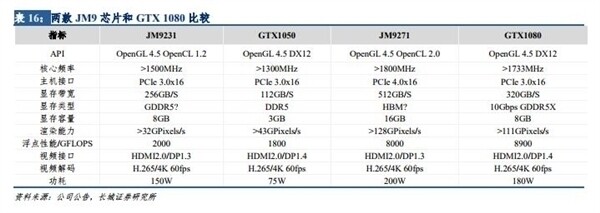
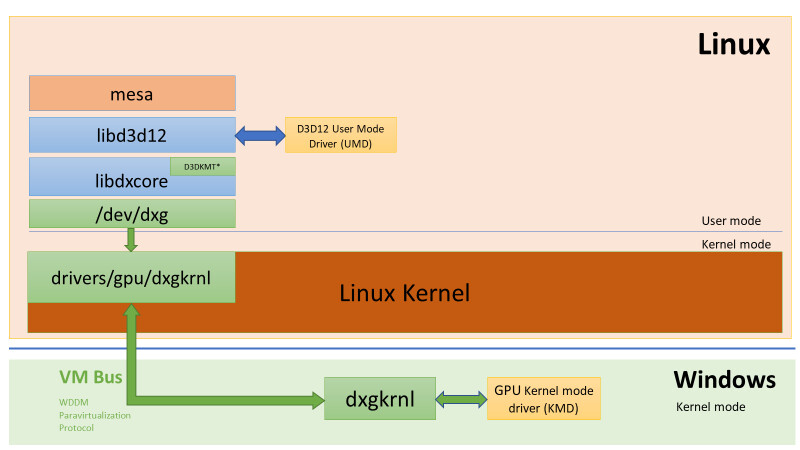
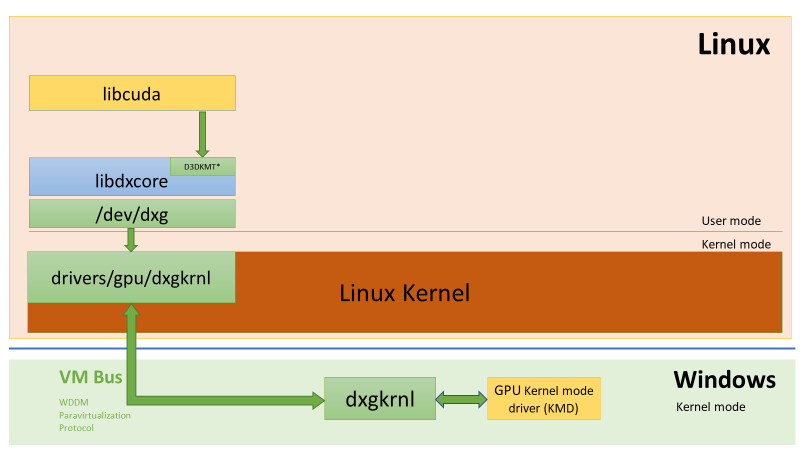
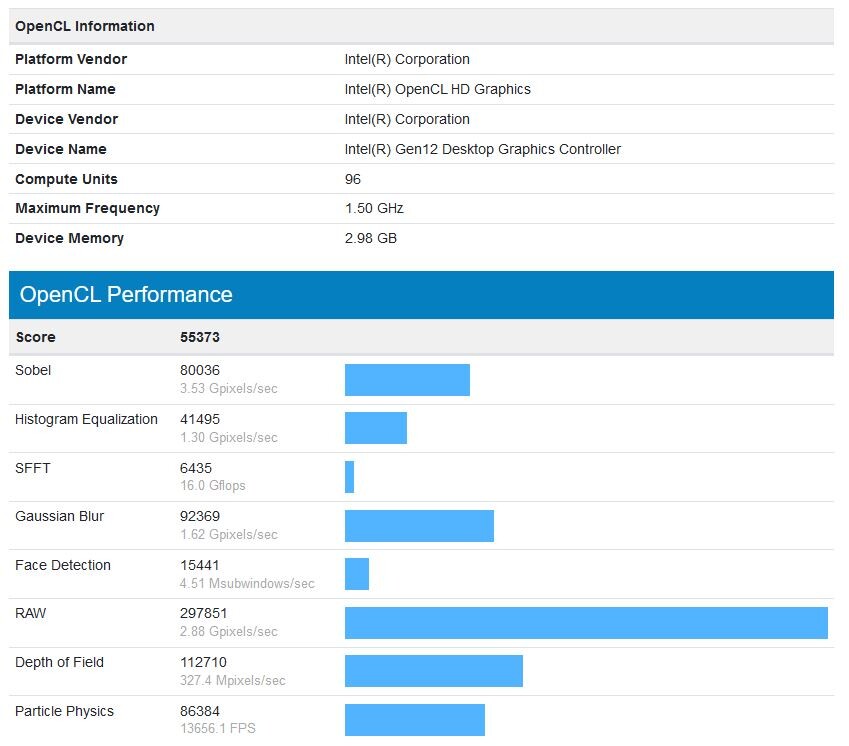
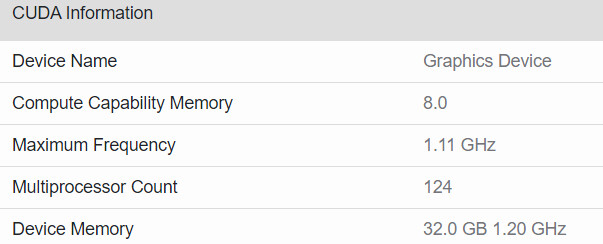
NVIDIA MX550 Rumored to Feature GA107 GPU with 2 GB of GDDR6 memory
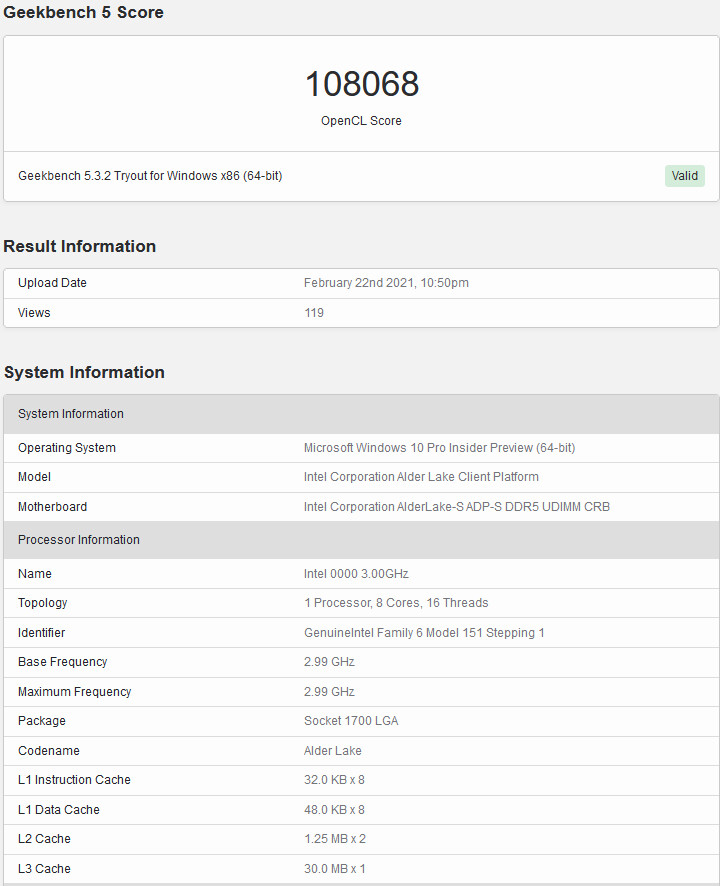
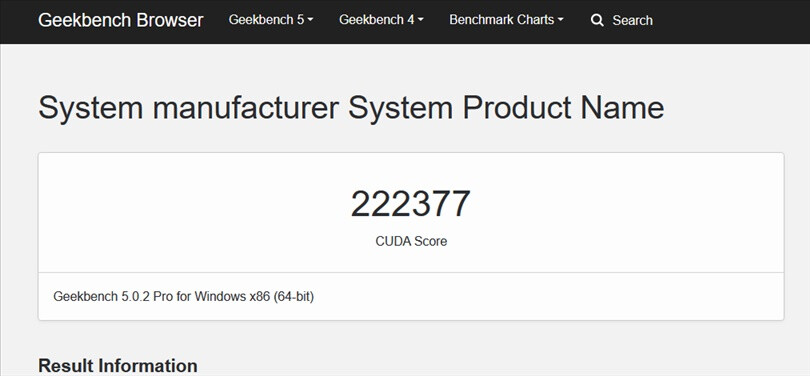
The NVIDIA MX550 has allegedly surfaced as part of a new Lenovo laptop in a Geekbench listing paired with an Intel Core i7-1260P 12 core, 16 thread processor. The card is described as a "Graphics Device" in the Geekbench listing however according to ITHome this is actually the upcoming MX550 entry-level mobile graphics card. The card is supposedly based on the Ampere GA107 GPU with 16 Compute Units and 128 CUDA cores paired with 2 GB of GDDR6 memory. The MX550 is the successor to the MX450 launched in August 2020 and should offer a roughly 15% performance increase according to the Geekbench OpenCL score. We have limited information on the availability of the card or the remainder of the MX500 series except that NVIDIA may officially announce them sometime early next year.