Apr 4th, 2025 23:47 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- XFX Radeon RX 580 8GB (1)
- New posts added to last post (10)
- need help choosing an upgrade (0)
- EK Quantum Velocity intel to amd conversion (10)
- I have an idea for cooling 1kW GPU power. (24)
- What's your latest tech purchase? (23477)
- Last game you purchased? (748)
- TechPowerUp Screenshot Thread (MASSIVE 56K WARNING) (4267)
- What are you playing? (23342)
- [Intel AX1xx/AX2xx/AX4xx/AX16xx/BE2xx/BE17xx] Intel Modded Wi-Fi Driver with Intel® Killer™ Features (302)
Popular Reviews
- DDR5 CUDIMM Explained & Benched - The New Memory Standard
- PowerColor Radeon RX 9070 Hellhound Review
- Corsair RM750x Shift 750 W Review
- ASUS Prime X870-P Wi-Fi Review
- Sapphire Radeon RX 9070 XT Pulse Review
- Pwnage Trinity CF Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Palit GeForce RTX 5070 GamingPro OC Review
Controversial News Posts
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (97)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (90)
- Retailers Anticipate Increased Radeon RX 9070 Series Prices, After Initial Shipments of "MSRP" Models (90)
News Posts matching #Stable Diffusion
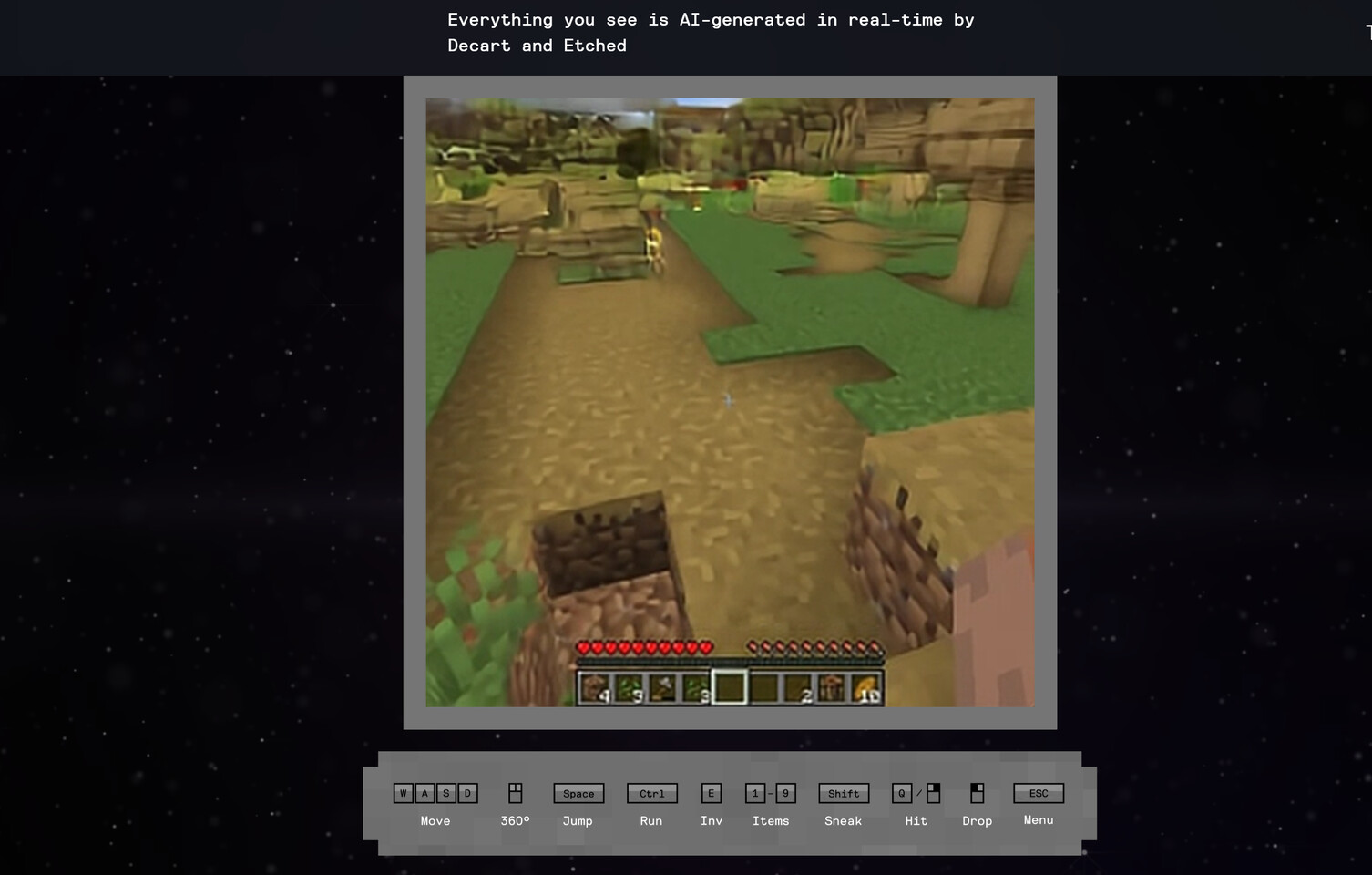
Return to Keyword BrowsingEtched Introduces AI-Powered Games Without GPUs, Displays Minecraft Replica
The gaming industry is about to get massively disrupted. Instead of using game engines to power games, we are now witnessing an entirely new and crazy concept. A startup specializing in designing ASICs specifically for Transformer architecture, the foundation behind generative AI models like GPT/Claude/Stable Diffusion, has showcased a demo in partnership with Decart of a Minecraft clone being entirely generated and operated by AI instead of the traditional game engine. While we use AI to create images and videos based on specific descriptions and output pretty realistic content, having an AI model spit out an entire playable game is something different. Oasis is the first playable, real-time, real-time, open-world AI model that takes users' input and generates real-time gameplay, including physics, game rules, and graphics.
An interesting thing to point out is the hardware that powers this setup. Using a single NVIDIA H100 GPU, this 500-million parameter Oasis model can run at 720p resolution at 20 generated frames per second. Due to limitations of accelerators like NVIDIA's H100/B200, gameplay at 4K is almost impossible. However, Etched has its own accelerator called Sohu, which is specialized in accelerating transformer architectures. Eight NVIDIA H100 GPUs can power five Oasis models to five users, while the eight Sohu cards are capable of serving 65 Oasis runs to 65 users. This is more than a 10x increase in inference capability compared to NVIDIA's hardware on a single-use case alone. The accelerator is designed to run much larger models like future 100 billion-parameter generative AI video game models that can output 4K 30 FPS, all thanks to 144 GB of HBM3E memory, yielding 1,152 GB in eight-accelerator server configuration.



