Global Top 10 IC Design Houses See 49% YoY Growth in 2024, NVIDIA Commands Half the Market
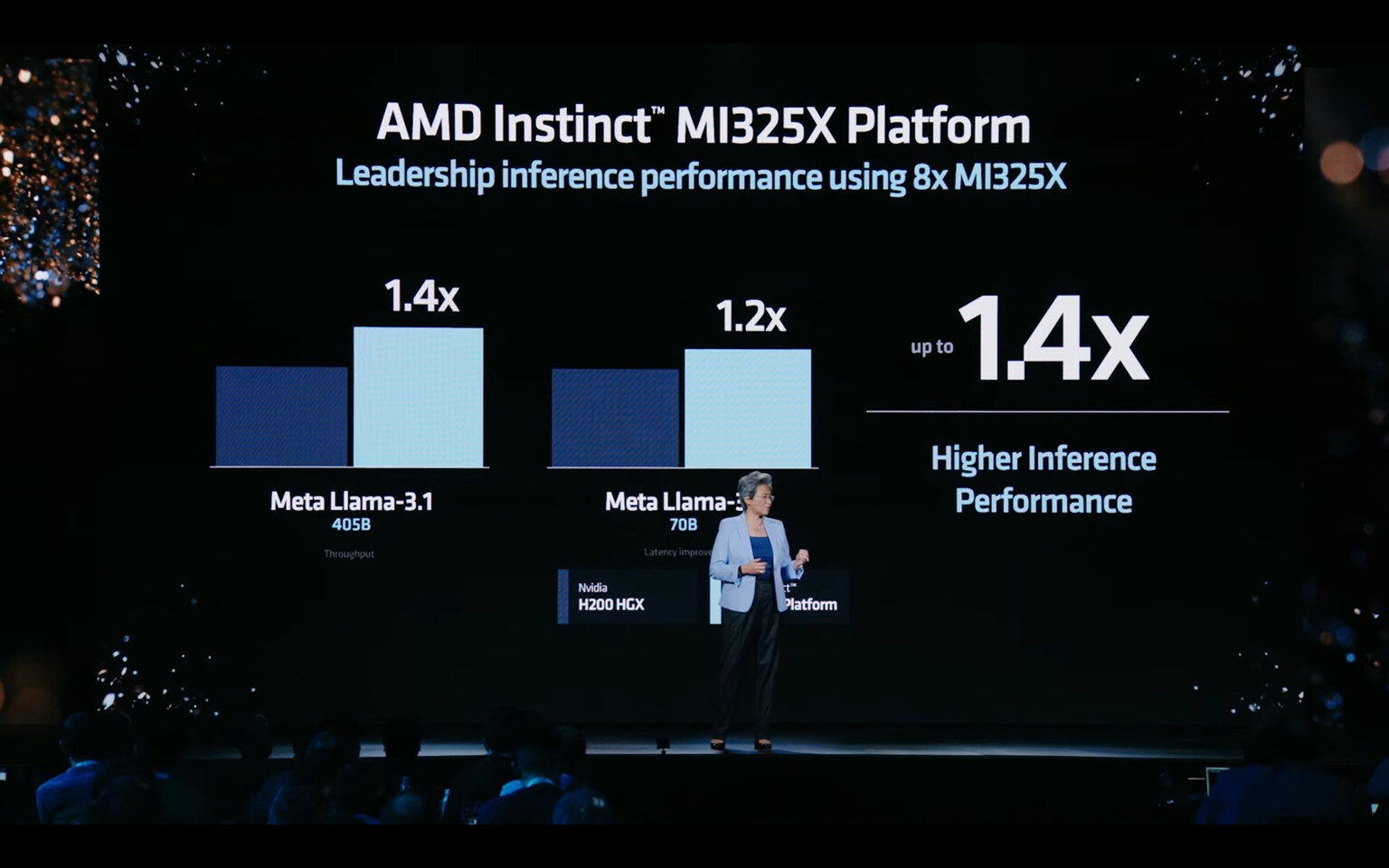
TrendForce reveals that the combined revenue of the world's top 10 IC design houses reached approximately US$249.8 billion in 2024, marking a 49% YoY increase. The booming AI industry has fueled growth across the semiconductor sector, with NVIDIA leading the charge, posting an astonishing 125% revenue growth, widening its lead over competitors, and solidifying its dominance in the IC industry.
