Friday, November 24th 2017

Vega 8 Mobile GPU Seemingly Ditches HBM2 Memory, Makes Use of System DDR4 Pool
Update: Industry sources are saying that the 256 MB dedicated system memory to graphics card tasks is currently a firmware limitation, and should be expanded in future firmware revisions to 512 MB and even 1 GB of fully-addressable system DDR4 memory.
AMD's mobile APUs are expected to come with a range of graphics solutions, one of which is the titular Vega 8. Vega 8 isn't supposed to be a high-performance, desktop-class GPU implementation. Instead, it's AMD's counter to NVIDIA's recently announced MX 110 and MX 130 discrete GPUs, which usually deliver relatively low gains (as much as manufacturers want to tout them as extraordinary) when compared to Intel integrated solutions, by far the most widespread IGP. It's expected that Vega 8 performance will slot somewhere around MX110-MX130 levels; and being the low-performance, low cost solution that it's aiming to be, Vega 8 has been made almost unrecognizable from the Vegas we know.
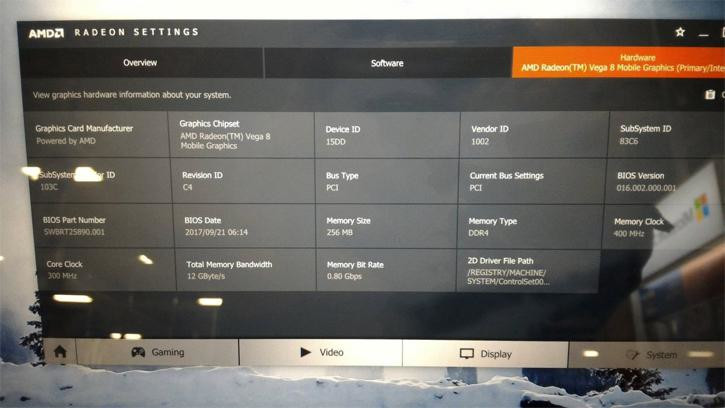
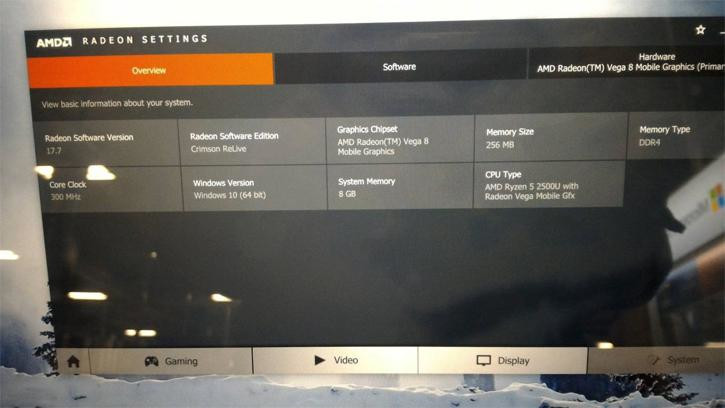
 Vega 8 might signify that the graphics chip has 8 NGCUs at its disposal (Vega 64 has 64, and Vega 56 should be pretty self explanatory), which amounts to just 512 shader units. Via HP's recently outed Envy x360 laptops and a carefully taken photo of the Radeon Settings Hardware panel, we can see that this solution eschews the HBM2 memory (which is only natural, considering the pricing and performance of this solution), and instead, seems to make do with just 256 MB of dedicated system memory - out of a possible 8 GB of DDR4 RAM available in the machine.
Vega 8 might signify that the graphics chip has 8 NGCUs at its disposal (Vega 64 has 64, and Vega 56 should be pretty self explanatory), which amounts to just 512 shader units. Via HP's recently outed Envy x360 laptops and a carefully taken photo of the Radeon Settings Hardware panel, we can see that this solution eschews the HBM2 memory (which is only natural, considering the pricing and performance of this solution), and instead, seems to make do with just 256 MB of dedicated system memory - out of a possible 8 GB of DDR4 RAM available in the machine.
