilities and GPU acceleration into a single chip, creating a versatile all-in-one processor. By integrating the functionality of a CPU and GPU into a single core, X-Silicon's design offers several advantages over traditional architectures. The chip utilizes the open-source RISC-V instruction set architecture (ISA) for both CPU and GPU operations, running a single instruction stream. This approach promises lower memory footprint execution and improved efficiency, as there is no need to copy data between separate CPU and GPU memory spaces.
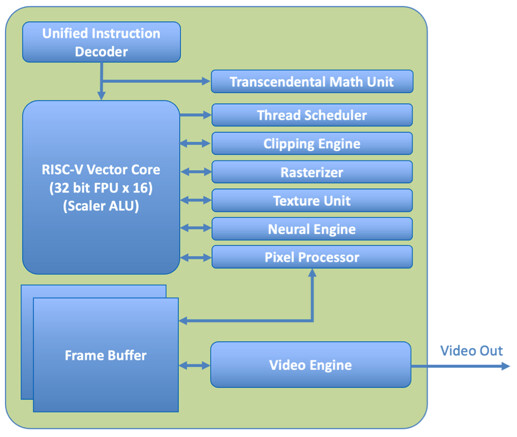
Called the C-GPU architecture, X-Silicon uses RISC-V Vector Core, which has 16 32-bit FPUs and a Scaler ALU for processing regular integers as well as floating point instructions. A unified instruction decoder feeds the cores, which are connected to a thread scheduler, texture unit, rasterizer, clipping engine, neural engine, and pixel processors. All is fed into a frame buffer, which feeds the video engine for video output. The setup of the cores allows the users to program each core individually for HPC, AI, video, or graphics workloads. Without software, there is no usable chip, which prompts X-Silicon to work on OpenGL ES, Vulkan, Mesa, and OpenCL APIs. Additionally, the company plans to release a hardware abstraction layer (HAL) for direct chip programming. According to Jon Peddie Research (JPR), the industry has been seeking an open-standard GPU that is flexible and scalable enough to support various markets. X-Silicon's CPU/GPU hybrid chip aims to address this need by providing manufacturers with a single, open-chip design that can handle any desired workload. The XSi gave no timeline, but it has plans to distribute the IP to OEMs and hyperscalers, so the first silicon is still away.


Called the C-GPU architecture, X-Silicon uses RISC-V Vector Core, which has 16 32-bit FPUs and a Scaler ALU for processing regular integers as well as floating point instructions. A unified instruction decoder feeds the cores, which are connected to a thread scheduler, texture unit, rasterizer, clipping engine, neural engine, and pixel processors. All is fed into a frame buffer, which feeds the video engine for video output. The setup of the cores allows the users to program each core individually for HPC, AI, video, or graphics workloads. Without software, there is no usable chip, which prompts X-Silicon to work on OpenGL ES, Vulkan, Mesa, and OpenCL APIs. Additionally, the company plans to release a hardware abstraction layer (HAL) for direct chip programming. According to Jon Peddie Research (JPR), the industry has been seeking an open-standard GPU that is flexible and scalable enough to support various markets. X-Silicon's CPU/GPU hybrid chip aims to address this need by providing manufacturers with a single, open-chip design that can handle any desired workload. The XSi gave no timeline, but it has plans to distribute the IP to OEMs and hyperscalers, so the first silicon is still away.
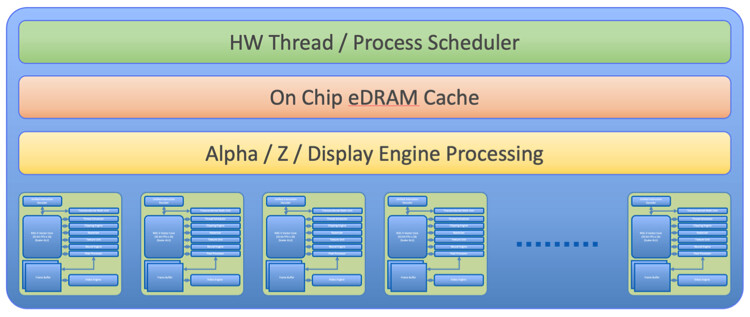