An interesting thing to point out is the hardware that powers this setup. Using a single NVIDIA H100 GPU, this 500-million parameter Oasis model can run at 720p resolution at 20 generated frames per second. Due to limitations of accelerators like NVIDIA's H100/B200, gameplay at 4K is almost impossible. However, Etched has its own accelerator called Sohu, which is specialized in accelerating transformer architectures. Eight NVIDIA H100 GPUs can power five Oasis models to five users, while the eight Sohu cards are capable of serving 65 Oasis runs to 65 users. This is more than a 10x increase in inference capability compared to NVIDIA's hardware on a single-use case alone. The accelerator is designed to run much larger models like future 100 billion-parameter generative AI video game models that can output 4K 30 FPS, all thanks to 144 GB of HBM3E memory, yielding 1,152 GB in eight-accelerator server configuration.




NVIDIA Blackwell Sets New Standard for Generative AI in MLPerf Inference Benchmark
As enterprises race to adopt generative AI and bring new services to market, the demands on data center infrastructure have never been greater. Training large language models is one challenge, but delivering LLM-powered real-time services is another. In the latest round of MLPerf industry benchmarks, Inference v4.1, NVIDIA platforms delivered leading performance across all data center tests. The first-ever submission of the upcoming NVIDIA Blackwell platform revealed up to 4x more performance than the NVIDIA H100 Tensor Core GPU on MLPerf's biggest LLM workload, Llama 2 70B, thanks to its use of a second-generation Transformer Engine and FP4 Tensor Cores.
The NVIDIA H200 Tensor Core GPU delivered outstanding results on every benchmark in the data center category - including the latest addition to the benchmark, the Mixtral 8x7B mixture of experts (MoE) LLM, which features a total of 46.7 billion parameters, with 12.9 billion parameters active per token. MoE models have gained popularity as a way to bring more versatility to LLM deployments, as they're capable of answering a wide variety of questions and performing more diverse tasks in a single deployment. They're also more efficient since they only activate a few experts per inference - meaning they deliver results much faster than dense models of a similar size.
The NVIDIA H200 Tensor Core GPU delivered outstanding results on every benchmark in the data center category - including the latest addition to the benchmark, the Mixtral 8x7B mixture of experts (MoE) LLM, which features a total of 46.7 billion parameters, with 12.9 billion parameters active per token. MoE models have gained popularity as a way to bring more versatility to LLM deployments, as they're capable of answering a wide variety of questions and performing more diverse tasks in a single deployment. They're also more efficient since they only activate a few experts per inference - meaning they deliver results much faster than dense models of a similar size.


Intel Releases AI Playground, a Unified Generative AI and Chat App for Intel Arc GPUs
Intel on Monday rolled out the first public release of AI Playground, an AI productivity suite the company showcased in its 2024 Computex booth. AI Playground is a well-packaged suite of generative AI applications and a chatbot, which are designed to leverage Intel Arc discrete GPUs with at least 8 GB of video memory. All utilities in the suite are designed under the OpenVINO framework, and take advantage of the XMX cores of Arc A-series discrete GPUs. Currently, only three GPU models from the lineup come with 8 GB or higher amounts of video memory, the A770, A750, and A580; and their mobile variants. The company is working on a variant of the suite that can work on Intel Core Ultra-H series processors, where it uses a combination of the NPU and the iGPU for acceleration. AI Playground is open source. Intel put in effort to make the suite as client-friendly as possible, by giving it a packaged installer that looks after installation of all software dependencies.
Intel AI Playground tools include an image generative AI that can turn prompts into standard or HD images, which is based on Stable Diffusion backed by DreamShaper 8 and Juggernaut XL models. It also supports Phi3, LCM LoRA, and LCM LoRA SDXL. All of these have been optimized for acceleration on Arc "Alchemist" GPUs. The utility also includes an AI image enhancement utility that can be used for upscaling along with detail reconstruction, styling, inpainting and outpainting, and certain kinds of image manipulation. The third most important tool is the text AI chatbot with all popular LLMs.
DOWNLOAD: Intel AI Playground
Intel AI Playground tools include an image generative AI that can turn prompts into standard or HD images, which is based on Stable Diffusion backed by DreamShaper 8 and Juggernaut XL models. It also supports Phi3, LCM LoRA, and LCM LoRA SDXL. All of these have been optimized for acceleration on Arc "Alchemist" GPUs. The utility also includes an AI image enhancement utility that can be used for upscaling along with detail reconstruction, styling, inpainting and outpainting, and certain kinds of image manipulation. The third most important tool is the text AI chatbot with all popular LLMs.
DOWNLOAD: Intel AI Playground
Stability AI Outs Stable Diffusion 3 Medium, Company's Most Advanced Image Generation Model
Stability AI, a maker of various generative AI models and the company behind text-to-image Stable Diffusion models, has released its latest Stable Diffusion 3 (SD3) Medium AI model. Running on two billion dense parameters, the SD3 Medium is the company's most advanced text-to-image model to date. It boasts features like generating highly realistic and detailed images across a wide range of styles and compositions. It demonstrates capabilities in handling intricate prompts that involve spatial reasoning, actions, and diverse artistic directions. The model's innovative architecture, including the 16-channel variational autoencoder (VAE), allows it to overcome common challenges faced by other models, such as accurately rendering realistic human faces and hands.
Additionally, it achieves exceptional text quality, with precise letter formation, kerning, and spacing, thanks to the Diffusion Transformer architecture. Notably, the model is resource-efficient, capable of running smoothly on consumer-grade GPUs without compromising performance due to its low VRAM footprint. Furthermore, it exhibits impressive fine-tuning abilities, allowing it to absorb and replicate nuanced details from small datasets, making it highly customizable for specific use cases that users may have. Being an open-weight model, it is available for download on HuggingFace, and it has libraries optimized for both NVIDIA's TensorRT (all modern NVIDIA GPUs) and AMD Radeon/Instinct GPUs.
Additionally, it achieves exceptional text quality, with precise letter formation, kerning, and spacing, thanks to the Diffusion Transformer architecture. Notably, the model is resource-efficient, capable of running smoothly on consumer-grade GPUs without compromising performance due to its low VRAM footprint. Furthermore, it exhibits impressive fine-tuning abilities, allowing it to absorb and replicate nuanced details from small datasets, making it highly customizable for specific use cases that users may have. Being an open-weight model, it is available for download on HuggingFace, and it has libraries optimized for both NVIDIA's TensorRT (all modern NVIDIA GPUs) and AMD Radeon/Instinct GPUs.

