Wednesday, October 31st 2018

AMD Could Solve Memory Bottlenecks of its MCM CPUs by Disintegrating the Northbridge
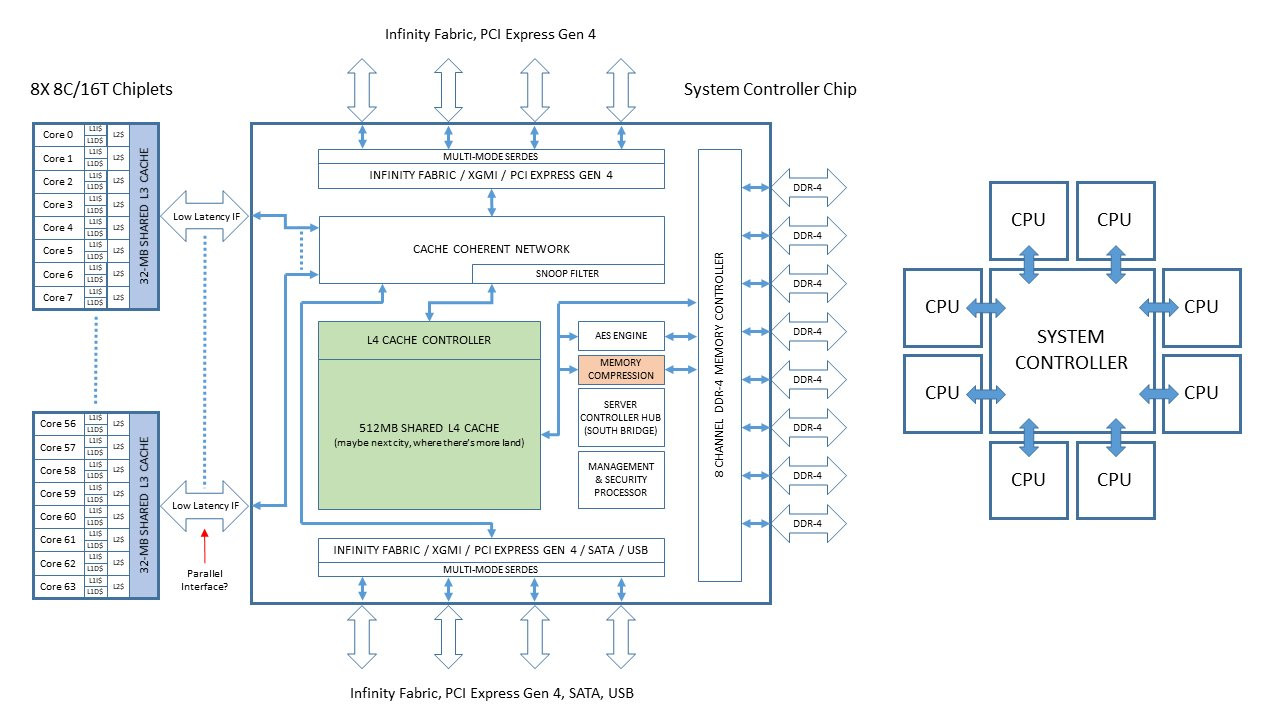
AMD sprung back to competitiveness in the datacenter market with its EPYC enterprise processors, which are multi-chip modules of up to four 8-core dies. Each die has its own integrated northbridge, which controls 2-channel DDR4 memory, and a 32-lane PCI-Express gen 3.0 root complex. In applications that can not only utilize more cores, but also that are memory bandwidth intensive, this approach to non-localized memory presents design bottlenecks. The Ryzen Threadripper WX family highlights many of these bottlenecks, where video encoding benchmarks that are memory-intensive see performance drops as dies without direct access to I/O are starved of memory bandwidth. AMD's solution to this problem is by designing CPU dies with a disabled northbridge (the part of the die with memory controllers and PCIe root complex). This solution could be implemented in its upcoming 2nd generation EPYC processors, codenamed "Rome."