AMD Develops ROCm-based Solution to Run Unmodified NVIDIA's CUDA Binaries on AMD Graphics
AMD has quietly funded an effort over the past two years to enable binary compatibility for NVIDIA CUDA applications on their ROCm stack. This allows CUDA software to run on AMD Radeon GPUs without adapting the source code. The project responsible is ZLUDA, which was initially developed to provide CUDA support on Intel graphics. The developer behind ZLUDA, Andrzej Janik, was contracted by AMD in 2022 to adapt his project for use on Radeon GPUs with HIP/ROCm. He spent two years bringing functional CUDA support to AMD's platform, allowing many real-world CUDA workloads to run without modification. AMD decided not to productize this effort for unknown reasons but did open-source it once funding ended per their agreement. Over at Phoronix, there were several benchmarks testing AMD's ZLUDA implementation over a wide variety of benchmarks.
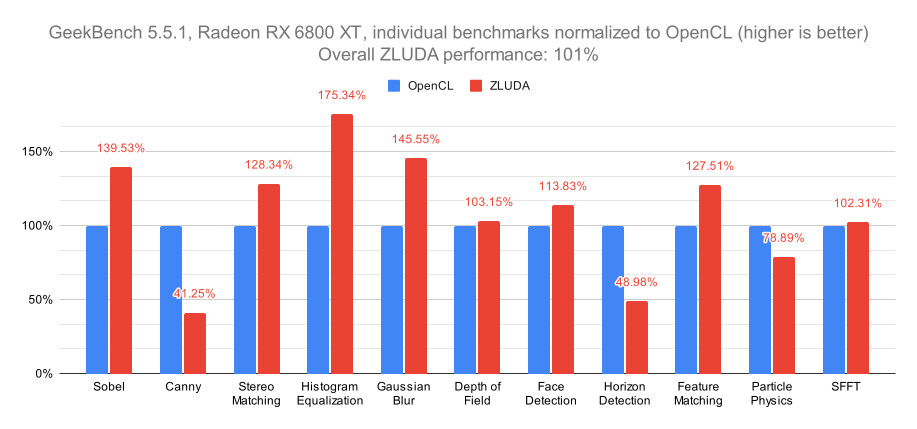
Benchmarks found that proprietary CUDA renderers and software worked on Radeon GPUs out-of-the-box with the drop-in ZLUDA library replacements. CUDA-optimized Blender 4.0 rendering now runs faster on AMD Radeon GPUs than the native ROCm/HIP port, reducing render times by around 10-20%, depending on the scene. The implementation is surprisingly robust, considering it was a single-developer project. However, there are some limitations—OptiX and PTX assembly codes still need to be fully supported. Overall, though, testing showed very promising results. Over the generic OpenCL runtimes in Geekbench, CUDA-optimized binaries produce up to 75% better results. With the ZLUDA libraries handling API translation, unmodified CUDA binaries can now run directly on top of ROCm and Radeon GPUs. Strangely, the ZLUDA port targets AMD ROCm 5.7, not the newest 6.x versions. Only time will tell if AMD continues investing in this approach to simplify porting of CUDA software. However, the open-sourced project now enables anyone to contribute and help improve compatibility. For a complete review, check out Phoronix tests.

Benchmarks found that proprietary CUDA renderers and software worked on Radeon GPUs out-of-the-box with the drop-in ZLUDA library replacements. CUDA-optimized Blender 4.0 rendering now runs faster on AMD Radeon GPUs than the native ROCm/HIP port, reducing render times by around 10-20%, depending on the scene. The implementation is surprisingly robust, considering it was a single-developer project. However, there are some limitations—OptiX and PTX assembly codes still need to be fully supported. Overall, though, testing showed very promising results. Over the generic OpenCL runtimes in Geekbench, CUDA-optimized binaries produce up to 75% better results. With the ZLUDA libraries handling API translation, unmodified CUDA binaries can now run directly on top of ROCm and Radeon GPUs. Strangely, the ZLUDA port targets AMD ROCm 5.7, not the newest 6.x versions. Only time will tell if AMD continues investing in this approach to simplify porting of CUDA software. However, the open-sourced project now enables anyone to contribute and help improve compatibility. For a complete review, check out Phoronix tests.

Khronos Publishes Vulkan Roadmap 2024, Highlights Expanded 3D Features
Today, The Khronos Group, an open consortium of industry-leading companies creating advanced interoperability standards, announced the latest roadmap milestone for Vulkan, the cross-platform 3D graphics and compute API. The Vulkan roadmap targets the "immersive graphics" market, made up of mid- to high-end smartphones, tablets, laptops, consoles, and desktop devices. The Vulkan Roadmap 2024 milestone captures a set of capabilities that are expected to be supported in new products for that market, beginning in 2024. The roadmap specification provides a significant increase in functionality for the targeted devices and sets the evolutionary direction of the API, including both new hardware capabilities and improvements to the programming model for Vulkan developers.
Vulkan Roadmap 2024 is the second milestone release on the Vulkan Roadmap. Products that support it must be Vulkan 1.3 conformant and support the extensions and capabilities defined in both the 2022 and 2024 Roadmap specifications. Vulkan roadmap specifications use the Vulkan Profile mechanism to help developers build portable Vulkan applications; roadmap requirements are expressed in machine-readable JSON files, and tooling in the Vulkan SDK auto-generates code that makes it easy for developers to query for and enable profile support in their applications.