NVIDIA MLPerf Training Results Showcase Unprecedented Performance and Elasticity
The full-stack NVIDIA accelerated computing platform has once again demonstrated exceptional performance in the latest MLPerf Training v4.0 benchmarks. NVIDIA more than tripled the performance on the large language model (LLM) benchmark, based on GPT-3 175B, compared to the record-setting NVIDIA submission made last year. Using an AI supercomputer featuring 11,616 NVIDIA H100 Tensor Core GPUs connected with NVIDIA Quantum-2 InfiniBand networking, NVIDIA achieved this remarkable feat through larger scale - more than triple that of the 3,584 H100 GPU submission a year ago - and extensive full-stack engineering.
Thanks to the scalability of the NVIDIA AI platform, Eos can now train massive AI models like GPT-3 175B even faster, and this great AI performance translates into significant business opportunities. For example, in NVIDIA's recent earnings call, we described how LLM service providers can turn a single dollar invested into seven dollars in just four years running the Llama 3 70B model on NVIDIA HGX H200 servers. This return assumes an LLM service provider serving Llama 3 70B at $0.60/M tokens, with an HGX H200 server throughput of 24,000 tokens/second.
Thanks to the scalability of the NVIDIA AI platform, Eos can now train massive AI models like GPT-3 175B even faster, and this great AI performance translates into significant business opportunities. For example, in NVIDIA's recent earnings call, we described how LLM service providers can turn a single dollar invested into seven dollars in just four years running the Llama 3 70B model on NVIDIA HGX H200 servers. This return assumes an LLM service provider serving Llama 3 70B at $0.60/M tokens, with an HGX H200 server throughput of 24,000 tokens/second.

New Performance Optimizations Supercharge NVIDIA RTX AI PCs for Gamers, Creators and Developers
NVIDIA today announced at Microsoft Build new AI performance optimizations and integrations for Windows that help deliver maximum performance on NVIDIA GeForce RTX AI PCs and NVIDIA RTX workstations. Large language models (LLMs) power some of the most exciting new use cases in generative AI and now run up to 3x faster with ONNX Runtime (ORT) and DirectML using the new NVIDIA R555 Game Ready Driver. ORT and DirectML are high-performance tools used to run AI models locally on Windows PCs.
WebNN, an application programming interface for web developers to deploy AI models, is now accelerated with RTX via DirectML, enabling web apps to incorporate fast, AI-powered capabilities. And PyTorch will support DirectML execution backends, enabling Windows developers to train and infer complex AI models on Windows natively. NVIDIA and Microsoft are collaborating to scale performance on RTX GPUs. These advancements build on NVIDIA's world-leading AI platform, which accelerates more than 500 applications and games on over 100 million RTX AI PCs and workstations worldwide.
WebNN, an application programming interface for web developers to deploy AI models, is now accelerated with RTX via DirectML, enabling web apps to incorporate fast, AI-powered capabilities. And PyTorch will support DirectML execution backends, enabling Windows developers to train and infer complex AI models on Windows natively. NVIDIA and Microsoft are collaborating to scale performance on RTX GPUs. These advancements build on NVIDIA's world-leading AI platform, which accelerates more than 500 applications and games on over 100 million RTX AI PCs and workstations worldwide.


More than 500 AI Models Run Optimized on Intel Core Ultra Processors
Today, Intel announced it surpassed 500 AI models running optimized on new Intel Core Ultra processors - the industry's premier AI PC processor available in the market today, featuring new AI experiences, immersive graphics and optimal battery life. This significant milestone is a result of Intel's investment in client AI, the AI PC transformation, framework optimizations and AI tools including OpenVINO toolkit. The 500 models, which can be deployed across the central processing unit (CPU), graphics processing unit (GPU) and neural processing unit (NPU), are available across popular industry sources, including OpenVINO Model Zoo, Hugging Face, ONNX Model Zoo and PyTorch. The models draw from categories of local AI inferencing, including large language, diffusion, super resolution, object detection, image classification/segmentation, computer vision and others.
"Intel has a rich history of working with the ecosystem to bring AI applications to client devices, and today we celebrate another strong chapter in the heritage of client AI by surpassing 500 pre-trained AI models running optimized on Intel Core Ultra processors. This unmatched selection reflects our commitment to building not only the PC industry's most robust toolchain for AI developers, but a rock-solid foundation AI software users can implicitly trust."
-Robert Hallock, Intel vice president and general manager of AI and technical marketing in the Client Computing Group
"Intel has a rich history of working with the ecosystem to bring AI applications to client devices, and today we celebrate another strong chapter in the heritage of client AI by surpassing 500 pre-trained AI models running optimized on Intel Core Ultra processors. This unmatched selection reflects our commitment to building not only the PC industry's most robust toolchain for AI developers, but a rock-solid foundation AI software users can implicitly trust."
-Robert Hallock, Intel vice president and general manager of AI and technical marketing in the Client Computing Group

NVIDIA Launches the RTX A400 and A1000 Professional Graphics Cards
AI integration across design and productivity applications is becoming the new standard, fueling demand for advanced computing performance. This means professionals and creatives will need to tap into increased compute power, regardless of the scale, complexity or scope of their projects. To meet this growing need, NVIDIA is expanding its RTX professional graphics offerings with two new NVIDIA Ampere architecture-based GPUs for desktops: the NVIDIA RTX A400 and NVIDIA RTX A1000.
They expand access to AI and ray tracing technology, equipping professionals with the tools they need to transform their daily workflows. The RTX A400 GPU introduces accelerated ray tracing and AI to the RTX 400 series GPUs. With 24 Tensor Cores for AI processing, it surpasses traditional CPU-based solutions, enabling professionals to run cutting-edge AI applications, such as intelligent chatbots and copilots, directly on their desktops. The GPU delivers real-time ray tracing, so creators can build vivid, physically accurate 3D renders that push the boundaries of creativity and realism.
They expand access to AI and ray tracing technology, equipping professionals with the tools they need to transform their daily workflows. The RTX A400 GPU introduces accelerated ray tracing and AI to the RTX 400 series GPUs. With 24 Tensor Cores for AI processing, it surpasses traditional CPU-based solutions, enabling professionals to run cutting-edge AI applications, such as intelligent chatbots and copilots, directly on their desktops. The GPU delivers real-time ray tracing, so creators can build vivid, physically accurate 3D renders that push the boundaries of creativity and realism.