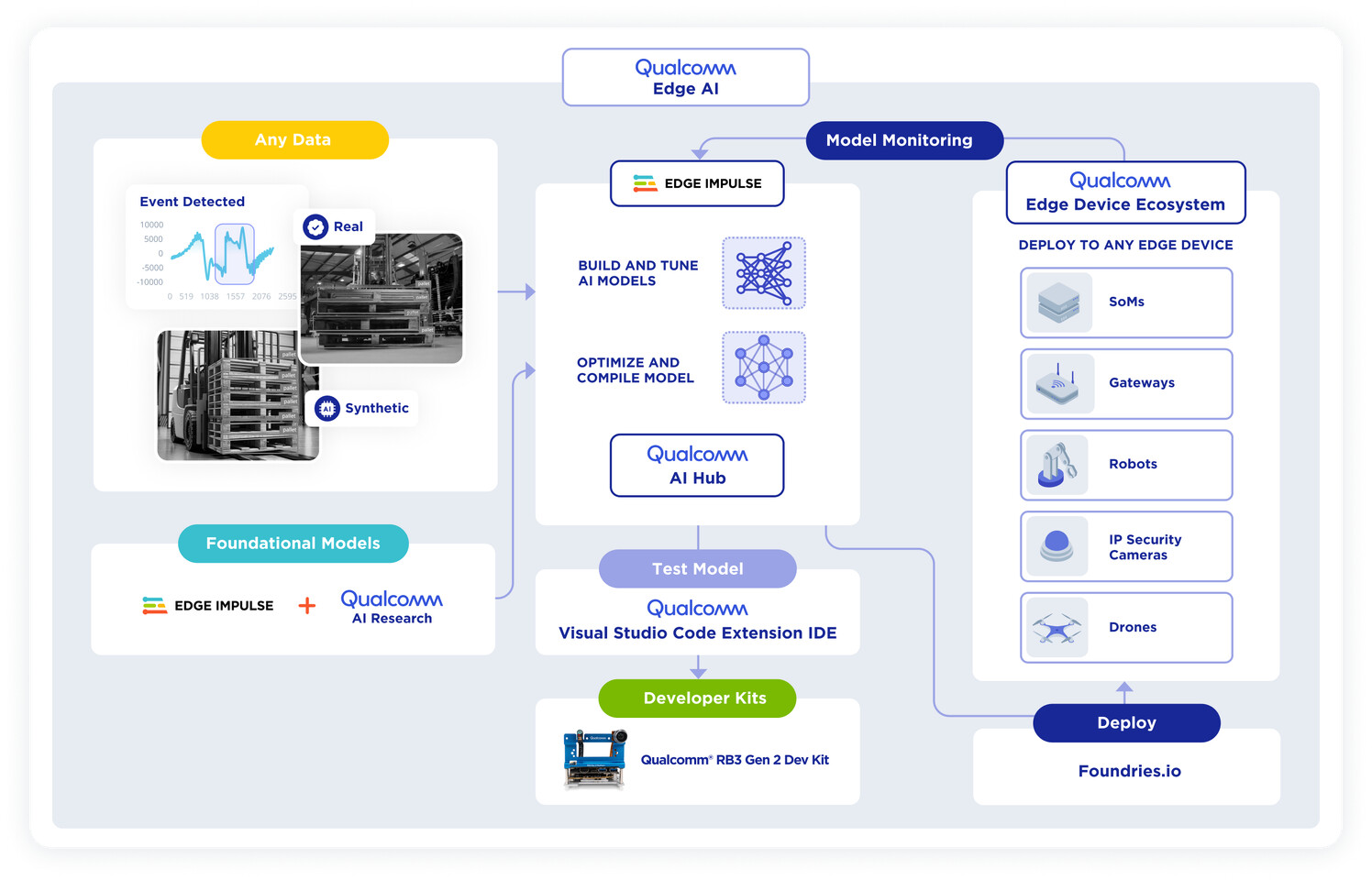
Looking ahead to 2025, advancements in semiconductor manufacturing will further enhance AI computing power, with LLMs continuing to emerge. Open-source models like DeepSeek could lower AI adoption costs, accelerating AI penetration from servers to personal devices. This shift positions edge AI devices as the next major growth driver for the semiconductor industry.
Looking ahead to 2025, advancements in semiconductor manufacturing will further enhance AI computing power, with LLMs continuing to emerge. Open-source models like DeepSeek could lower AI adoption costs, accelerating AI penetration from servers to personal devices. This shift positions edge AI devices as the next major growth driver for the semiconductor industry.