Vulkan Roadmap 2024 is the second milestone release on the Vulkan Roadmap. Products that support it must be Vulkan 1.3 conformant and support the extensions and capabilities defined in both the 2022 and 2024 Roadmap specifications. Vulkan roadmap specifications use the Vulkan Profile mechanism to help developers build portable Vulkan applications; roadmap requirements are expressed in machine-readable JSON files, and tooling in the Vulkan SDK auto-generates code that makes it easy for developers to query for and enable profile support in their applications.



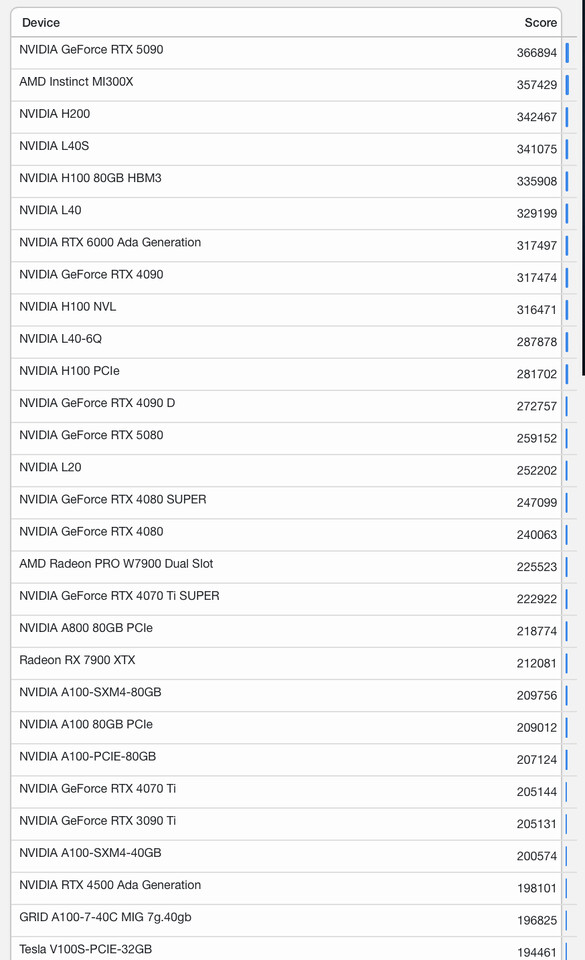
NVIDIA GeForce RTX 4080 SUPER GPUs Pop Up in Geekbench Browser
We are well aware that NVIDIA GeForce RTX 4080 SUPER graphics cards are next up on the review table (January 31)—TPU's W1zzard has so far toiled away on getting his evaluations published on time for options further down the Ada Lovelace SUPER food chain. This process was interrupted briefly by the appearance of custom Radeon RX 7600 XT models, but today's attention soon returned to another batch of GeForce RTX 4070 Ti SUPER cards. Reviewers are already toying around with driver-enabled GeForce RTX 4080 SUPER sample units—under strict confidentiality conditions—but the occasional leak is expected to happen. The appropriately named Benchleaks social media account has kept track of emerging test results.
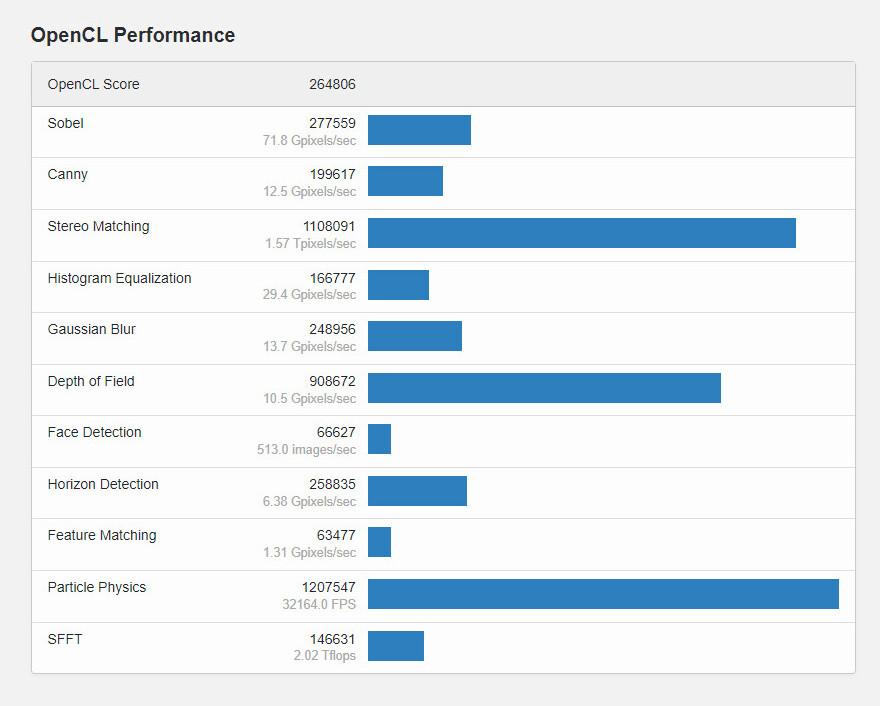
The Geekbench Browser database was updated earlier today with premature GeForce RTX 4080 SUPER GPU test results—one entry highlighted by Benchleaks provides a quick look at the card's prowess in three of Geekbench 5.1's graphics API trials: Vulkan, CUDA and OpenCL. VideoCardz points out that all of the scores could be fundamentally flawed; in particular the Vulkan result of 100378 points—the regular (non-SUPER) GeForce RTX 4080 GPU can achieve almost double that figure in Geekbench 6. The SUPER's other results included a Geekbench 5 CUDA score of 309554, and an achievement of 264806 points in OpenCL. A late morning entrant looks to be hitting the right mark—an ASUS testbed (PRIME Z790-A WIFI + Intel Core i9-13900KF) managed to score 210551 points in Geekbench 6.2.2 Vulkan.



