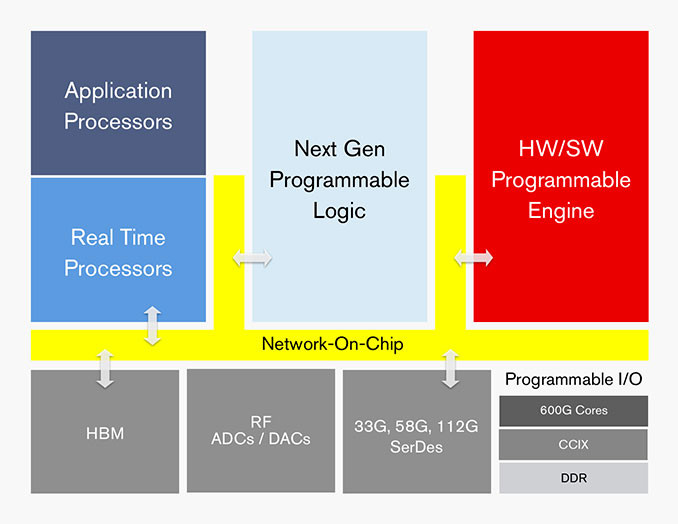
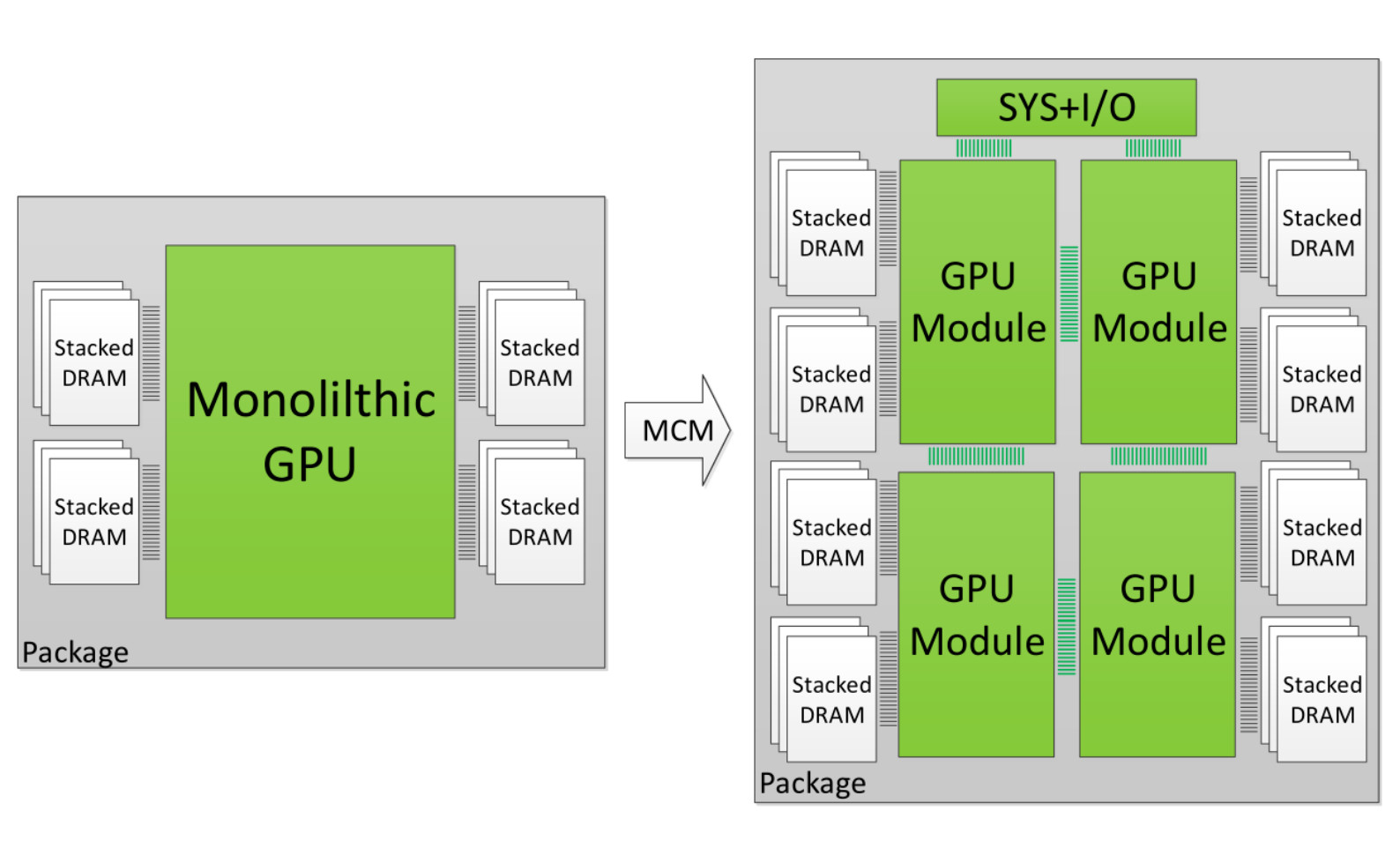
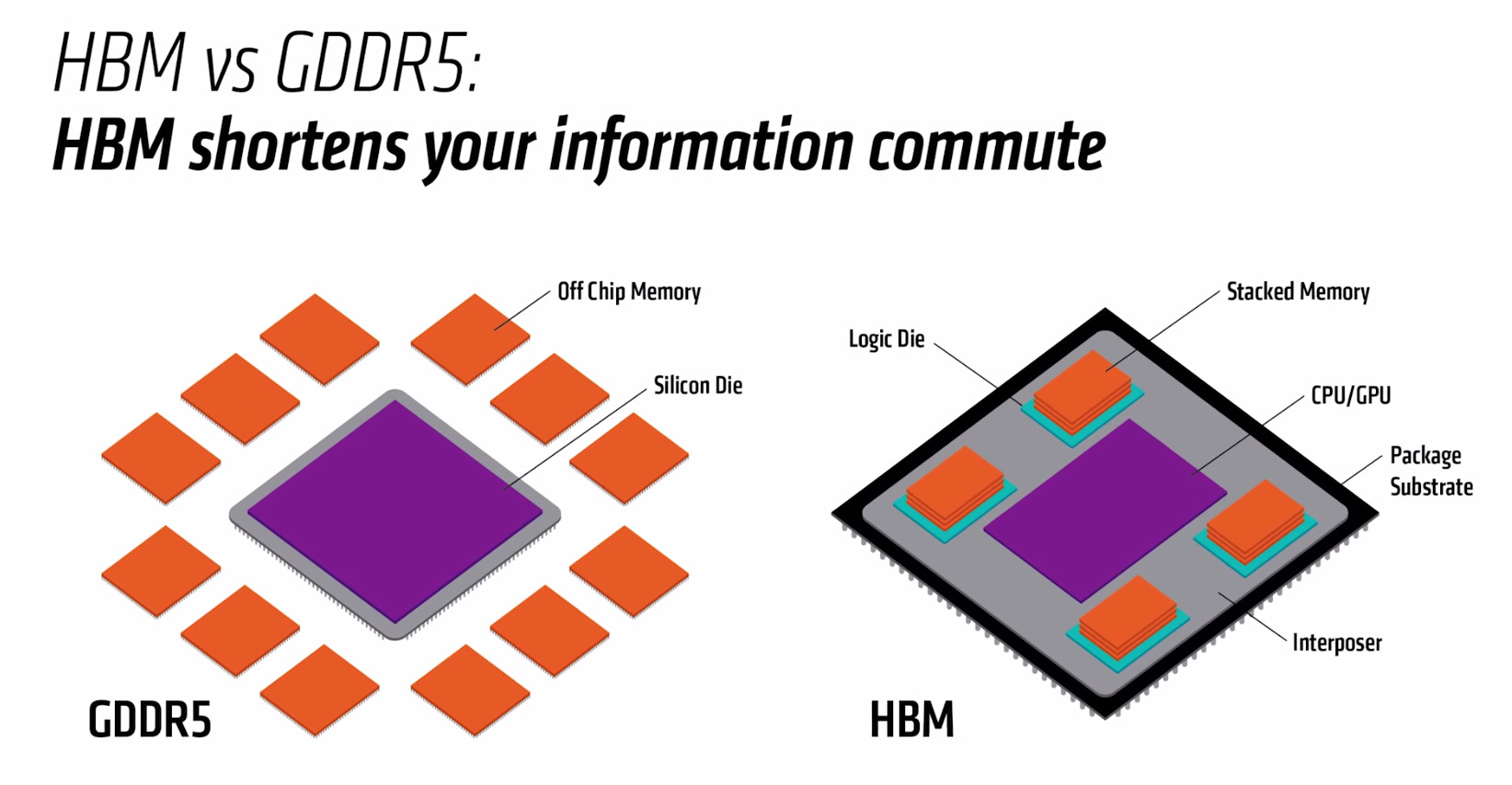
Rambus Advances HBM2E Performance to 4.0 Gbps for AI/ML Training Applications
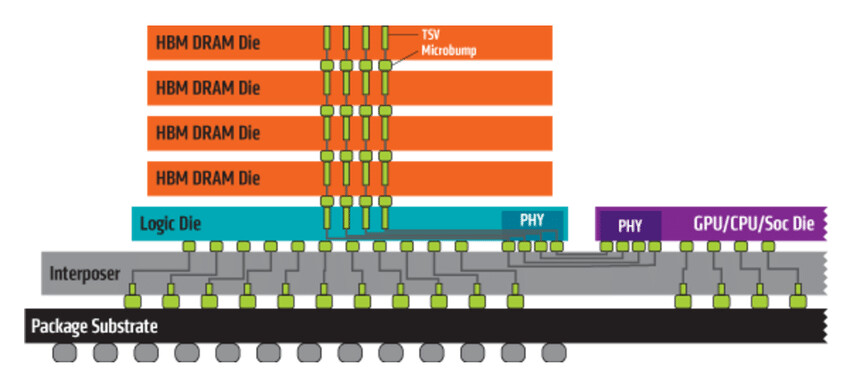
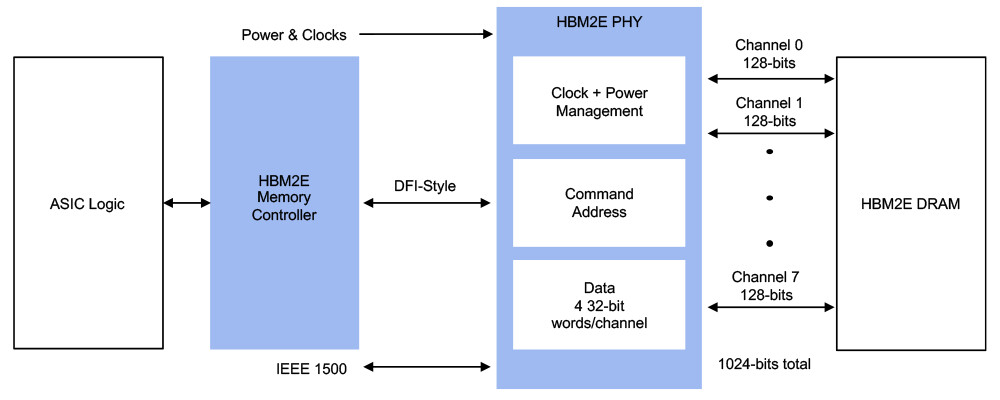
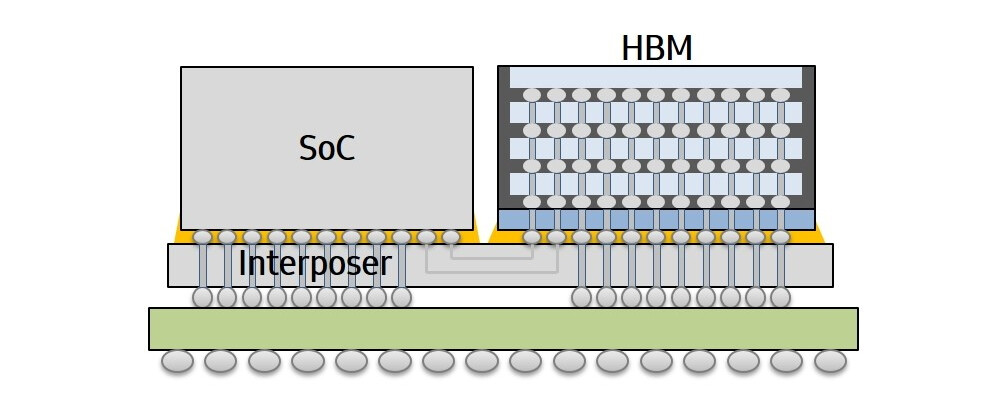
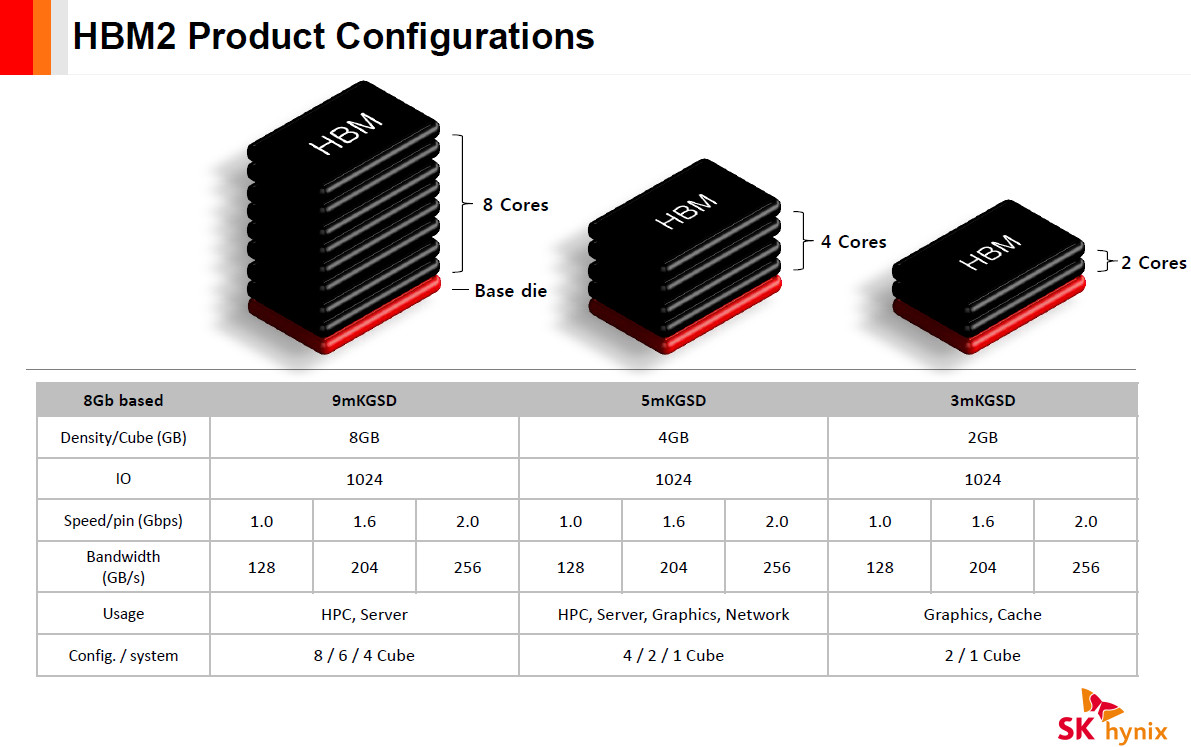
Rambus Inc. (NASDAQ: RMBS), a premier silicon IP and chip provider making data faster and safer, today announced it has achieved a record 4 Gbps performance with the Rambus HBM2E memory interface solution consisting of a fully-integrated PHY and controller. Paired with the industry's fastest HBM2E DRAM from SK hynix operating at 3.6 Gbps, the solution can deliver 460 GB/s of bandwidth from a single HBM2E device. This performance meets the terabyte-scale bandwidth needs of accelerators targeting the most demanding AI/ML training and high-performance computing (HPC) applications.
"With this achievement by Rambus, designers of AI and HPC systems can now implement systems using the world's fastest HBM2E DRAM running at 3.6 Gbps from SK hynix," said Uksong Kang, vice president of product planning at SK hynix. "In July, we announced full-scale mass-production of HBM2E for state-of-the-art computing applications demanding the highest bandwidth available."
"With this achievement by Rambus, designers of AI and HPC systems can now implement systems using the world's fastest HBM2E DRAM running at 3.6 Gbps from SK hynix," said Uksong Kang, vice president of product planning at SK hynix. "In July, we announced full-scale mass-production of HBM2E for state-of-the-art computing applications demanding the highest bandwidth available."