NVIDIA Allegedly Preparing H100 GPU with 94 and 64 GB Memory
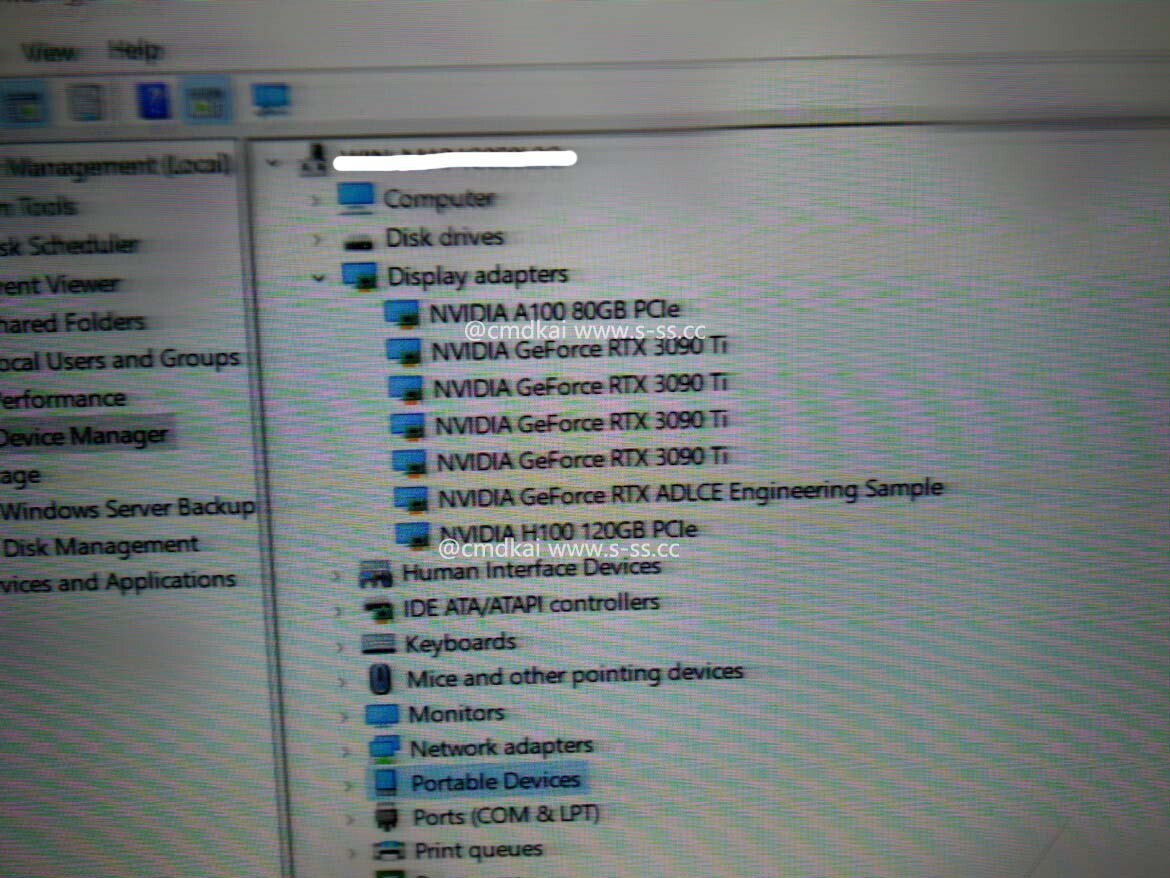
NVIDIA's compute and AI-oriented H100 GPU is supposedly getting an upgrade. The H100 GPU is NVIDIA's most powerful offering and comes in a few different flavors: H100 PCIe, H100 SXM, and H100 NVL (a duo of two GPUs). Currently, the H100 GPU comes with 80 GB of HBM2E, both in the PCIe and SXM5 version of the card. A notable exception if the H100 NVL, which comes with 188 GB of HBM3, but that is for two cards, making it 94 GB per each. However, we could see NVIDIA enable 94 and 64 GB options for the H100 accelerator soon, as the latest PCI ID Repository shows.
According to the PCI ID Repository listing, two messages are posted: "Kindly help to add H100 SXM5 64 GB into 2337." and "Kindly help to add H100 SXM5 94 GB into 2339." These two messages indicate that NVIDIA could prepare its H100 in more variations. In September 2022, we saw NVIDIA prepare an H100 variation with 120 GB of memory, but that still isn't official. These PCIe IDs could just come from engineering samples that NVIDIA is testing in the labs, and these cards could never appear on any market. So, we have to wait and see how it plays out.
According to the PCI ID Repository listing, two messages are posted: "Kindly help to add H100 SXM5 64 GB into 2337." and "Kindly help to add H100 SXM5 94 GB into 2339." These two messages indicate that NVIDIA could prepare its H100 in more variations. In September 2022, we saw NVIDIA prepare an H100 variation with 120 GB of memory, but that still isn't official. These PCIe IDs could just come from engineering samples that NVIDIA is testing in the labs, and these cards could never appear on any market. So, we have to wait and see how it plays out.