The Geekbench Browser database was updated earlier today with premature GeForce RTX 4080 SUPER GPU test results—one entry highlighted by Benchleaks provides a quick look at the card's prowess in three of Geekbench 5.1's graphics API trials: Vulkan, CUDA and OpenCL. VideoCardz points out that all of the scores could be fundamentally flawed; in particular the Vulkan result of 100378 points—the regular (non-SUPER) GeForce RTX 4080 GPU can achieve almost double that figure in Geekbench 6. The SUPER's other results included a Geekbench 5 CUDA score of 309554, and an achievement of 264806 points in OpenCL. A late morning entrant looks to be hitting the right mark—an ASUS testbed (PRIME Z790-A WIFI + Intel Core i9-13900KF) managed to score 210551 points in Geekbench 6.2.2 Vulkan.



Intel Core Ultra 7 155H iGPU Outperforms AMD Radeon 780M, Comes Close to Desktop Intel Arc A380
Intel is slowly preparing to launch its next-generation Meteor Lake mobile processor family, dropping the Core i brand name in favor of Core Ultra. Today, we are witnessing some early Geekbench v6 benchmarks with the latest leak of the Core Ultra 7 155H processor, boasting an integrated Arc GPU featuring 8 Xe-Cores—the complete configuration expected in the GPU tile. This tile is also projected to be a part of the more potent Core 9 Ultra 185H CPU. The Intel Core Ultra 7 155H processor has been benchmarked in the new ASUS Zenbook 14, which houses a 16-core and 22-thread hybrid CPU configuration capable of boosting up to 4.8 GHz. Paired with 32 GB of memory, the configuration was well equipped to supply CPU and GPU with sufficient memory space.
Perhaps the most interesting information from the submission was the OpenCL score of the GPU. Clocking in at 33948 points in Geekbench v6, the GPU is running over AMD's Radeon 780M GPU found in APU solutions like AMD Ryzen 9 7940HS and Ryzen 9 7940U, which scored 30585 and 27345 points in the same benchmark, respectively. The GPU tile is millimeters away from closing the gap between itself and the desktop Intel Arc A380 discrete GPU, which scored 37105 points for less than a 10% difference. The Xe-LPG GPU version is bringing some interesting performance points for the integrated GPU platform, which means that Intel's Meteor Lake SKUs will bring more performance/watt than ever.
Perhaps the most interesting information from the submission was the OpenCL score of the GPU. Clocking in at 33948 points in Geekbench v6, the GPU is running over AMD's Radeon 780M GPU found in APU solutions like AMD Ryzen 9 7940HS and Ryzen 9 7940U, which scored 30585 and 27345 points in the same benchmark, respectively. The GPU tile is millimeters away from closing the gap between itself and the desktop Intel Arc A380 discrete GPU, which scored 37105 points for less than a 10% difference. The Xe-LPG GPU version is bringing some interesting performance points for the integrated GPU platform, which means that Intel's Meteor Lake SKUs will bring more performance/watt than ever.


