 115
115
Intel Lunar Lake Technical Deep Dive - So many Revolutions in One Chip
The CPU Cores: Part 2 »The CPU Cores


Intel Core Ultra 200V isn't a direct successor to the entire Core Ultra 100 Meteor Lake family, but rather a new class of processors meant for thin-and-light notebooks—the same class that is powered by the Apple M3 or the Qualcomm Snapdragon Elite X. Given this, Intel has a very specific set of performance targets for its CPU, graphics, and AI acceleration performance, with the key driver being competitiveness in performance/Watt to the Apple and Qualcomm chips.
The Lunar Lake-MX CPU complex has a total of 8 CPU cores, four of these are the new Lion Cove performance cores (P-cores), and the other four are Skymont efficiency cores (E-cores). Unlike in Meteor Lake, or indeed all past generations of Intel hybrid processors, the P-cores and E-cores do not share an L3 cache or sit on a ringbus fabric. They do share the same die, and are part of the die's internal high-bandwidth fabric.

The four P-cores are part of a small ringbus network, with ring-stops along the four P-cores, and segments of a 12 MB L3 cache that's shared among the four. The E-core cluster, on the other hand, is an "island," much like the low-power island cores of Meteor Lake. The cluster's 4 MB L2 cache serves as the last-level cache for the four Skymont E-cores. Processing threads migrate between the P-core ring and the E-core island cluster seamlessly. Intel has made several improvements to Thread Director, which we'll get to in a bit.
Lion Cove P-core

The Core Ultra 200V Lion Cove-MX processor has four Lion Cove P-cores that share a 12 MB L3 cache. Intel designed the Lion Cove core for the highest possible performance and ISA compatibility, without sacrificing efficiency. The big story here is that Intel has not given Lion Cove Hyper-Threading technology (HTT).