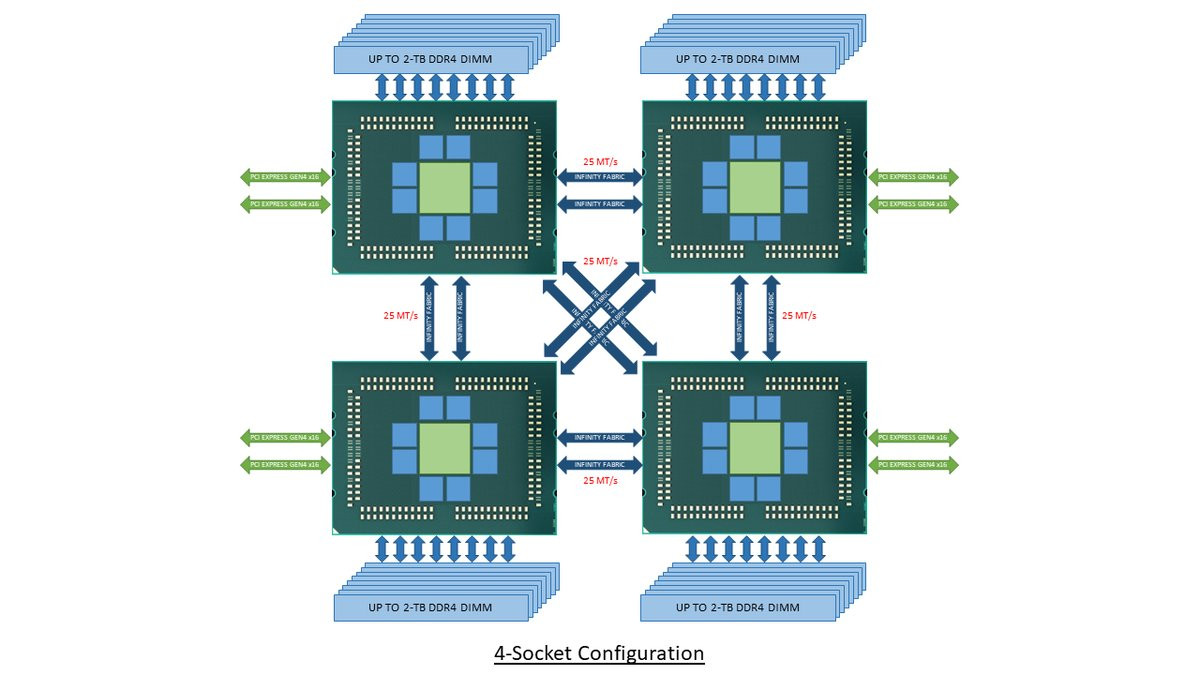
With its "Zen 2" generation, AMD could develop CPU dies in which the integrated northrbidge can be completely disabled (just like the "compute dies" on Threadripper WX processors, which don't have direct memory/PCIe access relying entirely on InfinityFabric). These dies talk to an external die called "System Controller" over a broader InfinityFabric interface. AMD's next-generation MCMs could see a centralized System Controller die that's surrounded by CPU dies, which could all be sitting on a silicon interposer, the same kind found on "Vega 10" and "Fiji" GPUs. An interposer is a silicon die that facilitates high-density microscopic wiring between dies in an MCM. These explosive speculative details and more were put out by Singapore-based @chiakokhua, aka The Retired Engineer, a retired VLSI engineer, who drew block diagrams himself.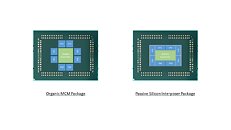
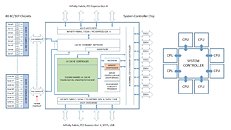
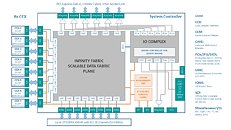
 The System Controller die serves as town-square for the entire processor, and packs a monolithic 8-channel DDR4 memory controller that can address up to 2 TB of ECC memory. Unlike current-generation EPYC processors, this memory interface is truly monolithic, much like Intel's implementation. The System Controller also features a PCI-Express gen 4.0 x96 root-complex, which can drive up to six graphics cards with x16 bandwidth, or up to twelve at x8. The die also integrates the southbridge, known as Server Controller Hub, which puts out common I/O interfaces such as SATA, USB, and other legacy low-bandwidth I/O, in addition to some more PCIe lanes. There could still be external "chipset" on the platform that puts out more connectivity.