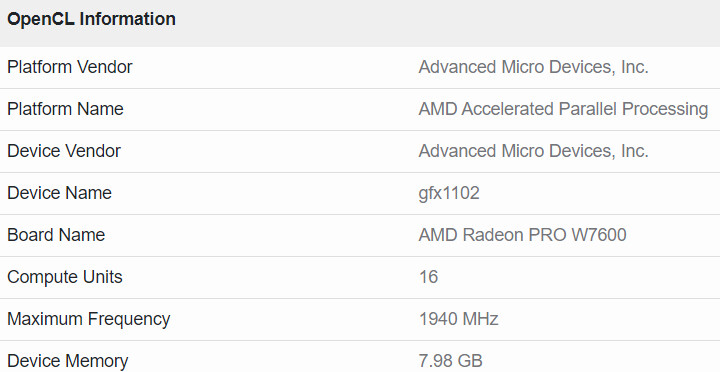
AMD Radeon PRO W7600 GPU Spotted in Geekbench Database
An interesting system popped up on Geekbench Browser early this morning—on initial inspection the evaluated high-end PC was sporting hardware of 2021-vintage, but its graphics card was observed as an outlier. The Intel Core i9-12900K (Alder Lake-S) CPU was sitting on an MSI MPG Z690 Carbon WiFi mainboard, with 64 GB of DDR5 SDRAM (3990 MT/s). The benchmarked computer was running Microsoft Windows 11 Pro (64-bit) on a power saver (economizador) plan. According to the entry's OpenCL information section we are looking at an attached GPU device called "GFX1102 ID," the board name is revealed to be "AMD Radeon PRO W7600" with 8 GB of VRAM. This lower-end alternative to existing (RDNA 3) Radeon Pro models—W7900 (48 GB) and W7800 (32 GB)—could be nearing a public launch.
This information aligns the workstation-oriented card with AMD's Navi 33 GPU—the same GFX1102 designation appears within TPU's database entry (look at the Shader ISA (GFX11.0) graphics feature). VideoCardz reckons that the leaked Radeon PRO W7600 is closely related to AMD's mobile Radeon RX 7700/7600 series—based on Navi 33, due to their matching IDs. Their report proposed: "Based on this data, the GPU is expected to have a clock speed of 1940 MHz. Comparatively, this is 310 MHz lower than the Radeon RX 7600 gaming model, which refers to its Game Clock of 2250 MHz. The Compute Unit field refers to "Workgroup Processor/WGP" cluster, so the card features 32 Compute Units or 2048 Stream Processors, the same configuration as the RX 7600. The card is listed with 8 GB of memory, but it remains uncertain whether this model will support ECC (error correction), a feature found in the W7900/W7800 models. It's important to note that the W6600 did not utilize this type of memory."


This information aligns the workstation-oriented card with AMD's Navi 33 GPU—the same GFX1102 designation appears within TPU's database entry (look at the Shader ISA (GFX11.0) graphics feature). VideoCardz reckons that the leaked Radeon PRO W7600 is closely related to AMD's mobile Radeon RX 7700/7600 series—based on Navi 33, due to their matching IDs. Their report proposed: "Based on this data, the GPU is expected to have a clock speed of 1940 MHz. Comparatively, this is 310 MHz lower than the Radeon RX 7600 gaming model, which refers to its Game Clock of 2250 MHz. The Compute Unit field refers to "Workgroup Processor/WGP" cluster, so the card features 32 Compute Units or 2048 Stream Processors, the same configuration as the RX 7600. The card is listed with 8 GB of memory, but it remains uncertain whether this model will support ECC (error correction), a feature found in the W7900/W7800 models. It's important to note that the W6600 did not utilize this type of memory."


Imagination GPUs Gains OpenGL 4.6 Support
When it comes to APIs, OpenGL is something of a classic. According to the Khronos Group, OpenGL is the most widely adopted 2D and 3D graphics API. Since its launch in 1992 it has been used extensively by software developers for PCs and workstations to create high-performance, visually compelling graphics applications for markets such as CAD, content creation, entertainment, game development and virtual reality.
To date, Imagination GPUs have natively supported OpenGL up until Release 3.3 as well as OpenGL ES (the version of OpenGL for embedded systems), Vulkan (a cross-platform graphics API) and OpenCL (an API for parallel programming). However, thanks to the increasing performance of our top-end GPUs, especially with the likes of the DXT-72-2304, they present a competitive offering to the data centre and desktop (DCD) market. Indeed, we have multiple customers - including the likes of Innosilicon - choosing Imagination GPUs for the flexibility an IP solution, their scalability and their ability to offer up to 6 TFLOPS of compute.
To date, Imagination GPUs have natively supported OpenGL up until Release 3.3 as well as OpenGL ES (the version of OpenGL for embedded systems), Vulkan (a cross-platform graphics API) and OpenCL (an API for parallel programming). However, thanks to the increasing performance of our top-end GPUs, especially with the likes of the DXT-72-2304, they present a competitive offering to the data centre and desktop (DCD) market. Indeed, we have multiple customers - including the likes of Innosilicon - choosing Imagination GPUs for the flexibility an IP solution, their scalability and their ability to offer up to 6 TFLOPS of compute.

