Tuesday, June 11th 2019

AMD Radeon RX 5700 XT Confirmed to Feature 64 ROPs: Architecture Brief
AMD "Navi 10" is a very different GPU from the "Vega 10," or indeed the "Polaris 10." The GPU sees the introduction of the new RDNA graphics architecture, which is the first big graphics architecture change on an AMD GPU in nearly a decade. AMD had in 2011 released its Graphics CoreNext (GCN) architecture, and successive generations of GPUs since then, brought generational improvements to GCN, all the way up to "Vega." At the heart of RDNA is its brand new Compute Unit (CU), which AMD redesigned to increase IPC, or single-thread performance.
Before diving deeper, it's important to confirm two key specifications of the "Navi 10" GPU. The ROP count of the silicon is 64, double that of the "Polaris 10" silicon, and same as "Vega 10." The silicon has sixteen render-backends (RBs), these are quad-pumped, which work out to an ROP count of 64. AMD also confirmed that the chip has 160 TMUs. These TMUs are redesigned to feature 64-bit bi-linear filtering. The Radeon RX 5700 XT maxes out the silicon, while the RX 5700 disables four RDNA CUs, working out to 144 TMUs. The ROP count on the RX 5700 is unchanged at 64.


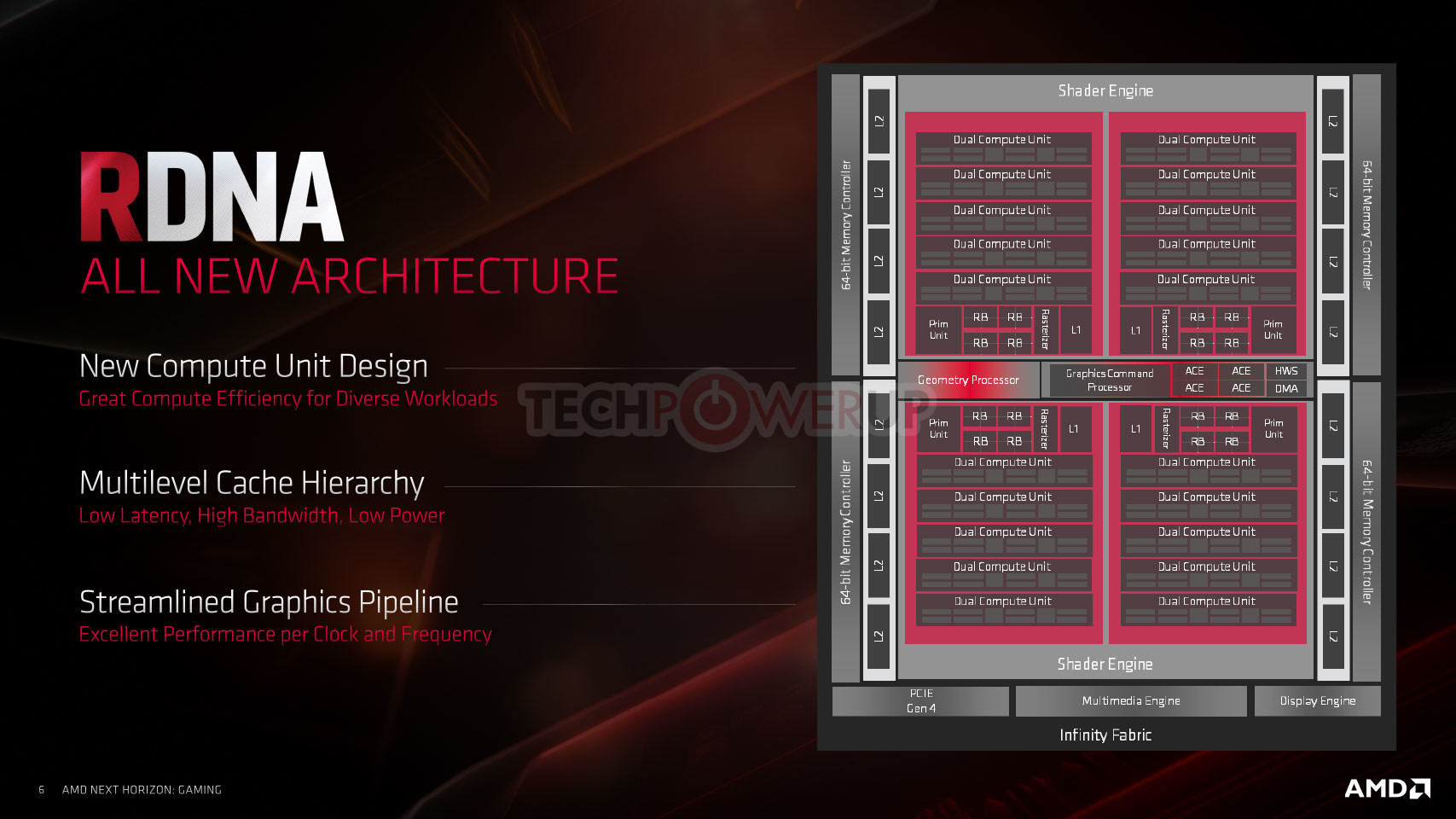
 The RDNA Compute Unit sees the bulk of AMD's innovation. Groups of two CUs make a "Dual Compute Unit" that share a scalar data cahe, shader instruction cache, and a local data share. Each CU is now split between two SIMD units of 32 stream processors, a vector register, and a scalar unit, each. This way, AMD doubled the number of scalar units on the silicon to 80, double the CU count. Each scalar unit is similar in concept to a CPU core, and is designed to handle heavy scalar indivisible workloads. Each SIMD unit has its own scheduler. Four TMUs are part of each CU. This massive redesign in SIMD and CU hierarchy achieves a doubling in scalar- and vector instruction rates, and resource pooling between every two adjacent CUs.
The RDNA Compute Unit sees the bulk of AMD's innovation. Groups of two CUs make a "Dual Compute Unit" that share a scalar data cahe, shader instruction cache, and a local data share. Each CU is now split between two SIMD units of 32 stream processors, a vector register, and a scalar unit, each. This way, AMD doubled the number of scalar units on the silicon to 80, double the CU count. Each scalar unit is similar in concept to a CPU core, and is designed to handle heavy scalar indivisible workloads. Each SIMD unit has its own scheduler. Four TMUs are part of each CU. This massive redesign in SIMD and CU hierarchy achieves a doubling in scalar- and vector instruction rates, and resource pooling between every two adjacent CUs.