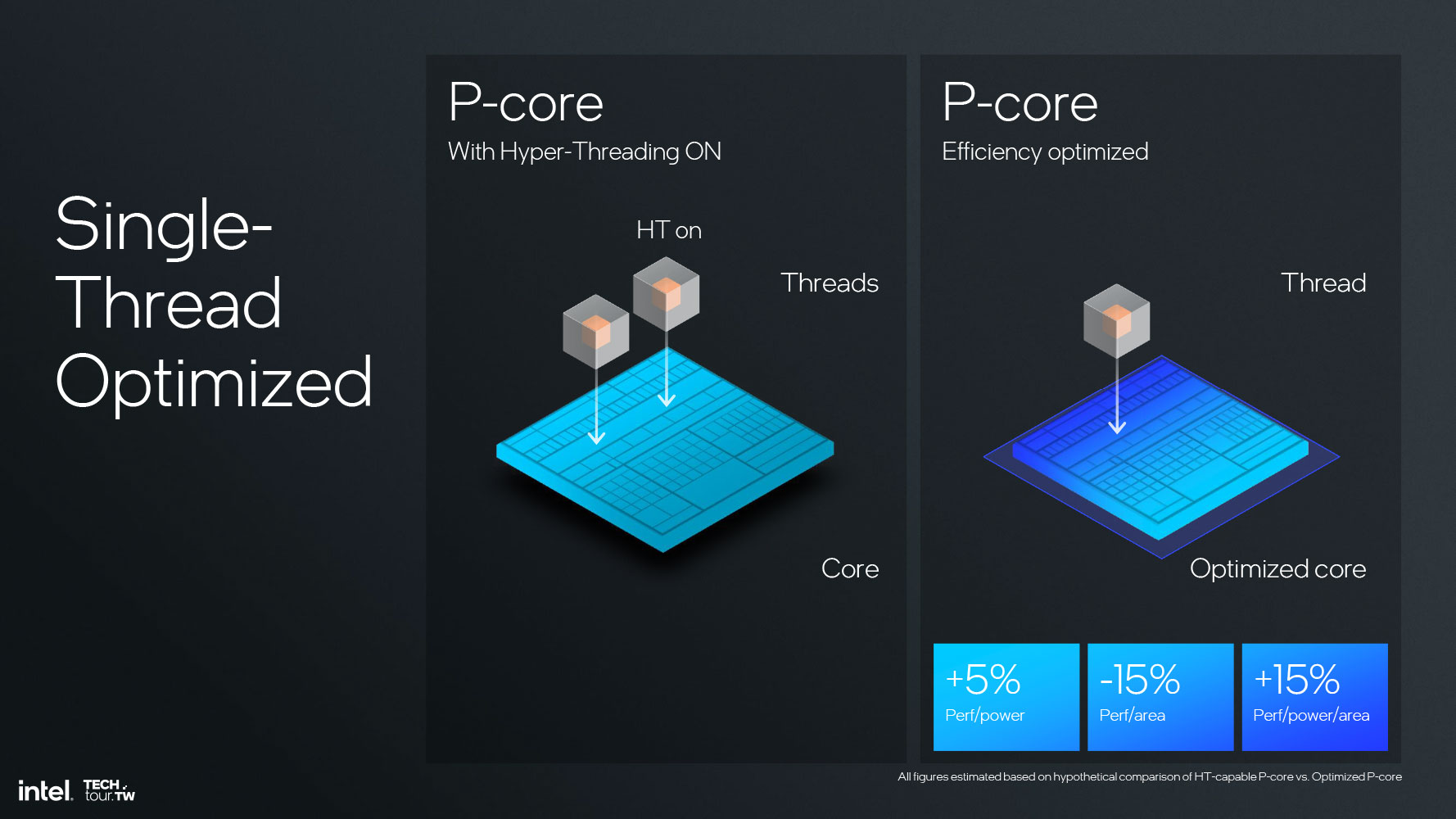
While it is true that HTT is a great way to put the idle hardware resources of the core to use by executing a second thread in parallel, at the hardware level, this means adding hardware to track and point the second thread for its journey through the core. These are physical components, which take up die-area and stay on whether you have HTT enabled or not. Intel has physically removed the components needed for HTT to work, and says that the savings in power and die-area could be traded for more clock speeds and IPC in the core, playing a key role in bringing Lunar Lake to the desired performance/watt targets. With HTT and related hardware removed, on a given node, Lion Cove yields a 15% die-area saving, with a 5% performance/power gain; and a 15% performance/power/area gain.
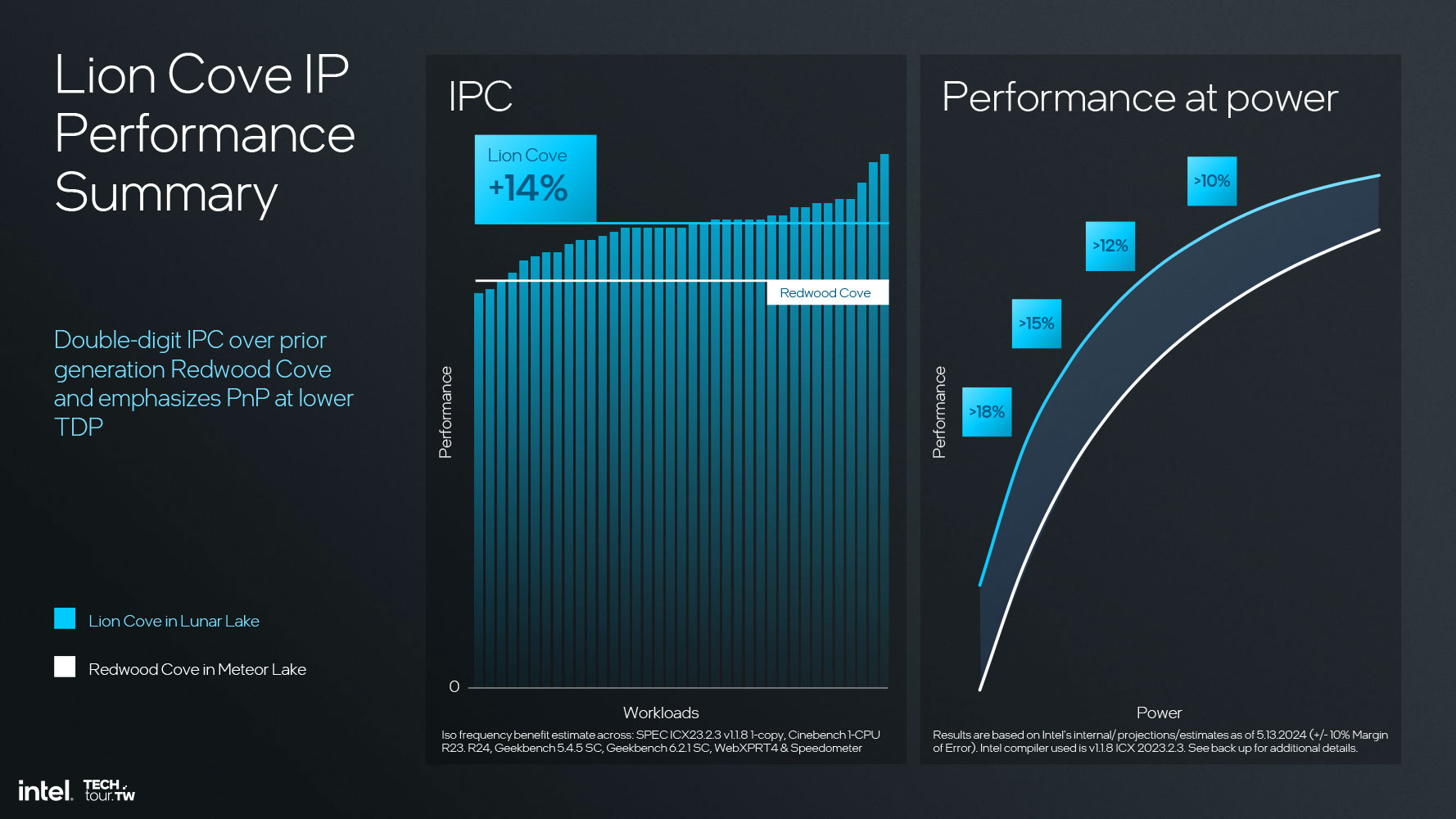
Intel is claiming a significant 14% IPC gain for Lion Cove over the previous generation Redwood Cove P-core powering the Meteor Lake processor. It also references an iso-power performance band that can be over 18% in some cases.


