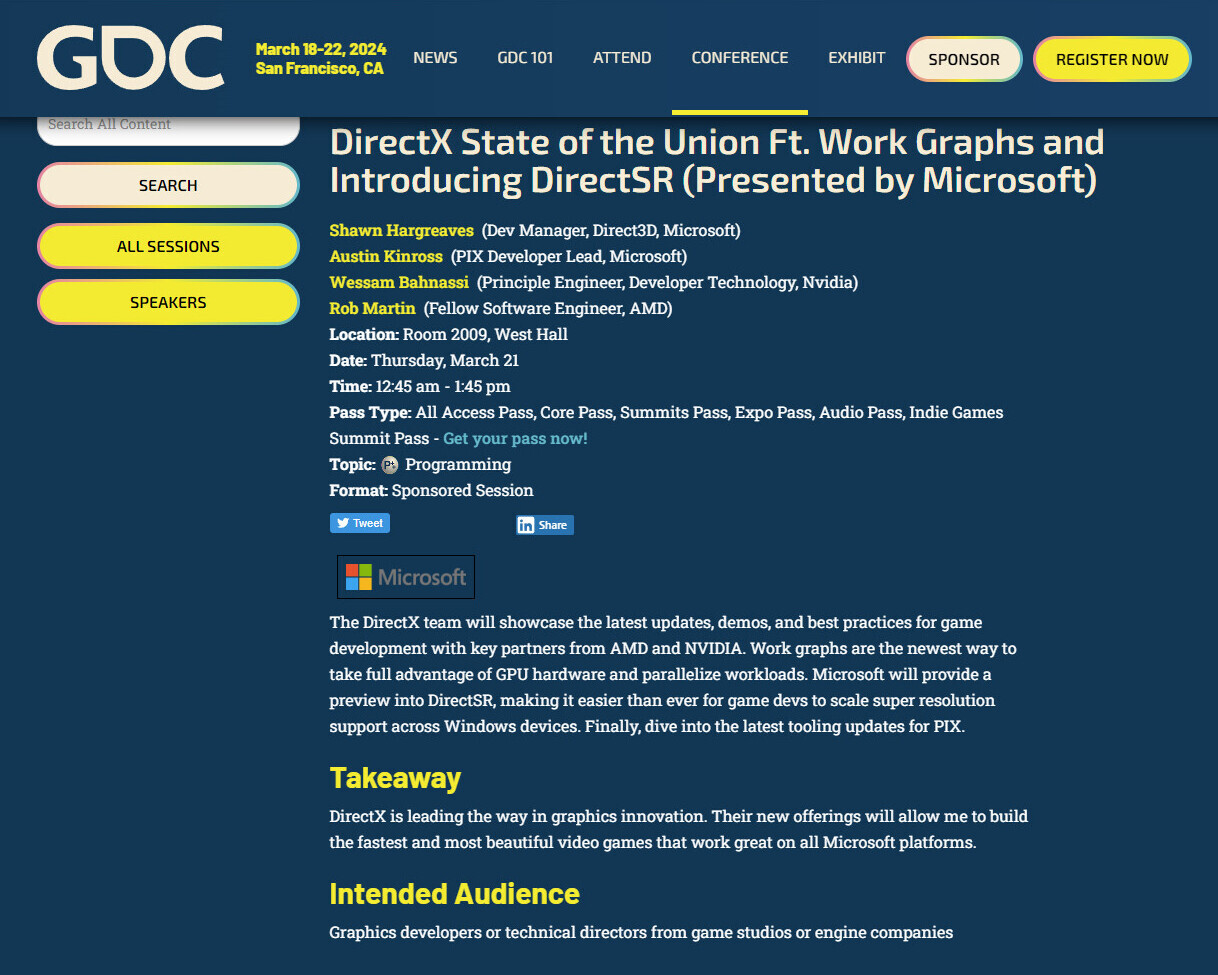
Amazon AWS Announces General Availability of Trainium2 Instances, Reveals Details of Next Gen Trainium3 Chip
At AWS re:Invent, Amazon Web Services, Inc. (AWS), an Amazon.com, Inc. company, today announced the general availability of AWS Trainium2-powered Amazon Elastic Compute Cloud (Amazon EC2) instances, introduced new Trn2 UltraServers, enabling customers to train and deploy today's latest AI models as well as future large language models (LLM) and foundation models (FM) with exceptional levels of performance and cost efficiency, and unveiled next-generation Trainium3 chips.
"Trainium2 is purpose built to support the largest, most cutting-edge generative AI workloads, for both training and inference, and to deliver the best price performance on AWS," said David Brown, vice president of Compute and Networking at AWS. "With models approaching trillions of parameters, we understand customers also need a novel approach to train and run these massive workloads. New Trn2 UltraServers offer the fastest training and inference performance on AWS and help organizations of all sizes to train and deploy the world's largest models faster and at a lower cost."

"Trainium2 is purpose built to support the largest, most cutting-edge generative AI workloads, for both training and inference, and to deliver the best price performance on AWS," said David Brown, vice president of Compute and Networking at AWS. "With models approaching trillions of parameters, we understand customers also need a novel approach to train and run these massive workloads. New Trn2 UltraServers offer the fastest training and inference performance on AWS and help organizations of all sizes to train and deploy the world's largest models faster and at a lower cost."