 Groups of five RDNA dual-compute unit share a prim unit, a rasterizer, 16 ROPs, and a large L1 cache. Two such groups make a Shader Engine, and the two Shader Engines meet at a centralized Graphics Command Processor that marshals workloads between the various components, a Geometry Processor, and four Asynchronous-Compute Engines (ACEs).
Groups of five RDNA dual-compute unit share a prim unit, a rasterizer, 16 ROPs, and a large L1 cache. Two such groups make a Shader Engine, and the two Shader Engines meet at a centralized Graphics Command Processor that marshals workloads between the various components, a Geometry Processor, and four Asynchronous-Compute Engines (ACEs).

 The second major redesign "Navi" features over previous generations is the cache hierarchy. Each RDNA dual-CU has a local fast cache AMD refers to as L0 (level zero). Each 16 KB L0 unit is made up of the fastest SRAM, and cushions direct transfers between the compute units and the L1 cache, bypassing the compute unit's I-cache and K-cache. The 128 KB L1 cache shared between five dual-CUs is a 16-way block of fast SRAM cushioning transfers between the shade engines and the 4 MB of L2 cache.
The second major redesign "Navi" features over previous generations is the cache hierarchy. Each RDNA dual-CU has a local fast cache AMD refers to as L0 (level zero). Each 16 KB L0 unit is made up of the fastest SRAM, and cushions direct transfers between the compute units and the L1 cache, bypassing the compute unit's I-cache and K-cache. The 128 KB L1 cache shared between five dual-CUs is a 16-way block of fast SRAM cushioning transfers between the shade engines and the 4 MB of L2 cache.
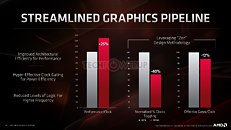
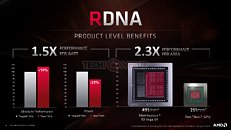
In all, RDNA helps AMD achieve a 2.3x gain in performance per area, 1.5x gain in performance per Watt. The "Navi 10" silicon measures just 251 mm² compared to the 495 mm² of the "Vega 10" GPU die. A lot of these spatial gains are also attributable to the switch to the new 7 nm silicon fabrication process from 14 nm.