ASRock Reveals AI QuickSet 2024 Q1 Update With Two New AI Tools
Leading global motherboard manufacturer, ASRock, has successively released software based on Microsoft Windows 10/11 and Canonical Ubuntu Linux platforms since the end of last year, which can help users quickly download, install and configure artificial intelligence software. After receiving great response from the market, ASRock has revealed the 2024 Q1 update of AI QuickSet today, adding two new artificial intelligence (AI) tools, Whisper Desktop and AudioCraft, allowing users of ASRock AMD Radeon RX 7000 series graphics cards to experience more diverse artificial intelligence (AI) applications!
ASRock AI QuickSet software tool 1.2.4 Windows version supports Microsoft Windows 10/11 64-bit operating system, while Linux version 1.1.6 supports Canonical Ubuntu 22.04.4 Desktop (64-bit) operating system, through ASRock AMD Radeon RX 7000 series graphics cards and AMD ROCm software platform provide powerful computing capabilities to support a variety of well-known artificial intelligence (AI) applications. The 1.2.4 Windows version supports image generation tools such as DirectML Shark and Stable Diffusion web UI, as well as the newly added Whisper Desktop speech recognition tool; and the 1.1.6 Linux version supports Image/Manga Translator, Stable Diffusion CLI & web UI image generation tool, and Text generation web UI Llama 2 text generation tool using Meta Llama 2 language model, Ultralytics YOLOv8 object recognition tool, and the newly added AudioCraft audio generation tool.
ASRock AI QuickSet software tool 1.2.4 Windows version supports Microsoft Windows 10/11 64-bit operating system, while Linux version 1.1.6 supports Canonical Ubuntu 22.04.4 Desktop (64-bit) operating system, through ASRock AMD Radeon RX 7000 series graphics cards and AMD ROCm software platform provide powerful computing capabilities to support a variety of well-known artificial intelligence (AI) applications. The 1.2.4 Windows version supports image generation tools such as DirectML Shark and Stable Diffusion web UI, as well as the newly added Whisper Desktop speech recognition tool; and the 1.1.6 Linux version supports Image/Manga Translator, Stable Diffusion CLI & web UI image generation tool, and Text generation web UI Llama 2 text generation tool using Meta Llama 2 language model, Ultralytics YOLOv8 object recognition tool, and the newly added AudioCraft audio generation tool.

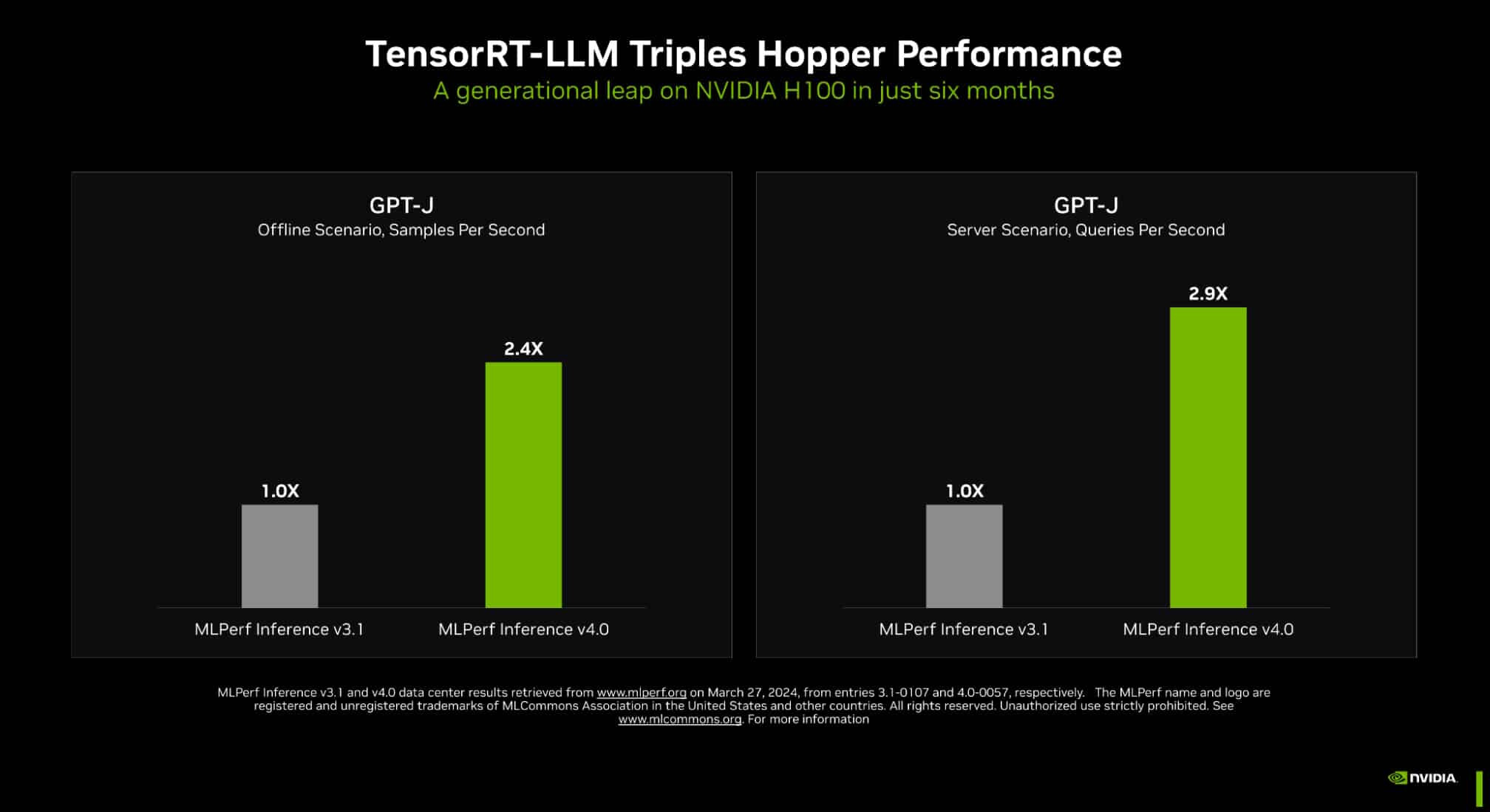
NVIDIA Hopper Leaps Ahead in Generative AI at MLPerf
It's official: NVIDIA delivered the world's fastest platform in industry-standard tests for inference on generative AI. In the latest MLPerf benchmarks, NVIDIA TensorRT-LLM—software that speeds and simplifies the complex job of inference on large language models—boosted the performance of NVIDIA Hopper architecture GPUs on the GPT-J LLM nearly 3x over their results just six months ago. The dramatic speedup demonstrates the power of NVIDIA's full-stack platform of chips, systems and software to handle the demanding requirements of running generative AI. Leading companies are using TensorRT-LLM to optimize their models. And NVIDIA NIM—a set of inference microservices that includes inferencing engines like TensorRT-LLM—makes it easier than ever for businesses to deploy NVIDIA's inference platform.
Raising the Bar in Generative AI
TensorRT-LLM running on NVIDIA H200 Tensor Core GPUs—the latest, memory-enhanced Hopper GPUs—delivered the fastest performance running inference in MLPerf's biggest test of generative AI to date. The new benchmark uses the largest version of Llama 2, a state-of-the-art large language model packing 70 billion parameters. The model is more than 10x larger than the GPT-J LLM first used in the September benchmarks. The memory-enhanced H200 GPUs, in their MLPerf debut, used TensorRT-LLM to produce up to 31,000 tokens/second, a record on MLPerf's Llama 2 benchmark. The H200 GPU results include up to 14% gains from a custom thermal solution. It's one example of innovations beyond standard air cooling that systems builders are applying to their NVIDIA MGX designs to take the performance of Hopper GPUs to new heights.