Intel has also overhauled the core-level power management system with two new features, an AI-driven self-tuning controller that reduces power and clocks with greater aptitude, and a much finer 16.67 MHz granularity in the clock speed itself, compared to the 100 MHz multiplier-based granularity previous generations of P-cores had.



Having gained both die-area and power headroom by deprecating HTT, Intel moved on to overhauling the microarchitecture itself. There are improvements to all key components, including a redesigned front-end, with an 8 times larger branch prediction block. The fetch unit and decode bandwidth has been increased. The micro-op cache has increased in capacity, and Intel has introduced the concept of "nano-ops," which are groups of similar broken down micro-operation tasks that can be executed in tandem.


The Integer and Vector domains, which form the out-of-order execution engine, has now split with individual access to the micro-op queue, with independent schedulers. The out-of-order engine sees the allocation rename/move elimination queue to now be 8-wide compared to 6-wide on Redwood Cove. The retirement queue is broadened 50% to 12-wide from 8-wide. The instruction window depth has increased from 512 to 576. Execution ports have gone up from 12 to 18.


The Integer ALUs have increased in number from 5 to 6, with 3 jump units instead of 2, 3 shift units instead of 2, and three MUL units instead of 1. The vector execution engine sees 4 SIMD ALUs instead of 3, two FMA units @ 4 cycle, and 2 divider units. The load-store subsystem sees 128 DTLB size, up from 96, and 3 STE address generators instead of 2.

Intel has also redone the core-level cache subsystem, with the introduction of an intermediate data cache between the 48 KB L1 and L2. The L1D cache is now referred to as the L0 D-cache, which retires to a 192 KB L1 D-cache. This talks to the L2 cache. On Lunar Lake the Lion Cove core gets 2.5 MB (or precisely 2,560 KB) of L2 cache. On Arrow Lake, this core gets 3 MB (3,072 KB) of L2 dedicated L2 cache. The four P-cores on the Lunar Lake silicon share a 12 MB L3 cache.
The real star of Lunar Lake is actually its E-core, and we'll talk more about it in the next page.
Jun 30th, 2025 21:44 CDT
change timezone
Latest GPU Drivers
New Forum Posts
- GPU PerfCap Reason PWR (8)
- Post your Cinebench 2024 score (657)
- Laptop overclocking adventures (1238)
- [INTEL]-How To Update Your Microcode for Intel HX 13/14th Gen. CPUs Laptops/Mobile Easily. (172)
- Will you buy a RTX 5090? (584)
- The TPU UK Clubhouse (26530)
- Optane and "enable write caching " (27)
- Question about Intel Optane SSDs (87)
- Do you use Linux? (664)
- Remember Fermi? Well here's my EVGA GTX 480 that I picked up for just 19 Euros! (9)
Popular Reviews
- ASUS ROG Crosshair X870E Extreme Review
- Sapphire Radeon RX 9060 XT Pulse OC 16 GB Review - Samsung Memory Tested
- AVerMedia CamStream 4K Review
- Lexar NQ780 4 TB Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Upcoming Hardware Launches 2025 (Updated May 2025)
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- AMD Ryzen 9 9950X3D Review - Great for Gaming and Productivity
- NVIDIA GeForce RTX 5060 8 GB Review
- ASRock Phantom Gaming Z890 Riptide Wi-Fi Review
TPU on YouTube
Controversial News Posts
- Intel's Core Ultra 7 265K and 265KF CPUs Dip Below $250 (288)
- NVIDIA Grabs Market Share, AMD Loses Ground, and Intel Disappears in Latest dGPU Update (204)
- Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming (140)
- NVIDIA Launches GeForce RTX 5050 for Desktops and Laptops, Starts at $249 (105)
- Microsoft Partners with AMD for Next-gen Xbox Hardware (105)
- Intel "Nova Lake‑S" Series: Seven SKUs, Up to 52 Cores and 150 W TDP (100)
- NVIDIA GeForce RTX 5080 SUPER Could Feature 24 GB Memory, Increased Power Limits (94)
- Reviewers Bemused by Restrictive Sampling of RX 9060 XT 8 GB Cards (88)