Intel to Introduce Core Ultra Brand Extension with "Meteor Lake," iGPU Packs 128 EU
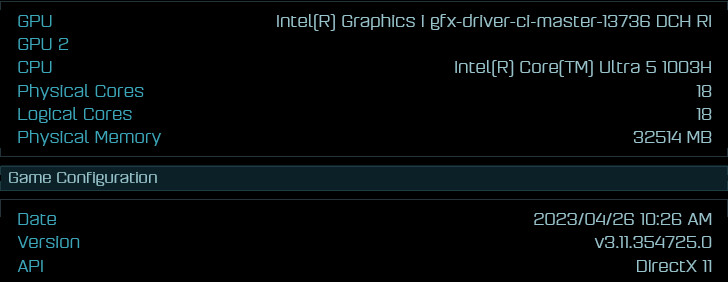
Intel is planning a major change in its client processor brand extensions with its next-generation mobile processors codenamed "Meteor Lake." The company is working to introduce the new Core Ultra brand extensions, where "Ultra" replaces the "i" in extensions such as i3, i5, i7, and i9 in some processor models. An example of such a brand extension would be the "Core Ultra 5 1003H." Ashes of the Singularity benchmark leaks of the processors surfaced on social media.
The benchmark also detects 128 EU (1,024 unified shaders) for the iGPU powering "Meteor Lake." If true, this iGPU could offer performance that's in the league of an Arc A380 discrete GPU, with some performance lost to the shared memory setup compared to the A380 with its dedicated graphics memory. The iGPU clock speed is detected to be 2.10 GHz, and having 4 MB of L2 cache, the last-level cache local to the Graphics Tile. The detection string for the iGPU as reported by its OpenCL ICD reads "Intel(R) Graphics i gfx-driver-ci-master-13736 DCH RI (1024S 128C SM3.0 2.1GHz, 4MB L2, 12.7GB)."

The benchmark also detects 128 EU (1,024 unified shaders) for the iGPU powering "Meteor Lake." If true, this iGPU could offer performance that's in the league of an Arc A380 discrete GPU, with some performance lost to the shared memory setup compared to the A380 with its dedicated graphics memory. The iGPU clock speed is detected to be 2.10 GHz, and having 4 MB of L2 cache, the last-level cache local to the Graphics Tile. The detection string for the iGPU as reported by its OpenCL ICD reads "Intel(R) Graphics i gfx-driver-ci-master-13736 DCH RI (1024S 128C SM3.0 2.1GHz, 4MB L2, 12.7GB)."

Mobileye Launches EyeQ Kit: New SDK for Advanced Safety and Driver-Assistance Systems
Mobileye, an Intel company, has launched the EyeQ Kit - its first software development kit (SDK) for the EyeQ system-on-chip that powers driver-assistance and future autonomous technologies for automakers worldwide. Built to leverage the powerful and highly power-efficient architecture of the upcoming EyeQ 6 High and EyeQ Ultra processors, EyeQ Kit allows automakers to utilize Mobileye's proven core technology, while deploying their own differentiated code and human-machine interface tools on the EyeQ platform.
"EyeQ Kit allows our customers to benefit from the best of both worlds — Mobileye's proven and validated core technologies, along with their own expertise in delivering unique driver experiences and interfaces. As more core functions of vehicles are defined in software, we know our customers will want the flexibility and capacity they need to differentiate and define their brands through code."
- Prof. Amnon Shashua, Mobileye president and chief executive officer
"EyeQ Kit allows our customers to benefit from the best of both worlds — Mobileye's proven and validated core technologies, along with their own expertise in delivering unique driver experiences and interfaces. As more core functions of vehicles are defined in software, we know our customers will want the flexibility and capacity they need to differentiate and define their brands through code."
- Prof. Amnon Shashua, Mobileye president and chief executive officer

Moore Threads Unveils MTT S60 & MTT S2000 Graphics Cards with DirectX Support
Chinese company Moore Threads has unveiled their MTT GPU series just 18 months after the company's establishment in 2020. The MT Unified System Architecture (MUSA) architecture is the first for any Chinese company to be developed fully domestically and includes support for DirectX, OpenCL, OpenGL, Vulkan, and CUDA. The company announced the MTT S60 and MTT S2000 single slot desktop graphics cards for gaming and server applications at a recent event. The MTT S60 is manufactured on a 12 nm node and features 2,048 MUSA cores paired with 8 GB of LPGDDR4X memory offering 6 TFLOPs of performance. The MTT S2000 is also manufactured on a 12 nm node and doubles the number of MUSA cores to 4096 paired with 32 GB of undisclosed video memory allowing it to reach 12 TFLOPs.
Moore Threads joins Intel in supporting AV1 encoding on a consumer GPU with MUSA cards featuring H.264, H.265, and AV1 encoding support in addition to H.264, H.265, AV1, VP8, and VP9 decoding. The company is also developing a physics engine dubbed Alphacore which is said to work with existing tools such as Unity, Unreal Engine, and Houdini to accelerate physics performance by 5 to 10 times. The only gaming performance shown was a simple demonstration of the MTT S60 running League of Legends at 1080p without any frame rate details.