Raising the Bar in Generative AI
TensorRT-LLM running on NVIDIA H200 Tensor Core GPUs—the latest, memory-enhanced Hopper GPUs—delivered the fastest performance running inference in MLPerf's biggest test of generative AI to date. The new benchmark uses the largest version of Llama 2, a state-of-the-art large language model packing 70 billion parameters. The model is more than 10x larger than the GPT-J LLM first used in the September benchmarks. The memory-enhanced H200 GPUs, in their MLPerf debut, used TensorRT-LLM to produce up to 31,000 tokens/second, a record on MLPerf's Llama 2 benchmark. The H200 GPU results include up to 14% gains from a custom thermal solution. It's one example of innovations beyond standard air cooling that systems builders are applying to their NVIDIA MGX designs to take the performance of Hopper GPUs to new heights.



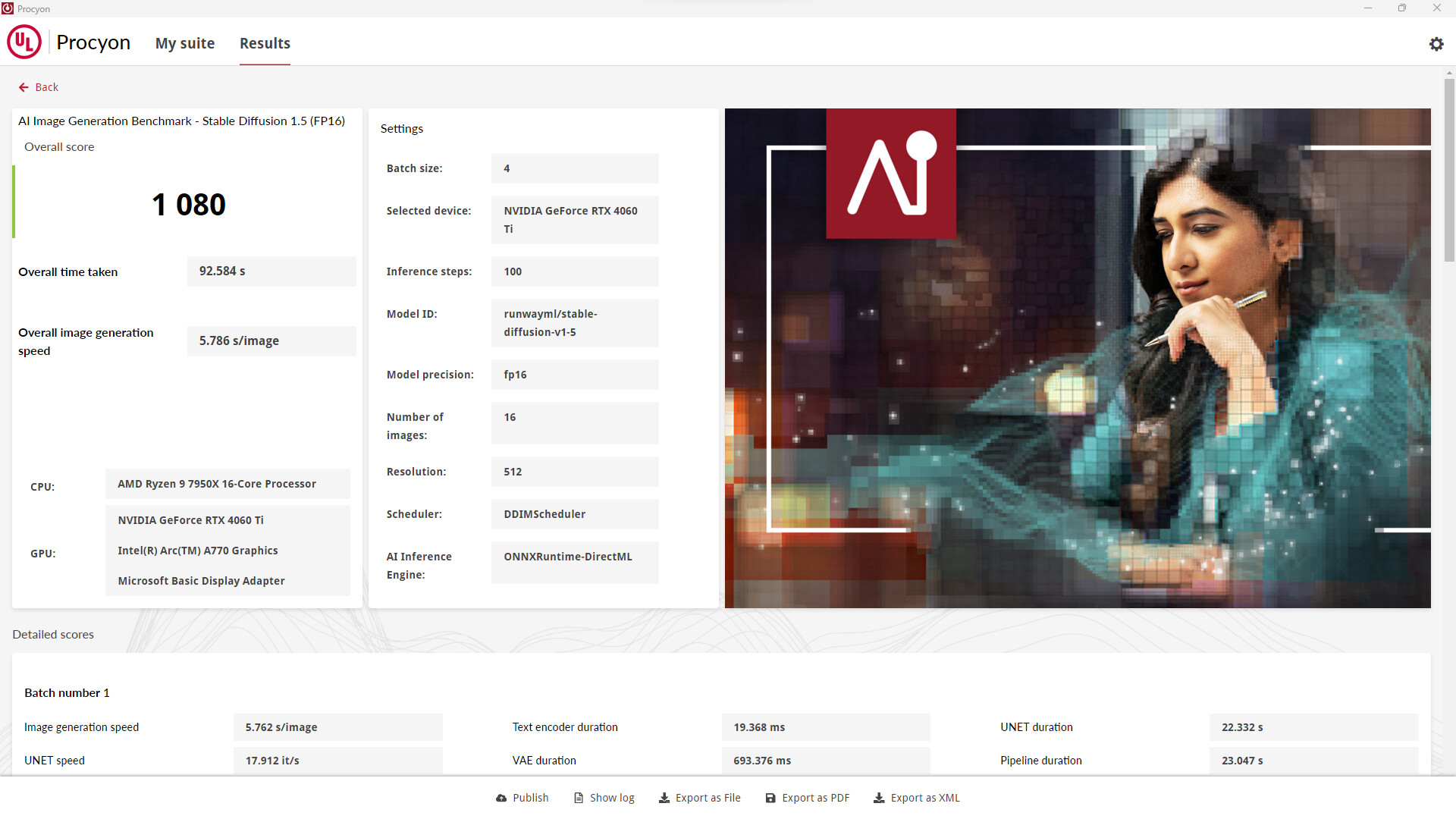
UL Announces the Procyon AI Image Generation Benchmark Based on Stable Diffusion
We're excited to announce we're expanding our AI Inference benchmark offerings with the UL Procyon AI Image Generation Benchmark, coming Monday, 25th March. AI has the potential to be one of the most significant new technologies hitting the mainstream this decade, and many industry leaders are competing to deliver the best AI Inference performance through their hardware. Last year, we launched the first of our Procyon AI Inference Benchmarks for Windows, which measured AI Inference performance with a workload using Computer Vision.
The upcoming UL Procyon AI Image Generation Benchmark provides a consistent, accurate and understandable workload for measuring the AI performance of high-end hardware, built with input from members of the industry to ensure fair and comparable results across all supported hardware.

