 35
35
Sparkle Arc A580 Orc Review
Pictures & Teardown »Architecture


Intel Xe-HPG "Alchemist" graphics architecture sees its biggest implementation to date with the ACM-G10 silicon powering the A770, A750, and the new A580. Built on the 6 nm process at TSMC, the ACM-G10 measures 406 mm² in die-area, and packs 21.7 billion transistors. Much like NVIDIA and AMD, Intel has innovated its own hierarchy for the number-crunching machinery of its GPUs, and differentiates SKUs by changing the number of indivisible groups of these to meet performance targets. The ACM-G10 silicon features a PCI-Express 4.0 x16 host interface, a 256-bit wide GDDR6 memory interface, the Xe Media Engine and Xe Display Engine, among a global dispatch processor, and memory fabric that's cushioned by L2 cache. The main SIMD component top-level organization is the Render Slice. Each of these is a self-contained unit with all the number-crunching and raster graphics hardware a GPU needs.


The ACM-G10 features eight such Render Slices. Each of these features four blocks of indivisible processing machinery, called Xe Cores; four Ray Tracing Units (RT units), and DirectX 12 Ultimate optimized raster-graphics units that includes four Samplers, Tessellation geometry processors, 16 ROPs, and 32 TMUs. Since there are 8 Render Slices, the silicon physically has 16 RT units, 128 ROPs, and 256 TMUs.


The Xe Core is the indivisible computation core, with sixteen 256-bit Vector Engines (execution units), sixteen 1024-bit XMX Matrix Engines, and 192 KB of L1 cache. Each Vector Engine has eight each of FP and INT units, besides a register file. Two adjacent Vector Engines share a Thread Control unit to share execution waves. There are 16 VEs per Xe Core, 4 Xe Cores per Render Slice, and 8 Render Slices on the ACM-G10 silicon, so we have 512 execution units in all, each with 8 FP/INT execution stages, which logically work out to 4,096 unified shaders. The A580 is carved out of this silicon by leaving the memory sub-system untouched, but enabling just 24 out of 32 Xe cores, by disabling two Render Slices. This results in 384 execution units, or 3,072 unified shaders, 384 XMX cores for AI acceleration, 24 Ray Tracing Engines, 192 TMUs, and 96 ROPs.


The XMX Matrix Engine is an extremely capable matrix-multiplication fixed-function hardware that can accelerate AI deep-learning neural net building and training. It's also a highly capable math accelerator. Intel originally designed this technology for the Xe-HP AI processors, but it finds client applications in Arc Graphics, where it is leveraged for ray tracing denoising and to accelerate features such as XeSS. There are 16 XMX units per Xe Core, and 64 per Render Slice, 512 across the ACM-G10 silicon. Each XMX unit can handle 128 FP16 or BF16 operations per clock; up to 256 INT8 ops/clock, and 512 INT4 ops/clock. The XMX-optimized native XeSS code is an order of magnitude faster than the industry-standard DP4a codepath of XeSS, as you'll see in our testing.


When it comes to real time ray tracing, Intel's Xe-HPG architecture has technological-parity with NVIDIA RTX, due to its heavy reliance on fixed-function hardware for ray intersection, BVH, and AI-based denoising.


