Wednesday, June 14th 2023

AMD Zen 4c Not an E-core, 35% Smaller than Zen 4, but with Identical IPC
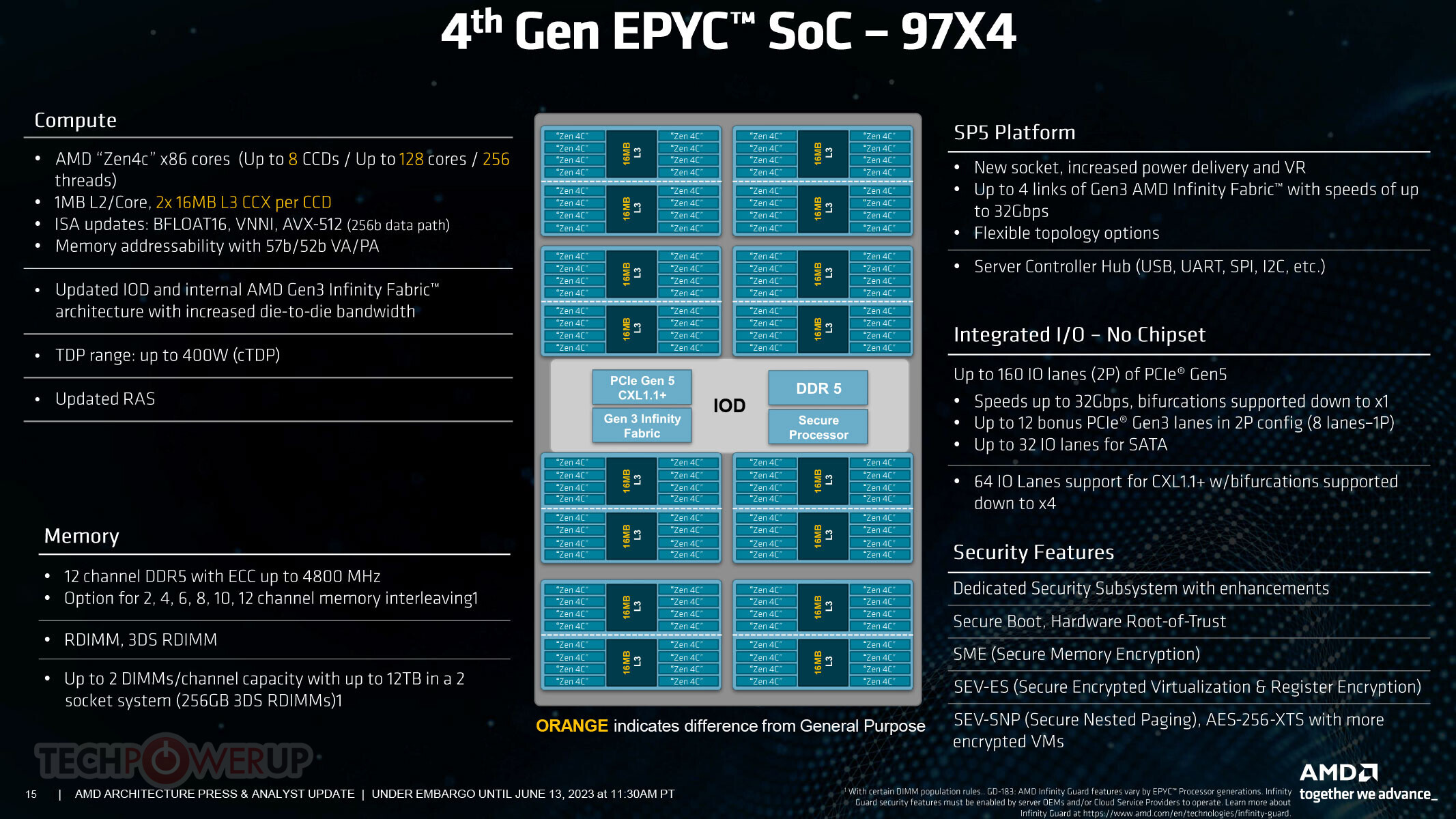
AMD on Tuesday (June 13) launched the EPYC 9004 "Bergamo" 128-core/256-thread high density compute server processor, and with it, debuted the new "Zen 4c" CPU microarchitecture. A lot had been made out about Zen 4c in the run up to yesterday's launch, such as rumors that it is a Zen 4 "lite" core that has lesser number-crunching muscle, and hence lower IPC, and that Zen 4c is AMD's answer to Intel's E-core architectures, such as "Gracemont" and "Crestmont." It turns out that it's neither a lite version of Zen 4, nor is it an E-core, but a physically compacted version of the Zen 4 core, with identical number crunching machinery.