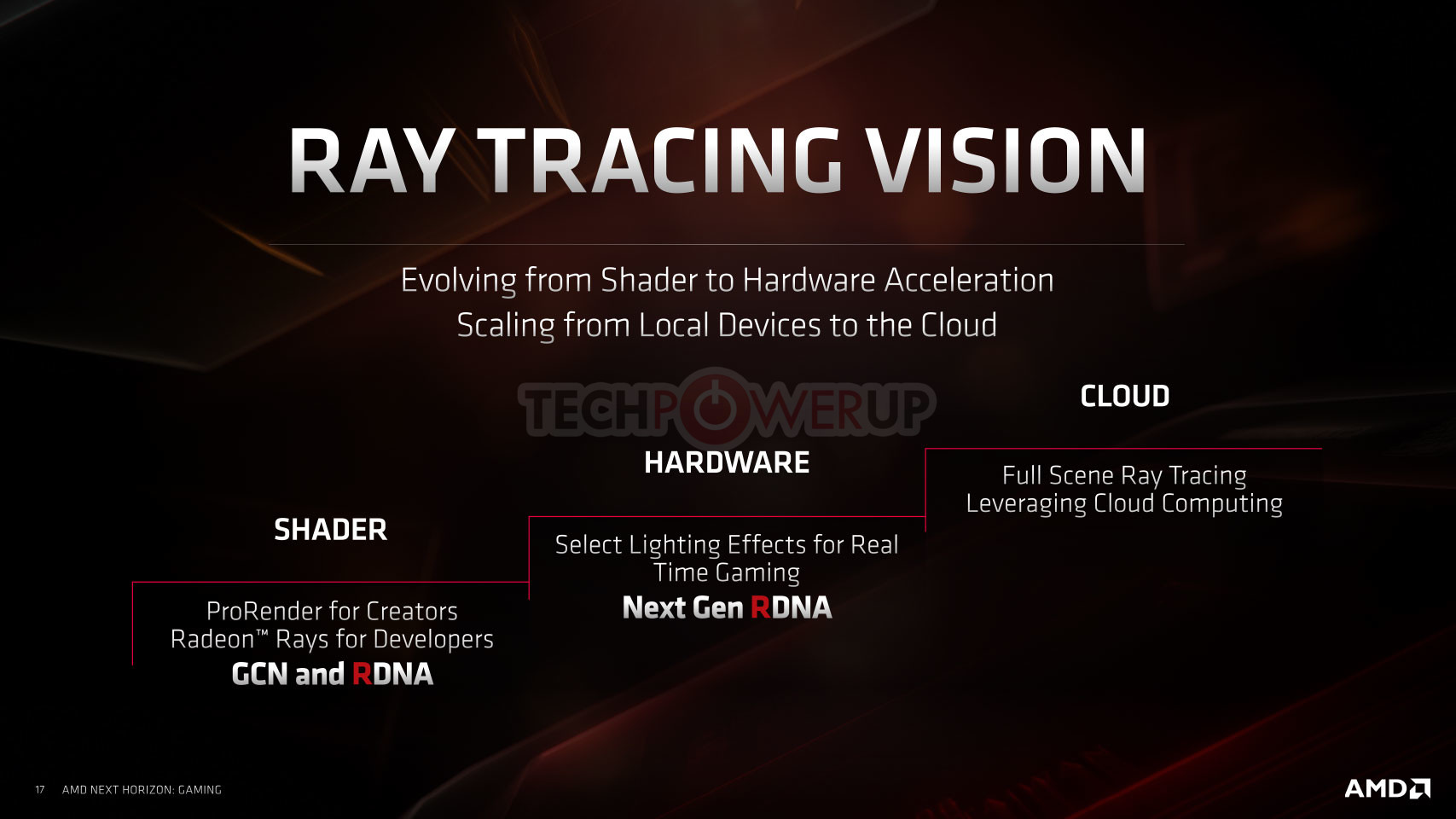
 AMD also briefly touched on its vision for real-time ray-tracing. To begin with, we can confirm that the "Navi 10" silicon has no fixed function hardware for ray-tracing such as the RT core or tensor cores found in NVIDIA "Turing" RTX GPUs. For now, AMD's implementation of DXR (DirectX Ray-tracing) for now relies entirely on programmable shaders. At launch the RX 5700 series won't be advertised to support DXR. AMD will instead release support through driver updates. The RDNA 2 architecture scheduled for 2020-21 will pack some fixed-function hardware for certain real-time ray-tracing effects. AMD sees a future in which real-time ray-tracing is handled on the cloud. The next frontier for cloud-computing is cloud-assist, where your machine can offload processing workloads to the cloud.
AMD also briefly touched on its vision for real-time ray-tracing. To begin with, we can confirm that the "Navi 10" silicon has no fixed function hardware for ray-tracing such as the RT core or tensor cores found in NVIDIA "Turing" RTX GPUs. For now, AMD's implementation of DXR (DirectX Ray-tracing) for now relies entirely on programmable shaders. At launch the RX 5700 series won't be advertised to support DXR. AMD will instead release support through driver updates. The RDNA 2 architecture scheduled for 2020-21 will pack some fixed-function hardware for certain real-time ray-tracing effects. AMD sees a future in which real-time ray-tracing is handled on the cloud. The next frontier for cloud-computing is cloud-assist, where your machine can offload processing workloads to the cloud.
Before diving deeper, it's important to confirm two key specifications of the "Navi 10" GPU. The ROP count of the silicon is 64, double that of the "Polaris 10" silicon, and same as "Vega 10." The silicon has sixteen render-backends (RBs), these are quad-pumped, which work out to an ROP count of 64. AMD also confirmed that the chip has 160 TMUs. These TMUs are redesigned to feature 64-bit bi-linear filtering. The Radeon RX 5700 XT maxes out the silicon, while the RX 5700 disables four RDNA CUs, working out to 144 TMUs. The ROP count on the RX 5700 is unchanged at 64.












