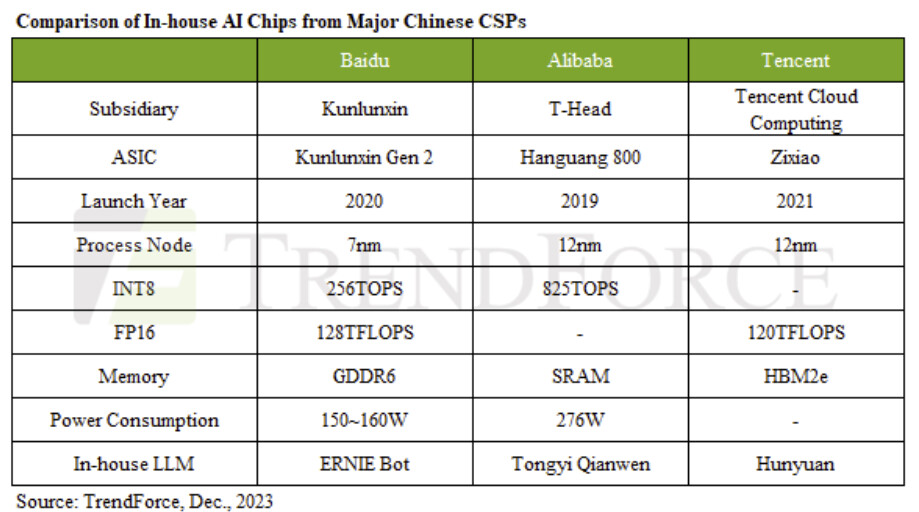
China Continues to Enhance AI Chip Self-Sufficiency, but High-End AI Chip Development Remains Constrained
Huawei's subsidiary HiSilicon has made significant strides in the independent R&D of AI chips, launching the next-gen Ascend 910B. These chips are utilized not only in Huawei's public cloud infrastructure but also sold to other Chinese companies. This year, Baidu ordered over a thousand Ascend 910B chips from Huawei to build approximately 200 AI servers. Additionally, in August, Chinese company iFlytek, in partnership with Huawei, released the "Gemini Star Program," a hardware and software integrated device for exclusive enterprise LLMs, equipped with the Ascend 910B AI acceleration chip, according to TrendForce's research.
TrendForce conjectures that the next-generation Ascend 910B chip is likely manufactured using SMIC's N+2 process. However, the production faces two potential risks. Firstly, as Huawei recently focused on expanding its smartphone business, the N+2 process capacity at SMIC is almost entirely allocated to Huawei's smartphone products, potentially limiting future capacity for AI chips. Secondly, SMIC remains on the Entity List, possibly restricting access to advanced process equipment.
TrendForce conjectures that the next-generation Ascend 910B chip is likely manufactured using SMIC's N+2 process. However, the production faces two potential risks. Firstly, as Huawei recently focused on expanding its smartphone business, the N+2 process capacity at SMIC is almost entirely allocated to Huawei's smartphone products, potentially limiting future capacity for AI chips. Secondly, SMIC remains on the Entity List, possibly restricting access to advanced process equipment.