The System Controller die serves as town-square for the entire processor, and packs a monolithic 8-channel DDR4 memory controller that can address up to 2 TB of ECC memory. Unlike current-generation EPYC processors, this memory interface is truly monolithic, much like Intel's implementation. The System Controller also features a PCI-Express gen 4.0 x96 root-complex, which can drive up to six graphics cards with x16 bandwidth, or up to twelve at x8. The die also integrates the southbridge, known as Server Controller Hub, which puts out common I/O interfaces such as SATA, USB, and other legacy low-bandwidth I/O, in addition to some more PCIe lanes. There could still be external "chipset" on the platform that puts out more connectivity. The Retired Engineer goes on to speculate that AMD could even design its socket AM4 products as MCMs of two CPU dies sharing a System Controller die; but cautioned to take it with "a bowl of salt." This is unlikely given that the client-segment has wafer-thin margins compared to enterprise, and AMD would want to build single-die products - ones in which the integrated northbridge isn't disabled. Still, that doesn't completely discount the possibility of a 2-die MCM for "high-margin" SKUs that AMD can sell around $500. In such cases, the System Controller die could be leaner, with fewer InfinityFabric links, a 2-channel memory I/O, and a 32-lane PCIe gen 4.0 root.
The Retired Engineer goes on to speculate that AMD could even design its socket AM4 products as MCMs of two CPU dies sharing a System Controller die; but cautioned to take it with "a bowl of salt." This is unlikely given that the client-segment has wafer-thin margins compared to enterprise, and AMD would want to build single-die products - ones in which the integrated northbridge isn't disabled. Still, that doesn't completely discount the possibility of a 2-die MCM for "high-margin" SKUs that AMD can sell around $500. In such cases, the System Controller die could be leaner, with fewer InfinityFabric links, a 2-channel memory I/O, and a 32-lane PCIe gen 4.0 root.
AMD will debut the "Rome" MCM within 2018.
Source:
The Retired Engineer
With its "Zen 2" generation, AMD could develop CPU dies in which the integrated northrbidge can be completely disabled (just like the "compute dies" on Threadripper WX processors, which don't have direct memory/PCIe access relying entirely on InfinityFabric). These dies talk to an external die called "System Controller" over a broader InfinityFabric interface. AMD's next-generation MCMs could see a centralized System Controller die that's surrounded by CPU dies, which could all be sitting on a silicon interposer, the same kind found on "Vega 10" and "Fiji" GPUs. An interposer is a silicon die that facilitates high-density microscopic wiring between dies in an MCM. These explosive speculative details and more were put out by Singapore-based @chiakokhua, aka The Retired Engineer, a retired VLSI engineer, who drew block diagrams himself.