Moore Threads joins Intel in supporting AV1 encoding on a consumer GPU with MUSA cards featuring H.264, H.265, and AV1 encoding support in addition to H.264, H.265, AV1, VP8, and VP9 decoding. The company is also developing a physics engine dubbed Alphacore which is said to work with existing tools such as Unity, Unreal Engine, and Houdini to accelerate physics performance by 5 to 10 times. The only gaming performance shown was a simple demonstration of the MTT S60 running League of Legends at 1080p without any frame rate details.



NVIDIA MX550 Rumored to Feature GA107 GPU with 2 GB of GDDR6 memory
The NVIDIA MX550 has allegedly surfaced as part of a new Lenovo laptop in a Geekbench listing paired with an Intel Core i7-1260P 12 core, 16 thread processor. The card is described as a "Graphics Device" in the Geekbench listing however according to ITHome this is actually the upcoming MX550 entry-level mobile graphics card. The card is supposedly based on the Ampere GA107 GPU with 16 Compute Units and 128 CUDA cores paired with 2 GB of GDDR6 memory. The MX550 is the successor to the MX450 launched in August 2020 and should offer a roughly 15% performance increase according to the Geekbench OpenCL score. We have limited information on the availability of the card or the remainder of the MX500 series except that NVIDIA may officially announce them sometime early next year.

Chinese Innosilicon Fenghua No.1 Graphics Card Supports PCIe 4.0, HDMI 2.1, GDDR6X, & DirectX
Chinese company Innosilicon Technology has recently announced their Fenghua No.1 high-performance server graphics card. The card features a dual-fan cooling design with HDMI 2.1 and Embedded DisplayPort 1.4 video connectors. The card will utilize a PCIe 4.0 connector and features GDDR6X memory developed by Innosilicon Technology with potential speeds of 21 Gbps. We have seen announcements from Chinese companies with similar products in the past but this recent announcement is the first to include support for a variety of graphics APIs including DirectX. The press release from the company didn't specify the DirectX version supported but also noted that the card will support OpenGL, OpenGLES, OpenCL, and Vulkan which will enable VR, AR, and AI applications.

AMD Radeon PRO V620 GPU Delivers Powerful, Multi-Purpose Data Center Visual Performance for Today's Demanding Cloud Workloads
AMD announced the AMD Radeon PRO V620 GPU, built with the latest AMD RDNA 2 architecture which delivers high-performance GPU acceleration for today's demanding cloud workloads including immersive AAA game experiences, intensive 3D workloads and modern office productivity applications at scale in the cloud.
With its innovative GPU-partitioning capabilities, multi-stream hardware accelerated encoders and 32 GB GDDR6 memory, the AMD Radeon PRO V620 offers dedicated GPU resources that scale to multiple graphics users, helping ensure cost-effective graphics acceleration for a range of workloads. Built using the same GPU architecture that powers the latest generation game consoles and PC game experiences, the AMD Radeon PRO V620 GPU is also designed to develop and deliver immersive AAA game experiences.
With its innovative GPU-partitioning capabilities, multi-stream hardware accelerated encoders and 32 GB GDDR6 memory, the AMD Radeon PRO V620 offers dedicated GPU resources that scale to multiple graphics users, helping ensure cost-effective graphics acceleration for a range of workloads. Built using the same GPU architecture that powers the latest generation game consoles and PC game experiences, the AMD Radeon PRO V620 GPU is also designed to develop and deliver immersive AAA game experiences.

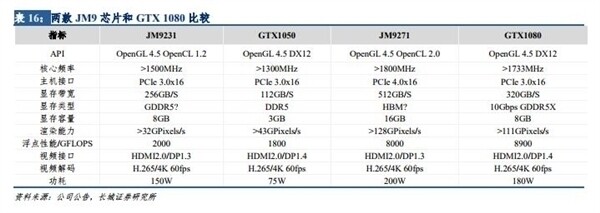
Jingjia Micro JM9 GPU Series Targeting GTX 1080 Performance Tapes Out
The Chinese Electronics company Jingjia Micro have recently completed the tapeout of their JM9 GPU series almost 2 years after they first announced the lineup. The JM9 series will consist of two GPUs with the entry-level JM9231 targeting GTX 1050 performance while the higher-end JM9271 aims for the GTX 1080. The JM9231 is stated to feature a clock speed above 1.5 GHz, 8 GB of GDDR5 memory, and will provide 2 TFLOPS of performance within a 150 W TDP through a PCIe Gen3 x16 interface. The JM9271 increases the clock speed to above 1.8 GHz and is paired with 16 GB of HBM memory which should offer 8 TFLOPS of single-precision performance to rival the GTX 1080. The card manages to do this within a TDP package of 200 W and also includes PCIe Gen4 x16 support. The two cards both support HDMI 2.0 in addition to DisplayPort 1.3 for the JM9231 and DisplayPort 1.4 for the JM9271.
While the JM9271 may target GTX 1080 performance it only features OpenGL and OpenCL API support lacking DirectX or Vulkan compatibility greatly reducing its use for gaming. The cards were originally expected to be available in 2020 but after various delays they are now ready to enter production. These products are highly unlikely to make their way outside of the Chinese mainland and if they did we wouldn't expect them to have much impact on the global market.

