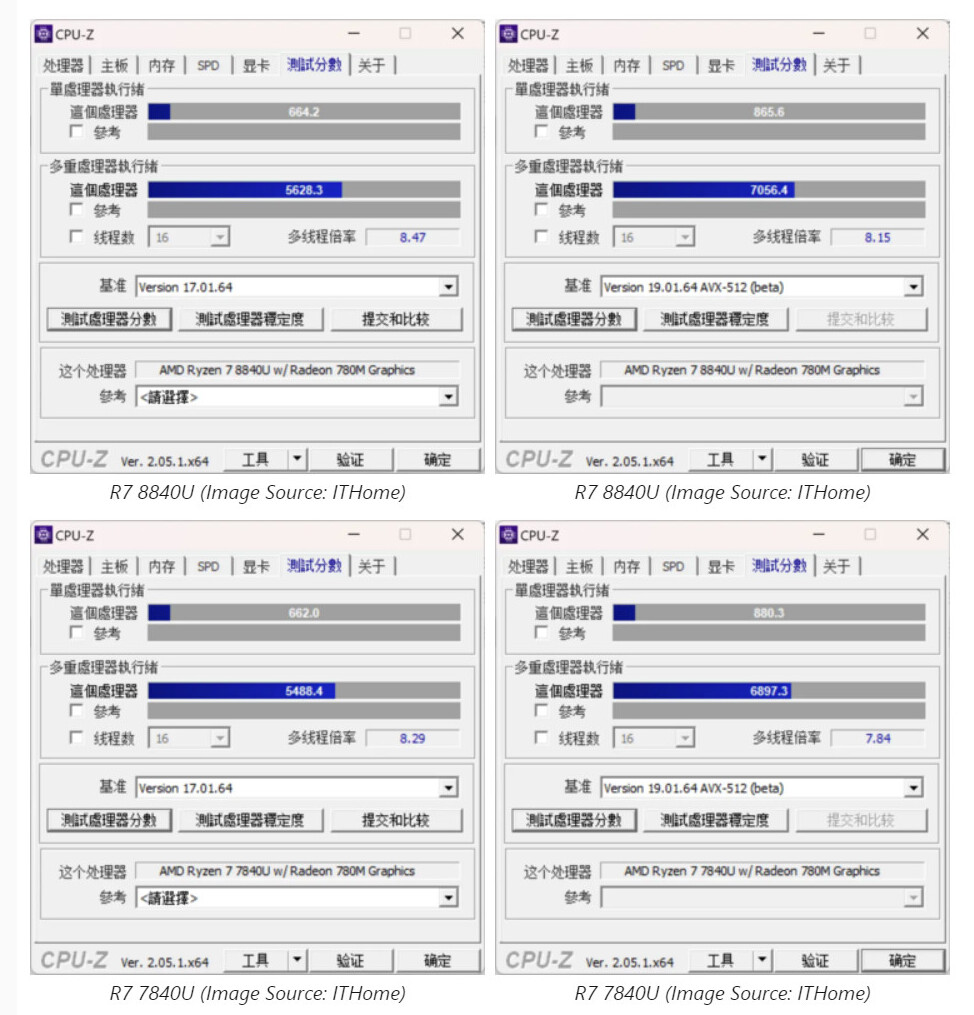
Financial Analyst Outs AMD Instinct MI300X "Projected" Pricing
AMD's December 2023 launch of new Instinct series accelerators has generated a lot of tech news buzz and excitement within the financial world, but not many folks are privy to Team Red's MSRP for the CDNA 3.0 powered MI300X and MI300A models. A Citi report has pulled back the curtain, albeit with "projected" figures—an inside source claims that Microsoft has purchased the Instinct MI300X 192 GB model for ~$10,000 a piece. North American enterprise customers appear to have taken delivery of the latest MI300 products around mid-January time—inevitably, top secret information has leaked out to news investigators. SeekingAlpha's article (based on Citi's findings) alleges that the Microsoft data center division is AMD's top buyer of MI300X hardware—GPT-4 is reportedly up and running on these brand new accelerators.
The leakers claim that businesses further down the (AI and HPC) food chain are having to shell out $15,000 per MI300X unit, but this is a bargain when compared to NVIDIA's closest competing package—the venerable H100 SXM5 80 GB professional card. Team Green, similarly, does not reveal its enterprise pricing to the wider public—Tom's Hardware has kept tabs on H100 insider info and market leaks: "over the recent quarters, we have seen NVIDIA's H100 80 GB HBM2E add-in-card available for $30,000, $40,000, and even much more at eBay. Meanwhile, the more powerful H100 80 GB SXM with 80 GB of HBM3 memory tends to cost more than an H100 80 GB AIB." Citi's projection has Team Green charging up to four times more for its H100 product, when compared to Team Red MI300X pricing. NVIDIA's dominant AI GPU market position could be challenged by cheaper yet still very performant alternatives—additionally chip shortages have caused Jensen & Co. to step outside their comfort zone. Tom's Hardware reached out to AMD for comment on the Citi pricing claims—a company representative declined this invitation.


The leakers claim that businesses further down the (AI and HPC) food chain are having to shell out $15,000 per MI300X unit, but this is a bargain when compared to NVIDIA's closest competing package—the venerable H100 SXM5 80 GB professional card. Team Green, similarly, does not reveal its enterprise pricing to the wider public—Tom's Hardware has kept tabs on H100 insider info and market leaks: "over the recent quarters, we have seen NVIDIA's H100 80 GB HBM2E add-in-card available for $30,000, $40,000, and even much more at eBay. Meanwhile, the more powerful H100 80 GB SXM with 80 GB of HBM3 memory tends to cost more than an H100 80 GB AIB." Citi's projection has Team Green charging up to four times more for its H100 product, when compared to Team Red MI300X pricing. NVIDIA's dominant AI GPU market position could be challenged by cheaper yet still very performant alternatives—additionally chip shortages have caused Jensen & Co. to step outside their comfort zone. Tom's Hardware reached out to AMD for comment on the Citi pricing claims—a company representative declined this invitation.