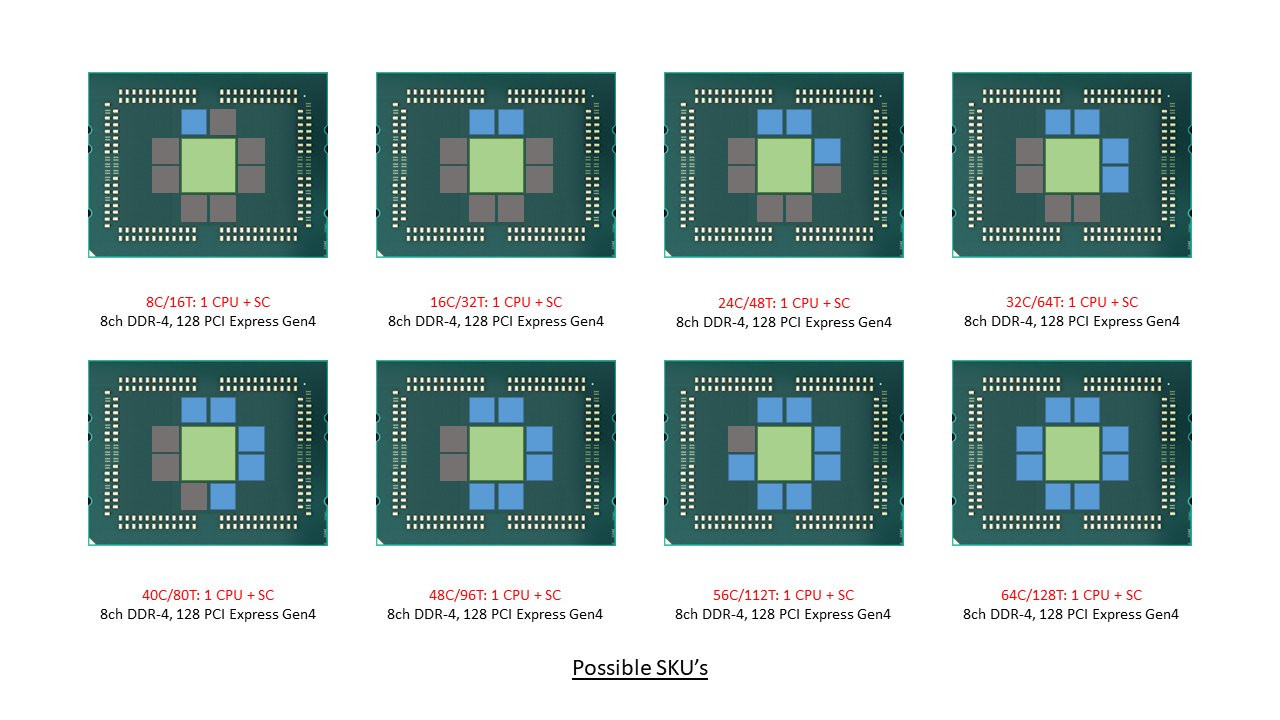

60 Comments on AMD Could Solve Memory Bottlenecks of its MCM CPUs by Disintegrating the Northbridge
It also makes sense that initially Ryzen and EPYC were based off the same design overall and packaging to save cost and now most likely will separate into their own dedicated production lines.
www.hpcwire.com/2018/10/30/cray-unveils-shasta-lands-nersc-9-contract/
There's also a possibility that there will be more than one die, especially for desktops & notebooks.
You mean "theoretical peak FLOPS" unless we are to believe that CPUs in most supercomputers are just for show.
For their "Clown Division"...
Anyway, this design (and others that exist already, as seen in the 2990WX) kinda sounds like a multi socket system... all in one chip. It's great for huge threaded workloads, being wallet friendly, and cramming an obscene amount of cores into one chip/board, but if you're not using it for that, it's detrimental.
I think there will be more dies this time around, Zen had 2 with the second one being RR having an IGP.
AMD's CCX design is great, but even that has its limits, as when you put a bunch of them together, they all have to communicate with each other in some way... but there was a reason everything moved off the board onto the CPU, it's much faster that way. AMD certainly has an issue on their hands... and this move seems like a gamble to me. Time will tell if they come out with a hit of a flop...
Tldr - Unless i am misunderstanding something; this approach will only lower the min-max delta to make a more consistent latency in all workloads, but that would be achieved by increasing min latency and decreasing max latency - counter productive if true
So to access the L3 Cache that is on another die it requires 3 hops, first from the CCX to the local SOC, second to SOC of the other die, then from the other SOC to the CCX with the L3.
On this new layout the number of hops is 2, first to the Central Hub, second to the other CCX where the L3 is located.
What this does though, is avoid the issues with the 2990WX / 2970WX where some cores needs 3 hops to the memory.
First from CCX to local SOC then to the SOC on the IO Die.
Also the 2-Die Threadripper connects to each other via 2 links of Infinity Fabric, and the 4-Die version only has 1 connection to each die, so half the bandwidth.
If each Zen 2 die also keeps its 2 IF links, it would always have as much if not double bandwidth to the memory, if AMD can keep the IF speed the same as Zen 1.
On Zen 2 each CCX is always 1 hop away from memory, meaning it will have consistent latency across all dies.
For gaming isn't it mostly the maximum latency that cause frame-time issues?
After all the 1% and 0.1% lows are measuring the max frame time between each frame, as the minimum frame time aka Max FPS isn't nearly as important.