First things first—Zen 4c has the same exact IPC as Zen 4 (that's performance at a given clock-speed). This is because its front-end, execution stage, load/store component, and internal cache hierarchy is exactly the same. It has the same 88-deep load queue, 64-deep store queue, the same 675,000 µop cache, the exact same INT+FP issue width of 10+6, the same exact INT register file, the same scheduler, and cache latencies. The L1I and L1D caches are the same 32 KB in size as "Zen 4," and so is the dedicated L2 cache, at 1 MB.


 The only thing that's changed is that the effective L3 cache per core has been reduced to 2 MB, from 4 MB on the 8-core "Zen 4" CCD. While the regular 8-core "Zen 4" CCD has eight "Zen 4" cores sharing a 32 MB L3 cache, the new 16-core "Zen 4c" CCD AMD introduced with "Bergamo" sees the chiplet pack two 8-core CCX (CPU core complexes), each with 16 MB of L3 cache shared among the 8 cores of the CCX. In this respect, the last-level cache and CPU core organization of the "Zen 4c" CCD has some similarities to the "Zen 2" CCD (which used two 4-core CCXs).
The only thing that's changed is that the effective L3 cache per core has been reduced to 2 MB, from 4 MB on the 8-core "Zen 4" CCD. While the regular 8-core "Zen 4" CCD has eight "Zen 4" cores sharing a 32 MB L3 cache, the new 16-core "Zen 4c" CCD AMD introduced with "Bergamo" sees the chiplet pack two 8-core CCX (CPU core complexes), each with 16 MB of L3 cache shared among the 8 cores of the CCX. In this respect, the last-level cache and CPU core organization of the "Zen 4c" CCD has some similarities to the "Zen 2" CCD (which used two 4-core CCXs).
What's interesting is that the 16-core "Zen 4c" CCD isn't AMD's first product from this generation with lower last-level cache per core. The "Phoenix" APU silicon used in Ryzen 7040 series mobile processors sees eight "Zen 4" cores share a 16 MB L3 cache. For math-heavy compute workloads with lesser memory footprint, "Zen 4c" offers identical performance to "Zen 4," however, the smaller L3 cache should impact performance in bandwidth-sensitive workloads with large data-sets.
 The Zen 4c CCD is built on the same exact TSMC 5 nm EUV foundry node that the company makes its regular 8-core Zen 4 CCD on, however, the Zen 4c CPU core is 35% smaller than the Zen 4 core, with a die area (per-core) of just 2.48 mm², compared to 3.84 mm². The die-size savings probably come from AMD "compacting" the various core components without reducing their form or function in any way. As we said earlier, the counts of the various core components remains the same, as do the sizes of the µ-op, L1, and L2 caches. EPYC 9004 "Bergamo" achieves its core-count of 128 using eight of these 16-core Zen 4c CCDs. In comparison, the regular "Genoa" processor achieves 96 cores over twelve 8-core Zen 4 CCDs.
The Zen 4c CCD is built on the same exact TSMC 5 nm EUV foundry node that the company makes its regular 8-core Zen 4 CCD on, however, the Zen 4c CPU core is 35% smaller than the Zen 4 core, with a die area (per-core) of just 2.48 mm², compared to 3.84 mm². The die-size savings probably come from AMD "compacting" the various core components without reducing their form or function in any way. As we said earlier, the counts of the various core components remains the same, as do the sizes of the µ-op, L1, and L2 caches. EPYC 9004 "Bergamo" achieves its core-count of 128 using eight of these 16-core Zen 4c CCDs. In comparison, the regular "Genoa" processor achieves 96 cores over twelve 8-core Zen 4 CCDs.
First things first—Zen 4c has the same exact IPC as Zen 4 (that's performance at a given clock-speed). This is because its front-end, execution stage, load/store component, and internal cache hierarchy is exactly the same. It has the same 88-deep load queue, 64-deep store queue, the same 675,000 µop cache, the exact same INT+FP issue width of 10+6, the same exact INT register file, the same scheduler, and cache latencies. The L1I and L1D caches are the same 32 KB in size as "Zen 4," and so is the dedicated L2 cache, at 1 MB.



What's interesting is that the 16-core "Zen 4c" CCD isn't AMD's first product from this generation with lower last-level cache per core. The "Phoenix" APU silicon used in Ryzen 7040 series mobile processors sees eight "Zen 4" cores share a 16 MB L3 cache. For math-heavy compute workloads with lesser memory footprint, "Zen 4c" offers identical performance to "Zen 4," however, the smaller L3 cache should impact performance in bandwidth-sensitive workloads with large data-sets.