The upcoming UL Procyon AI Image Generation Benchmark provides a consistent, accurate and understandable workload for measuring the AI performance of high-end hardware, built with input from members of the industry to ensure fair and comparable results across all supported hardware.
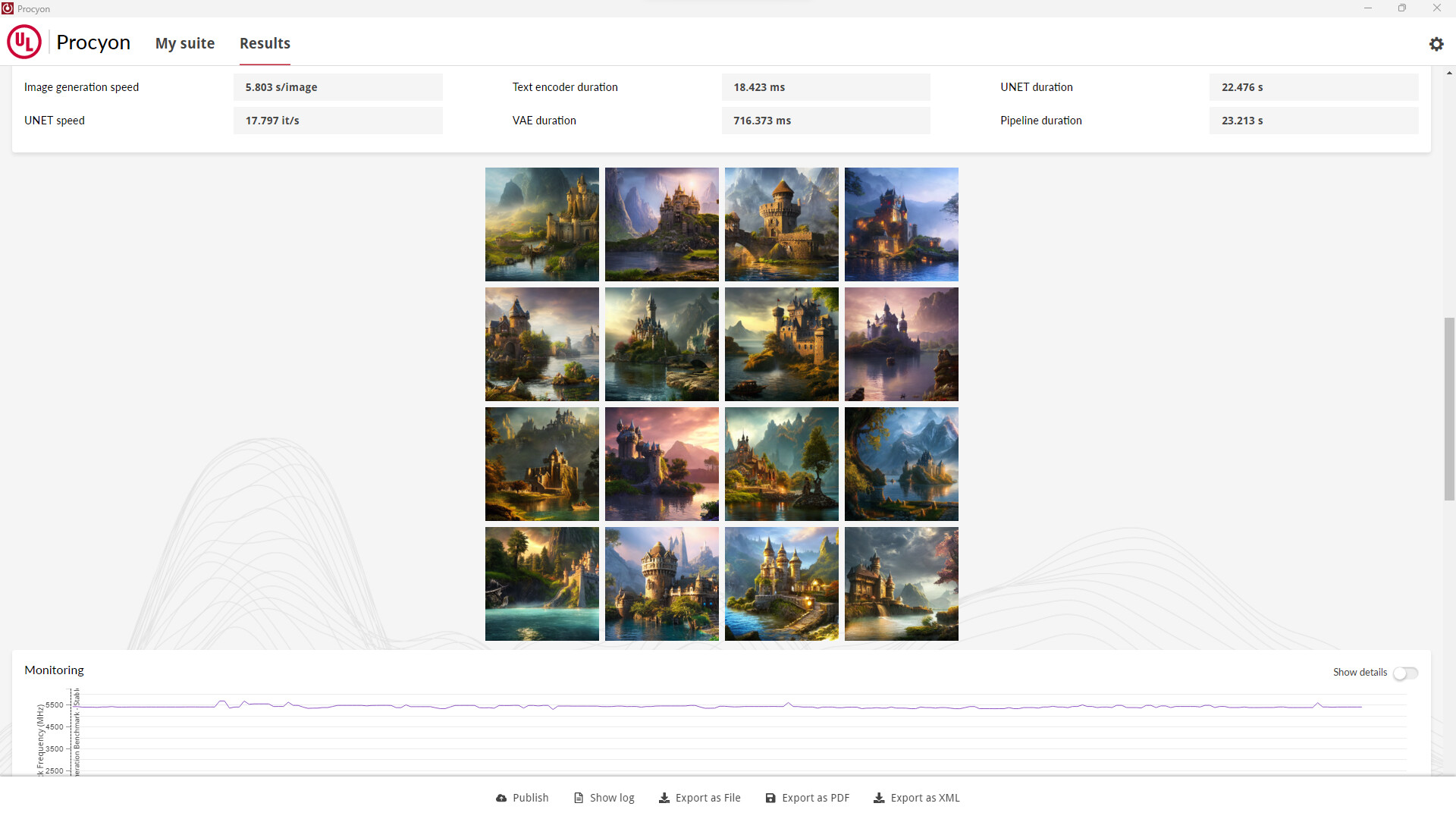
Intel Gaudi2 Accelerator Beats NVIDIA H100 at Stable Diffusion 3 by 55%
Stability AI, the developers behind the popular Stable Diffusion generative AI model, have run some first-party performance benchmarks for Stable Diffusion 3 using popular data-center AI GPUs, including the NVIDIA H100 "Hopper" 80 GB, A100 "Ampere" 80 GB, and Intel's Gaudi2 96 GB accelerator. Unlike the H100, which is a super-scalar CUDA+Tensor core GPU; the Gaudi2 is purpose-built to accelerate generative AI and LLMs. Stability AI published its performance findings in a blog post, which reveals that the Intel Gaudi2 96 GB is posting a roughly 56% higher performance than the H100 80 GB.
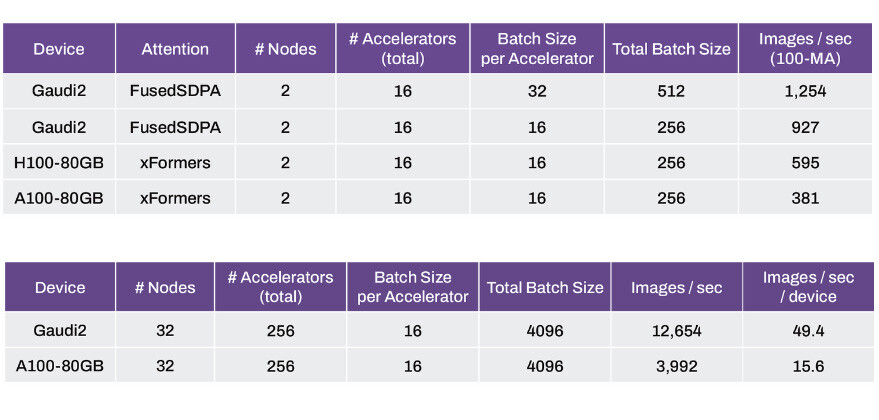
With 2 nodes, 16 accelerators, and a constant batch size of 16 per accelerator (256 in all), the Intel Gaudi2 array is able to generate 927 images per second, compared to 595 images for the H100 array, and 381 images per second for the A100 array, keeping accelerator and node counts constant. Scaling things up a notch to 32 nodes, and 256 accelerators or a batch size of 16 per accelerator (total batch size of 4,096), the Gaudi2 array is posting 12,654 images per second; or 49.4 images per-second per-device; compared to 3,992 images per second or 15.6 images per-second per-device for the older-gen A100 "Ampere" array.

With 2 nodes, 16 accelerators, and a constant batch size of 16 per accelerator (256 in all), the Intel Gaudi2 array is able to generate 927 images per second, compared to 595 images for the H100 array, and 381 images per second for the A100 array, keeping accelerator and node counts constant. Scaling things up a notch to 32 nodes, and 256 accelerators or a batch size of 16 per accelerator (total batch size of 4,096), the Gaudi2 array is posting 12,654 images per second; or 49.4 images per-second per-device; compared to 3,992 images per second or 15.6 images per-second per-device for the older-gen A100 "Ampere" array.


AMD Readying Feature-enriched ROCm 6.1
The latest version of AMD's open-source GPU compute stack, ROCm, is due for launch soon according to a Phoronix article—chief author, Michael Larabel, has been poring over Team Red's public GitHub repositories over the past couple of days. AMD ROCm version 6.0 was released last December—bringing official support for the AMD Instinct MI300A/MI300X, alongside PyTorch improvements, expanded AI libraries, and many other upgrades and optimizations. The v6.0 milestone placed Team Red in a more competitive position next to NVIDIA's very mature CUDA software layer. A mid-February 2024 update added support for Radeon PRO W7800 and RX 7900 GRE GPUs, as well as ONNX Runtime.
Larabel believes that "ROCm 6.1" is in for an imminent release, given his tracking of increased activity on publicly visible developer platforms: "For MIPOpen 3.1 with ROCm 6.1 there's been many additions including new solvers, an AI-based parameter prediction model for the conv_hip_igemm_group_fwd_xdlops solver, numerous fixes, and other updates. AMD MIGraphX will see an important update with ROCm 6.1. For the next ROCm release, MIGraphX 2.9 brings FP8 support, support for more operators, documentation examples for Whisper / Llama-2 / Stable Diffusion 2.1, new ONNX examples, BLAS auto-tuning for GEMMs, and initial code for MIGraphX running on Microsoft Windows." The change-logs/documentation updates also point to several HIPIFY for ROCm 6.1 improvements—including the addition of CUDA 12.3.2 support.