There are several optimizations that further reduce the burden of ray tracing operations on the main SIMD machinery, such as shader execution reordering which optimizes shader work threads for streamlined execution among the SIMD units. NVIDIA is only now implementing such a feature, with its GeForce "Ada" architecture. There's a special component in each Xe Core that reorders shader threads. It's essentially a very intelligent dispatch unit. Intel refers to its ray tracing architecture as Asynchronous.
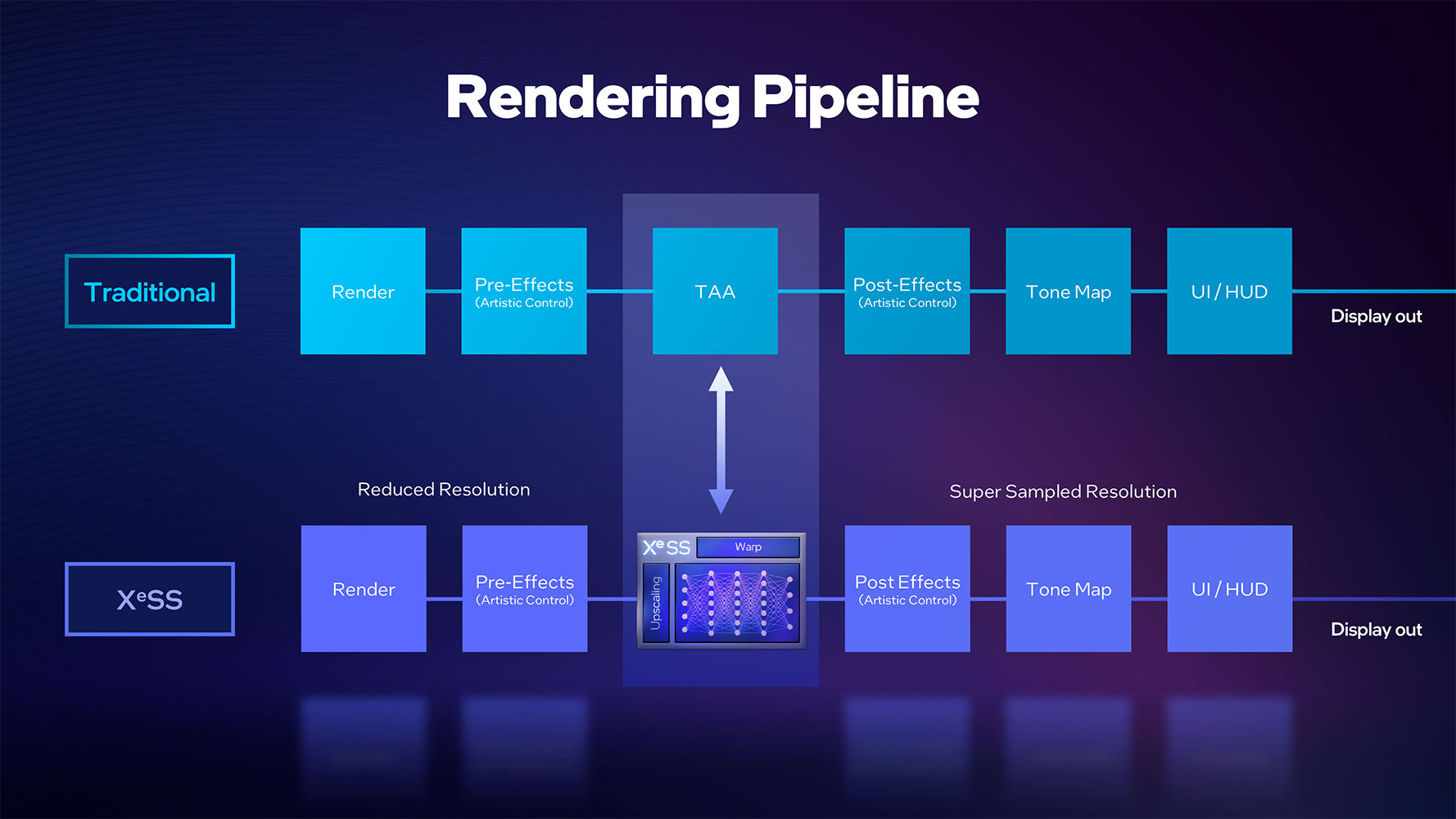
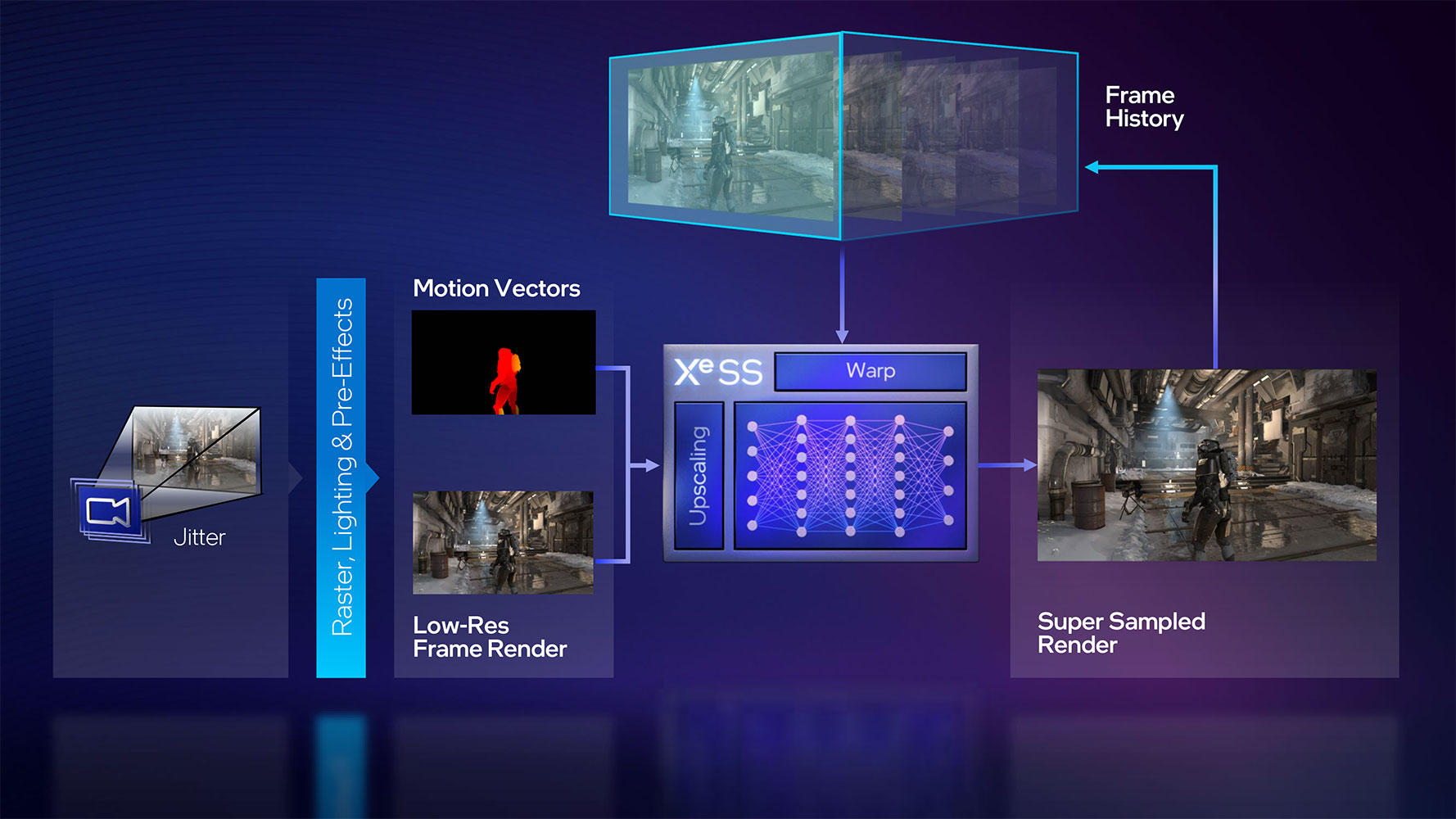
With Moore's Law tapering despite Intel claiming otherwise, the writing is on the wall—rendering at native resolution is over, at least in the performance and mainstream GPU segments. High-quality super resolution features such as DLSS and FSR are helping NVIDIA and AMD shore up performance at minimal quality loss, by rendering games at lower resolutions than native to the display; and upscaling them intelligently, with minimal quality losses. Intel's take is XeSS. The company claims that this is a 2nd generation super-res technology, on par with DLSS 2 and FSR 2.0. The XeSS upscaling tech is as easily integrated with a game engine's rendering pipeline as TAA (or AMD FSR). The XeSS algorithm is executed as XMX-optimized AI on Arc GPUs, and as DP4a-compatible code on other GPU brands. The algorithm takes into account low-resolution frame data, motion vectors, and temporal data from previously output high-res frames to reconstruct details, before passing on the high-res output to the game engine for post-processing and UI/HUD.