153 Comments on AMD Zen 4c Not an E-core, 35% Smaller than Zen 4, but with Identical IPC
By default in Windows 10 e-cores are heavily favoured, pretty much all single threaded tasks are loaded on to them and p-cores are parked, this even happens if parking is disabled in the power profile. (ultimate performance). park control also cant override this behaviour.
If I adjust the hetergeneous thread scheduling policy, I can manipulate this behaviour, its a hidden setting in windows. Setting it to either "all processors" or "performant" starts letting p-cores to be used, the latter however almost blocks use of e-cores so not ideal if you still want them to be used. But would be a quick and dirty fix e.g. if you want to fire up a single threaded game, it would give you a almost certainty it would use a p-core and not have to worry about affinity settings. Could use with something like 'AutoPowerOptionsOk' to automate the solution. Setting it to all processors would likely require using something like process hacker to get things working in a optimal way with automation so e.g. affinity for svchost and browsers to e-cores and affinity for games to p-cores (good for security as well as e-cores dont have htt). Both of these schedule options still automatically favour the fastest two p-cores for single threaded cinebench which is nice, on my ryzen cpu's this doesnt happen. It also doesnt happen on my 9900k, a reason why I went to all core clock speed on 9900k. But my testing on ryzen and 9900k was done on 1809, whilst on the 13700k was on 21H2, so its possible 1809 has no programming for "favoured cores" as that was introduced later I think.
AMD of course have this problem as well, with some of their processors for different reasons.
I assume the improvements in Windows 11 are just a better default behaviour when specific cpu's are recognised. For better OOB experience.
"The only thing that's changed is that the effective L3 cache per core has been reduced to 2 MB, from 4 MB on the 8-core "Zen 4" CCD."
If that's true why the slide says 35% smaller comparing just core+L2 ???
TLDR:
It has been power and density optimized allowing for 16 cores per ccx... this means 16 cores share the same cache that...8 shared before...
Now you get 128 core with 8 ccx/core chiplets vs 12 for 96 on zen4
If intel would need to use their server Xeon Phi atom cores they could get on "feature parity" with their "p" cores at least when it comes to hyperthreading and AVX-512. The ATOM cores would still be a heck of a lot slower.
ark.intel.com/content/www/us/en/ark/products/128694/intel-xeon-phi-processor-7235-16gb-1-3-ghz-64-core.html
Intel's E-Cores do not have AVX-512.
Are you using Cinema 4D R25 or Blender 3.x?
-------------------
After 10 minute run, Intel Core i9 13900KS's scores are lower.
However i could see a possible two chiplet AM5 version where one chiplet uses 8 Zen 4 cores and another uses 16 Zen 4c cores giving a total of 24c/48t albeit with a reduced total L3 compared to 7950X (and 7950X3D).
Not sure there is market for such a chip as it would be multi-threaded focused product that would likely suffer the same or worse problems in games as 7950X does and would lose to X3D parts for sure. However there is an argument to be made that a regular 7950X could be replaced by this with small performance hit in cache sensitive workloads. Because 7950X buyers likely care more about core counts rather than cache.
Also im not sure if it's viable to make a model that has two chiplets with different core counts because correct me if im wrong but thus far all AMD models that have used two chiplets have used the same core counts on each chiplet?
The e-cores are not just marketing, It's literally what allows Intel to stay relevant on the conssumer side for people who are not just gaming. Them lacking AVX512 isn't ideal, but it's either that, or let the competition take the performance and efficiency crown across the board
That is absolutely fine for server type usage.Yep the e-cores are keeping intel in the game on production type workloads, like software encoding, compressing, and compiling software. So absolutely used to keep multithreading competitive with AMD.
The p-cores keep them ahead on typical consumer use like gaming, office apps, web browsing, media playback.
Zen4 c-cores are fully capable cores with smaller L3 cache. c-cores support HT and AVX512 workloads; perfect for cloud.
So, Sierra Forest CPU next year will have 144 Atom cores: 144C/114T. Bergamo CPU has 128C/256T. It's a monster chip for cloud computing, trumping both Intel and ARM solutions by several times, while easily slotted in the same socket 6096. Data centre partners will not need to buy new server motherboads either.
Next year, Turin Zen5 c-cores should bring another evolution in design in 16-core chiplets, namely current two 8-core CCX will be unified into 16-core CCX/CCD. If they want to increase core count to 192 c-cores, they will have to change packaging and I/O in order to place additional two chiplets, as there is no space left on current package due to communication pathways. That's why 16-core chiplets on Bergamo are placed apart and not jointly near each other.