Larabel believes that "ROCm 6.1" is in for an imminent release, given his tracking of increased activity on publicly visible developer platforms: "For MIPOpen 3.1 with ROCm 6.1 there's been many additions including new solvers, an AI-based parameter prediction model for the conv_hip_igemm_group_fwd_xdlops solver, numerous fixes, and other updates. AMD MIGraphX will see an important update with ROCm 6.1. For the next ROCm release, MIGraphX 2.9 brings FP8 support, support for more operators, documentation examples for Whisper / Llama-2 / Stable Diffusion 2.1, new ONNX examples, BLAS auto-tuning for GEMMs, and initial code for MIGraphX running on Microsoft Windows." The change-logs/documentation updates also point to several HIPIFY for ROCm 6.1 improvements—including the addition of CUDA 12.3.2 support.



AMD Ryzen 7 8700G AI Performance Enhanced by Overclocked DDR5 Memory
We already know about AMD Ryzen 7 8700G APU's enjoyment of overclocked memory—early reviews demonstrated the graphical benefits granted by fiddling with "iGPU engine clock and the processor's memory frequency." While gamers can enjoy a boosted integrated graphics solution that is comparable in performance 1080p stakes to a discrete Radeon RX 6500 XT GPU, AI enthusiasts are eager to experiment with the "Hawk Point" pat's Radeon 780M IGP and Neural Processing Unit (NPU)—the first generation Ryzen XDNA inference engine can unleash up to 16 AI TOPs. One individual, chi11eddog, posted their findings through social media channels earlier today, coinciding with the official launch of Ryzen 8000G processors. The initial set of results concentrated on the Radeon 780M aspect; NPU-centric data may arrive at a later date.
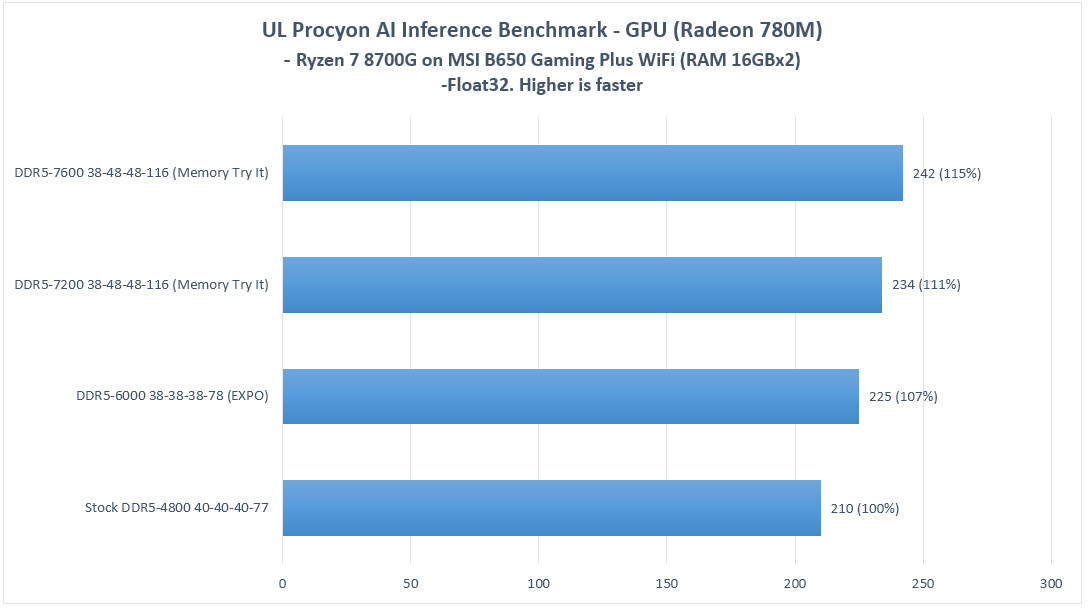
They performed quick tests on AMD's freshly released Ryzen 7 8700G desktop processor, combined with an MSI B650 Gaming Plus WiFi motherboard and two sticks of 16 GB DDR5-4800 memory. The MSI exclusive "Memory Try It" feature was deployed further up in the tables—this assisted in achieving and gauging several "higher system RAM frequency" settings. Here is chi11eddog's succinct interpretation of benchmark results: "7600 MT/s is 15% faster than 4800 MT/s in UL Procyon AI Inference Benchmark and 4% faster in GIMP with Stable Diffusion." The processor's default memory state is capable of producing 210 Float32 TOPs, according to chi11eddog's inference chart. The 6000 MT/s setting produces a 7% improvement over baseline, while 7200 MT/s drives proceedings to 11%—the flagship APU's Radeon 780M iGPU appears to be quite dependent on bandwidth. Their GIMP w/ Stable Diffusion benchmarks also taxed the integrated RDNA 3 graphics solution—again, it was deemed to be fairly bandwidth hungry.



They performed quick tests on AMD's freshly released Ryzen 7 8700G desktop processor, combined with an MSI B650 Gaming Plus WiFi motherboard and two sticks of 16 GB DDR5-4800 memory. The MSI exclusive "Memory Try It" feature was deployed further up in the tables—this assisted in achieving and gauging several "higher system RAM frequency" settings. Here is chi11eddog's succinct interpretation of benchmark results: "7600 MT/s is 15% faster than 4800 MT/s in UL Procyon AI Inference Benchmark and 4% faster in GIMP with Stable Diffusion." The processor's default memory state is capable of producing 210 Float32 TOPs, according to chi11eddog's inference chart. The 6000 MT/s setting produces a 7% improvement over baseline, while 7200 MT/s drives proceedings to 11%—the flagship APU's Radeon 780M iGPU appears to be quite dependent on bandwidth. Their GIMP w/ Stable Diffusion benchmarks also taxed the integrated RDNA 3 graphics solution—again, it was deemed to be fairly bandwidth hungry.