The Xe Display Engine is capable of up to two display outputs at 8K 60 Hz + HDR; up to four outputs at 4K 120 Hz + HDR, and up to four 1440p or 1080p with 360 Hz + HDR. VESA Adaptive Sync and Intel Smooth Sync features are supported. The latter is a feature that runs the GPU at its native frame-rate, while attempting to remove the screen-tearing from the display output. A typical Arc desktop graphics card has two each of DisplayPort 2.0 and HDMI 2.0b connections. The Xe Media Engine provides hardware-accelerated decoding and encoding of AV1, and accelerated decoding of H.265 HEVC, and H.264 AVC.


Besides VESA Adaptive Sync, the Xe Display Engine offers a software feature called Smooth Sync. This gives fixed refresh-rate monitors the ability to play games without V-Sync, rendering them at the highest possible FPS (and the least input latency), while attempting to eliminate the screen-tearing using a shader-based dithering filter pass. This is an extremely simply way to solve this problem, and we're surprised AMD and NVIDIA haven't tried it.
Apr 8th, 2025 01:58 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Kindly help in Identifying GPU and Suitable bios (9)
- AMD RX 9070 XT & RX 9070 non-XT thread (OC, undervolt, benchmarks, ...) (84)
- 12v lines 0 reads occansionally (3)
- Asus X670E Crosshair Crashes (7)
- 9070XT or 7900XT or 7900XTX (122)
- USB case with dual USB-C and dual USB-A (7)
- The coffee and tea drinkers club. (247)
- The easiest way to connect the BOOTSEL test metal terminal and the GND terminal.... (1)
- Anyone with true HDDs still around here? (337)
- is it worth using ssd with usb2? (12)
Popular Reviews
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- UPERFECT UStation Delta Max Review - Two Screens In One
- ASUS Prime X870-P Wi-Fi Review
- PowerColor Radeon RX 9070 Hellhound Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- MCHOSE L7 Pro Review
- Sapphire Radeon RX 9070 XT Pulse Review
- Corsair RM750x Shift 750 W Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- DDR5 CUDIMM Explained & Benched - The New Memory Standard
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (161)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (97)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (92)