The lack of actual dedicated GDDR or HBM memory means that costs are shaved down as much as they can possibly be, but also equates to a performance murder. In terms of shaders, the Vega 8 likely counts 512 (8x64), which is equivalent in number, if not in performance (due to Vega's architecture improvements) to the RX 540. However, the lack of high-speed dedicated memory cuts this graphics solution's available bandwidth down to 12 GB/s - and the core runs at a much cooler and power-sipping 300 MHz base, with up to 1.1 GHz boost clocks.
Sources:
TweakTown, Hardware Info, Thanks @ P4-630!
AMD's mobile APUs are expected to come with a range of graphics solutions, one of which is the titular Vega 8. Vega 8 isn't supposed to be a high-performance, desktop-class GPU implementation. Instead, it's AMD's counter to NVIDIA's recently announced MX 110 and MX 130 discrete GPUs, which usually deliver relatively low gains (as much as manufacturers want to tout them as extraordinary) when compared to Intel integrated solutions, by far the most widespread IGP. It's expected that Vega 8 performance will slot somewhere around MX110-MX130 levels; and being the low-performance, low cost solution that it's aiming to be, Vega 8 has been made almost unrecognizable from the Vegas we know.
The lack of actual dedicated GDDR or HBM memory means that costs are shaved down as much as they can possibly be, but also equates to a performance murder. In terms of shaders, the Vega 8 likely counts 512 (8x64), which is equivalent in number, if not in performance (due to Vega's architecture improvements) to the RX 540. However, the lack of high-speed dedicated memory cuts this graphics solution's available bandwidth down to 12 GB/s - and the core runs at a much cooler and power-sipping 300 MHz base, with up to 1.1 GHz boost clocks.
49 Comments on Vega 8 Mobile GPU Seemingly Ditches HBM2 Memory, Makes Use of System DDR4 Pool
late edit: fixed terrible typos
You need to make changes to the die meaning you need to make a new mask for the Fab and then it needs to tape-out and you need to validate it. It'll take many months and millions to get such a product ready. It's not as simple as switching a component on an assembly line. It becomes a new chip.
If the memory controller was external, then it should be really simple. But it is true that they don't need to start from scratch to implement GDDR on Vega. The blocks are interchangeable with little work.
Integrated graphics are designed with system memory in mind and always have been for AMD. That's why it's a surprise to no one that Raven Ridge does not have HBM. It's been known for months. The package would also be much different to support dedicated memory and would add considerable cost, size, complexity and power. You'd probably see a $100-200 premium (conservative estimate) on every single device with a Raven Ridge chip (depending on memory configuration). Alternatively they would have to spend those millions and months making two chips. There is a budget constraint going on at AMD. It simply isn't feasible to do so. They need to make one-size-fits-all chips to get as much money out of each chip and so far it's working but it isn't the best for every situation. Hopefully, AMD can start making multiple chips per generation like Intel and Nvidia does; perhaps next year.
3DMark 11 scores for the Vega 8 in the HP convertible are unequivocally faster than the common HD Graphics solutions found on the Intel U-class family. They may not be as impressive as the recently leaked graphics capabilities of the rumored AMD-Intel Core i7-8705G, but performance is still comfortably midway between the Maxwell GeForce 940MX and Pascal GeForce MX150. When considering that these Nvidia alternatives are discrete GPUs, we can't help but commend AMD's powerful integrated solution.
www.notebookcheck.net/Our-first-Ryzen-5-2500U-benchmarks-are-in-and-Intel-has-every-reason-to-worry.266618.0.htmlI only have to say /facepalm.
And it isn't even the fastest APU.
What AMD should done is like what they planned on Kaveri by implementing quad channel memory (256-bit) and/or GDDR5 memory. You can read Anandtech article about it. IMO for mobile they could just ditch regular DDR and use GDDR5. There's no need for additional slot just soldered it on the motherboard. GDDR5 have been around since 2007, it shoudnt costs that much. A standard dual channel (128-bit) GDDR5 runs at measly 1GHz (4GHz effective) netted 64GB/s bandwidth. Modern GDDR5 runs at twice the speed of that.
The fact is that the APU doesn't have a memory controller most likely, it uses the CPU memory controller.
in APU's you can do that.
--
They are using 15W fucking watts.
Know how much power a GTX1080 use? take just the memory and you have a complete laptop running and playing a game at less power than the memory on a 1080.
So, Should we go back to the 10 cm thick ultrabook laptops cause we as desktop gamers find something 2x the speed of intel igpu is bad for ultraportable laptops that use 15-25 watts?
