NVIDIA Launches A100 PCIe-Based Accelerator with 80 GB HBM2E Memory
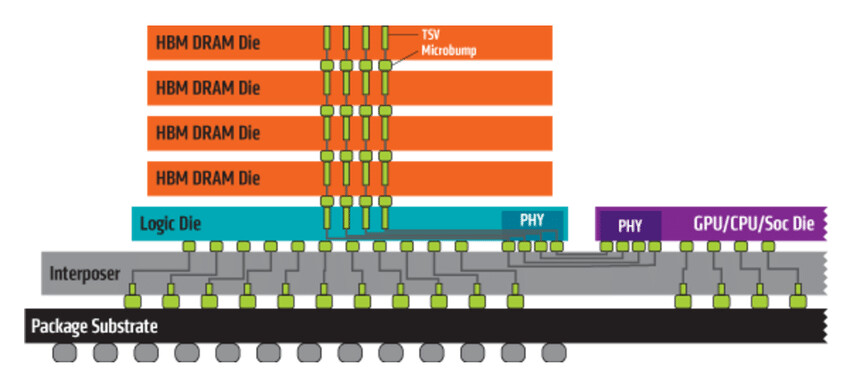
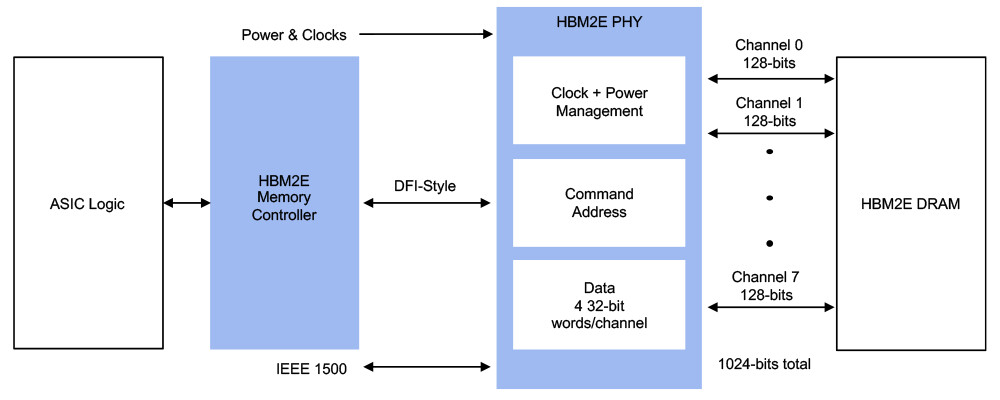
During this year's ISC 2021 event, as a part of the company's exhibition portfolio, NVIDIA has decided to launch an updated version of the A100 accelerator. A couple of months ago, in November, NVIDIA launched an 80 GB HBM2E version of the A100 accelerator, on the SXM2 proprietary form-factor. Today, we are getting the same upgraded GPU in the more standard dual-slot PCIe type of card. Featuring a GA100 GPU built on TSMC's 7 nm process, this SKU has 6192 CUDA cores present. To pair with the beefy amount of computing, the GPU needs appropriate memory. This time, there is as much as 80 GB of HBM2E memory. The memory achieves a bandwidth of 2039 GB/s, with memory dies running at an effective speed of 3186 Gbps. An important note is that the TDP of the GPU has been lowered to 250 Watts, compared to the 400 Watt SXM2 solution.
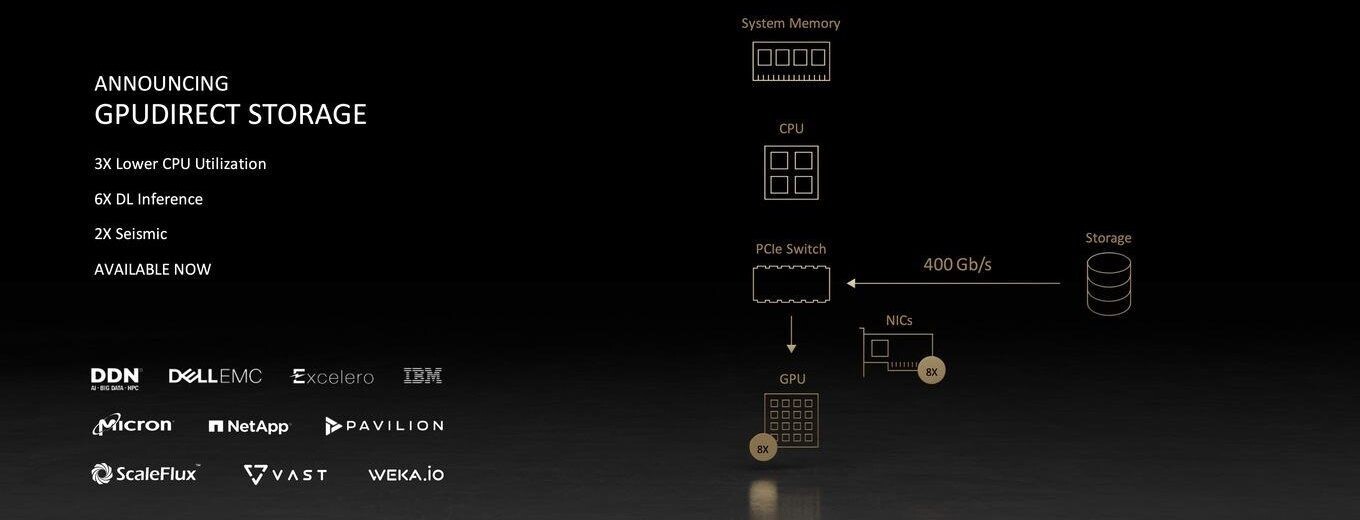
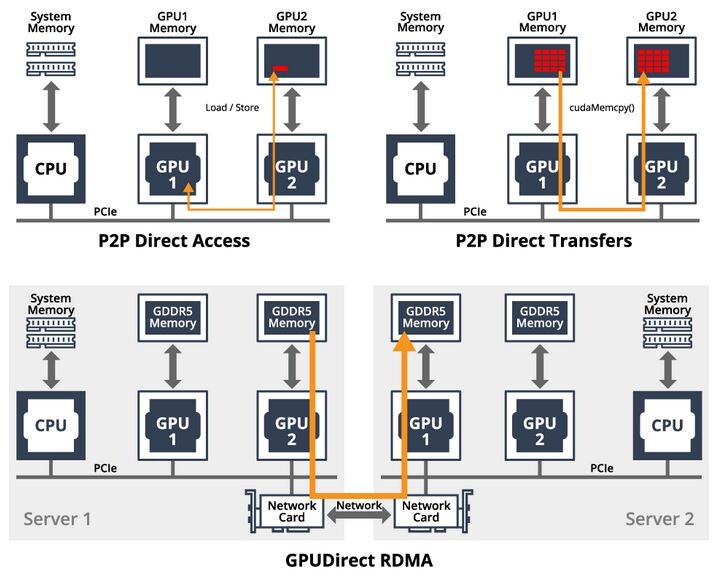
To pair with the new upgrade, NVIDIA made another announcement today and that is an enterprise version of Microsoft's DirectStorage, called NVIDIA GPUDirect Storage. It represents a way of allowing applications to access the massive memory pool built on the GPU, with 80 GB of super-fast HBM2E memory.

To pair with the new upgrade, NVIDIA made another announcement today and that is an enterprise version of Microsoft's DirectStorage, called NVIDIA GPUDirect Storage. It represents a way of allowing applications to access the massive memory pool built on the GPU, with 80 GB of super-fast HBM2E memory.