In all, RDNA helps AMD achieve a 2.3x gain in performance per area, 1.5x gain in performance per Watt. The "Navi 10" silicon measures just 251 mm² compared to the 495 mm² of the "Vega 10" GPU die. A lot of these spatial gains are also attributable to the switch to the new 7 nm silicon fabrication process from 14 nm.



38 Comments on AMD Radeon RX 5700 XT Confirmed to Feature 64 ROPs: Architecture Brief
We are not talking about games, we are talking about hardware.
Microsoft confirms Xbox Scarlet's NAVI to be rDNA 2 due to "hardware accelerated" ray-tracing.
(about console ... well they will have RT but nothing Nvidia in it ... that's my point :p )
and to quote someone who is right (which technically mean i shouldn't have replied to you :cry: .... :laugh: )
People may want to get excited about the competition potential of the Intel–AMD duopoly but the fact remains that consoles are parasitic. AMD, working with Sony and MS, is competing against us.
AMD's financial woes weren't our fault. None of us told them to craft Bulldozer to be a server CPU, and not a good one at that.
Its not AMD, you need to blame Nvidia and their buddy Epic are degrading PC gaming. AMD sponsored dont run like crap on pc, nvidia sponsored one runs like crap on pc and compatating gpus.
Just like we are not blame for AMD's past finincial state ralating to cpu, the same way AMD has no obligation to supply parts for a market that returns zero profit.
It's time to stop paying the MS tax of Windows to get DX for gaming and it's time to stop paying the console tax. Or, we can continue to waste our lives with useless "AMD vs. Nvidia" tripe. I would like people to start pushing Vulkan with OpenGL on Linux and the unification of x86 gaming.
Small dies aren't always bad. If yields are really good then they can be a good option for midrange and low-end parts. What they generally aren't very helpful for is high-end performance GPUs, the kind most enthusiasts care about. When a company refuses to produce those parts then it's tempting for them to overcharge for small die parts with excessive clock speed to try to overcome the inherent processing deficit. And/or the competition will keep prices high because of a lack of a competing product, which can, in turn, lead to increased prices in the midrange. Small dies can also work with the chiplet approach, apparently. Let's hope that AMD will find a way to stick together enough chiplets to get some competition into the high-end gaming space. But, instead of just hoping, we should also try to get at least one more company into serious gaming graphics. Apparently Intel is going to try this but since it's part of the CPU duopoly it's hardly ideal from a competition standpoint. But, it would be better than having a weak duopoly which is what we have now, given that AMD isn't even competing at the high end of the GPU space and hasn't for some time.