This whole thread contains a few smart guys who understand the product and everyone else that thinks this is meant to destroy Nvidia dedicated gpu's... Nope.
If amd makes a 45 W part with memory then we can see what they can do.
This is 110% made to fight Intel-intel systems and if they can fix video playback power consumption I really think they nailed it... they beat Intel then
HBM2 for any APU would be possible, but only with Intel's superior "interposer" tech, because that one is far easier and cheaper to produce. But I don't think Intel is giving it to AMD just like that - just for the one project they are working on in tandem.
Now for some speculation: could AMDs collaboration with Intel have given them access to EMIB on AMD-only products? That would be a pretty reasonable thing to licence, no? If so, that would bode for some production cost drops in GPUs, and possibly APUs with HBM down the line.
But let's assume Intel trades EMIB for either general GPU patents or Radeon tech. Is it of equal value? I don't think so personally.
And who's to say AMD isn't working on something similar to EMIB (of course without infringing)? It would seem wise to have had something in the works to replace interposers unless AMD has had no foresight as to the money drain HBM and interposers have turned out to be.
I have no doubt AMD wants EMIB or an EMIB-like solution if nothing else but to save money. Intel doesn't like to play ball though; they only do when they absolutely have to.
Examples being opening up Thunderbolt, KBL-G, relationship with Microsoft and Apple (although funnily enough only on Mac; they told Apple to fuck off when they asked Intel to develop a processor for phones and look how much they regret that today as it wasn't the money sink they thought it'd be).
Other than that, Intel have a habit of making sure the competition has a hard time to put it mildly.
Don't get me wrong, I want AMD to be able to execute on their strategy which ultimately relies on tech enabling the connection of chips together and EMIB is a revolutionary way to do that.
The 1000mm2 size of the interposer maybe isn't a problem. We are not talking about a complicated chip, and neither for last gens manufacturing technologies. It is in fact a really simple piece of silicon and I think made at 45nm or something.
But more to the point: I doubt the price differential is that small. And sure, interposers are "simple" chips with few layers and little work required, but the size is a serious limitation. Heck, Fiji's interposers exceeded GloFo's reticle limit, requiring some special finagling to be able to make them at all. According to Google, standard 300mm silicon wafers cost more than $3 per square inch (that's from 2014, from what I've read prices are higher now). In other words, a 1000mm2 wafer costs a minimum of ~$5 in silicon alone (a square inch is ~650mm2), but given that large square chips have very poor area utilization on circular wafers, the cost is likely to be closer to twice that - and that's before actually etching anything into the chip. The price drop for, say, a 100mm2 EMIB chiplet would scale far better, as yields would be far superior, and there'd be no increase in fab costs. AFAIK the cost of processing a wafer on the same process node is roughly the same no matter the compelxity of the mask, so then you'd be splitting the cost over ... a few dozen interposers per wafer?, compared to hundreds if not thousands of EMIB chiplets per wafer. In other words: fab savings would be significant. Of course, embedding the chiplets into the substrate is probably more complex than soldering(?) an interposer in between a chip and a substrate, which might even the playing field somewhat, but I still have the feeling that EMIB would be dramatically cheaper.
Interposer cost: Actual manufacturing costs, plus whatever profit margins GF or whoever else is involve will have.
EMIB cost(for Intel): Actual manufacturing costs, and sending money from one pocket to the other, one division (PC chips) to the other(manufacturing).
EMIB cost(for AMD): Actual manufacturing costs, plus what Intel will ask from AMD and probably it wouldn't be cheap, because all the assembly of AMD's GPUs/APUs and HBM2 memory will also have to be done at Intel's fabs. I bet Intel charges much more than the typical manufacturer still working with 65nm and 45nm tech for making that interposer.
Maybe you already consider this and maybe you are closer to how things really are. But if didn't, if you just compare the actual manufacturing costs and not what extra Intel could charge AMD, then maybe the difference in costs, between interposer and EMIB, is not that much different for AMD.
And one more thing. AMD going EMIB means depending on Intel and having to sign probably a close contract like the one with GF, meaning that anything goes wrong and they might end up paying dozens of millions for nothing. On the other hand, it can get interposers maybe from many manufacturers out there.