While the JM9271 may target GTX 1080 performance it only features OpenGL and OpenCL API support lacking DirectX or Vulkan compatibility greatly reducing its use for gaming. The cards were originally expected to be available in 2020 but after various delays they are now ready to enter production. These products are highly unlikely to make their way outside of the Chinese mainland and if they did we wouldn't expect them to have much impact on the global market.

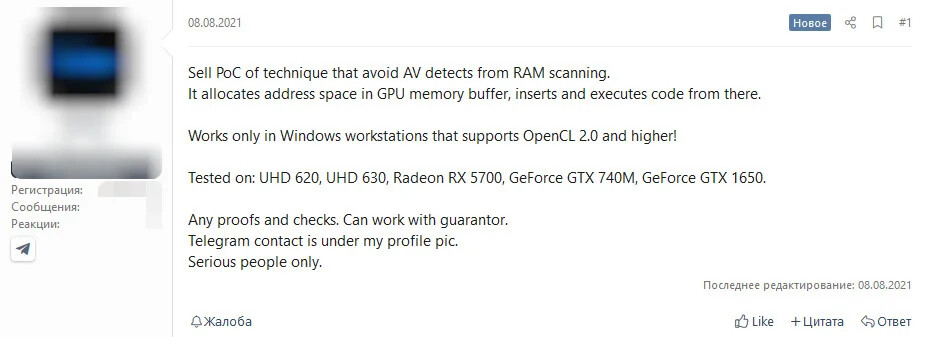
Hackers Innovate Way to Store and Execute Malware from Video Memory to Evade Anti-Malware
Cybercriminals have innovated a way to store malware code inside GPU dedicated memory (video memory), and execute code directly from there. Execution from video memory may not be new, but they've mostly been confined to the academic space, and unrefined. This would be the first time a proof-of-concept of a working tool that injects executables to video memory, surfaced on a hacker forum.
The tool relies on OpenCL 2.0, and its developers claim to have successfully tested it on Intel Gen9, AMD RDNA, NVIDIA Kepler, and NVIDIA Turing graphics architectures (i.e. UHD 620, UHD 630, Radeon RX 5700, GeForce GTX 740M, and GTX 1650). What makes this ingenious is that the malware binary is stored entirely in GPU memory address-space and is executed by the GPU, rather than the CPUs. Conventional anti-malware software are only known to scan the system memory, disks, and network traffic for malware; but not video memory. Hopefully this will change.

The tool relies on OpenCL 2.0, and its developers claim to have successfully tested it on Intel Gen9, AMD RDNA, NVIDIA Kepler, and NVIDIA Turing graphics architectures (i.e. UHD 620, UHD 630, Radeon RX 5700, GeForce GTX 740M, and GTX 1650). What makes this ingenious is that the malware binary is stored entirely in GPU memory address-space and is executed by the GPU, rather than the CPUs. Conventional anti-malware software are only known to scan the system memory, disks, and network traffic for malware; but not video memory. Hopefully this will change.

Apr 16th, 2025 09:47 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- The TPU UK Clubhouse (26116)
- Help me identify Chip of this DDR4 RAM (21)
- Last game you purchased? (772)
- 5070ti overclock...what are your settings? (5)
- Windows 11 fresh install to do list (23)
- How to relubricate a fan and/or service a troublesome/noisy fan. (229)
- GPU Memory Temprature is always high (16)
- Help For XFX RX 590 GME Chinese - Vbios (4)
- PCGH: "hidden site" to see total money spend on steam (3)
- Share your AIDA 64 cache and memory benchmark here (3053)
Popular Reviews
- G.SKILL Trident Z5 NEO RGB DDR5-6000 32 GB CL26 Review - AMD EXPO
- ASUS GeForce RTX 5080 TUF OC Review
- DAREU A950 Wing Review
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Thermaltake TR100 Review
- Zotac GeForce RTX 5070 Ti Amp Extreme Review
- TerraMaster F8 SSD Plus Review - Compact and quiet
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (124)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)
- NVIDIA Pushes GeForce RTX 5060 Ti Launch to Mid-April, RTX 5060 to May (77)