NVIDIA Announces up to 5x Faster TensorRT-LLM for Windows, and ChatGPT API-like Interface
Even as CPU vendors are working to mainstream accelerated AI for client PCs, and Microsoft setting the pace for more AI in everyday applications with Windows 11 23H2 Update; NVIDIA is out there reminding you that every GeForce RTX GPU is an AI accelerator. This is thanks to its Tensor cores, and the SIMD muscle of the ubiquitous CUDA cores. NVIDIA has been making these for over 5 years now, and has an install base of over 100 million. The company is hence focusing on bring generative AI acceleration to more client- and enthusiast relevant use-cases, such as large language models.
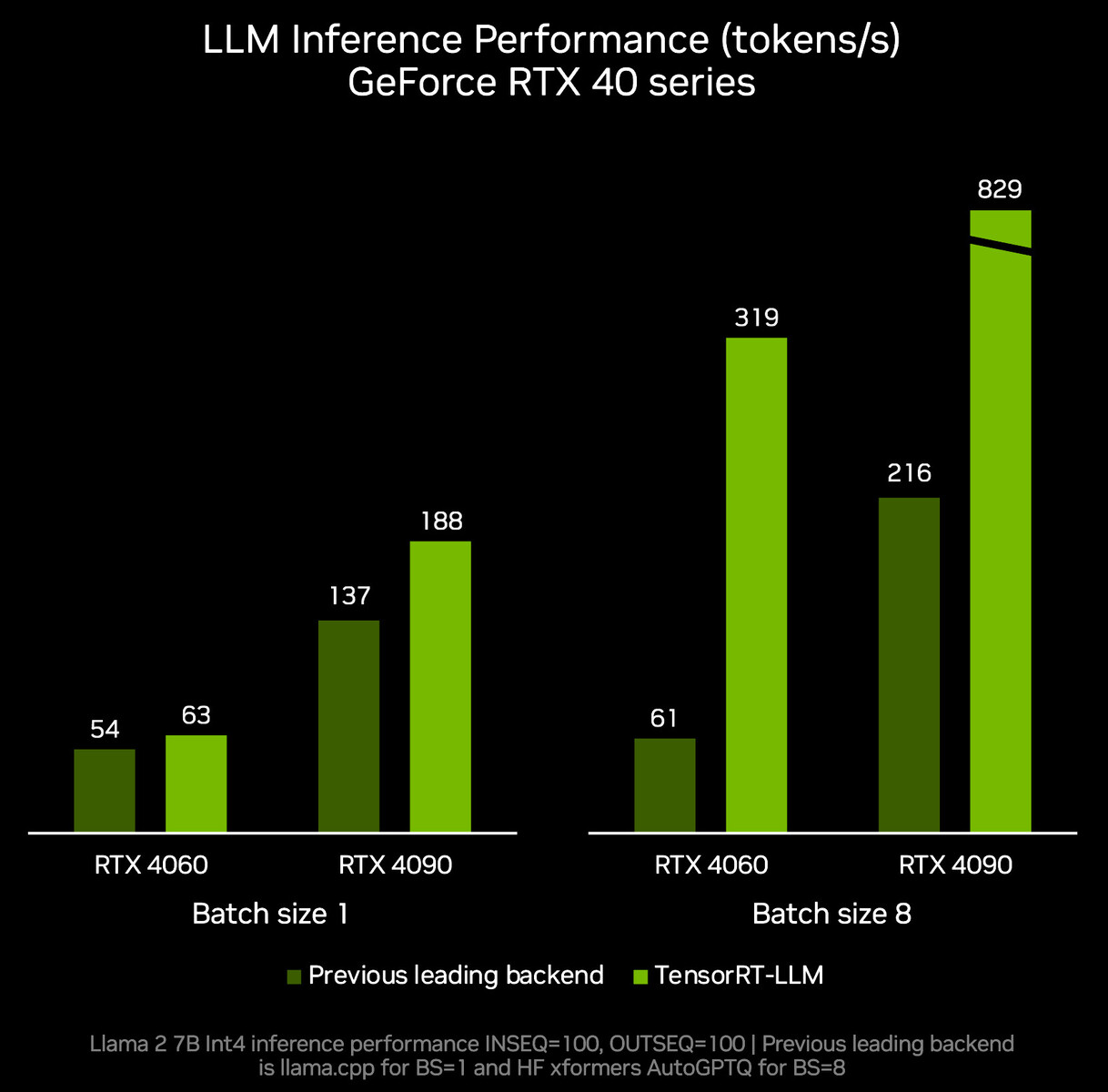
NVIDIA at the Microsoft Ignite event announced new optimizations, models, and resources to bring accelerated AI to everyone with an NVIDIA GPU that meets the hardware requirements. To begin with, the company introduced an update to TensorRT-LLM for Windows, a library that leverages NVIDIA RTX architecture for accelerating large language models (LLMs). The new TensorRT-LLM version 0.6.0 will release later this month, and improve LLM inference performance by up to 5 times in terms of tokens per second, when compared to the initial release of TensorRT-LLM from October 2023. In addition, TensorRT-LLM 0.6.0 will introduce support for popular LLMs, including Mistral 7B and Nemtron-3 8B. Accelerating these two will require a GeForce RTX 30-series "Ampere" or 40-series "Ada" GPU with at least 8 GB of main memory.

NVIDIA at the Microsoft Ignite event announced new optimizations, models, and resources to bring accelerated AI to everyone with an NVIDIA GPU that meets the hardware requirements. To begin with, the company introduced an update to TensorRT-LLM for Windows, a library that leverages NVIDIA RTX architecture for accelerating large language models (LLMs). The new TensorRT-LLM version 0.6.0 will release later this month, and improve LLM inference performance by up to 5 times in terms of tokens per second, when compared to the initial release of TensorRT-LLM from October 2023. In addition, TensorRT-LLM 0.6.0 will introduce support for popular LLMs, including Mistral 7B and Nemtron-3 8B. Accelerating these two will require a GeForce RTX 30-series "Ampere" or 40-series "Ada" GPU with at least 8 GB of main memory.
Apr 4th, 2025 23:47 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- XFX Radeon RX 580 8GB (1)
- New posts added to last post (10)
- need help choosing an upgrade (0)
- EK Quantum Velocity intel to amd conversion (10)
- I have an idea for cooling 1kW GPU power. (24)
- What's your latest tech purchase? (23477)
- Last game you purchased? (748)
- TechPowerUp Screenshot Thread (MASSIVE 56K WARNING) (4267)
- What are you playing? (23342)
- [Intel AX1xx/AX2xx/AX4xx/AX16xx/BE2xx/BE17xx] Intel Modded Wi-Fi Driver with Intel® Killer™ Features (302)
Popular Reviews
- DDR5 CUDIMM Explained & Benched - The New Memory Standard
- PowerColor Radeon RX 9070 Hellhound Review
- Corsair RM750x Shift 750 W Review
- ASUS Prime X870-P Wi-Fi Review
- Sapphire Radeon RX 9070 XT Pulse Review
- Pwnage Trinity CF Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Palit GeForce RTX 5070 GamingPro OC Review
Controversial News Posts
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (97)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (90)
- Retailers Anticipate Increased Radeon RX 9070 Series Prices, After Initial Shipments of "MSRP" Models (90)