Humanoid Robots to Assemble NVIDIA's GB300 NVL72 "Blackwell Ultra"
NVIDIA's upcoming GB300 NVL72 "Blackwell Ultra" rack-scale systems are reportedly going to get a humanoid robot assembly, according to sources close to Reuters. As readers are aware, most of the traditional manufacturing processes in silicon manufacturing, PCB manufacturing, and server manufacturing are automated, requiring little to no human intervention. However, rack-scale systems required humans for final assembly up until now. It appears that Foxconn and NVIDIA have made plans to open up the first AI-powered humanoid robot assembly plant in Houston, Texas. The central plan is that, in the coming months as the plant is completed, humanoid robots will take over the final assembly process entirely removing humans from the manufacturing loop.
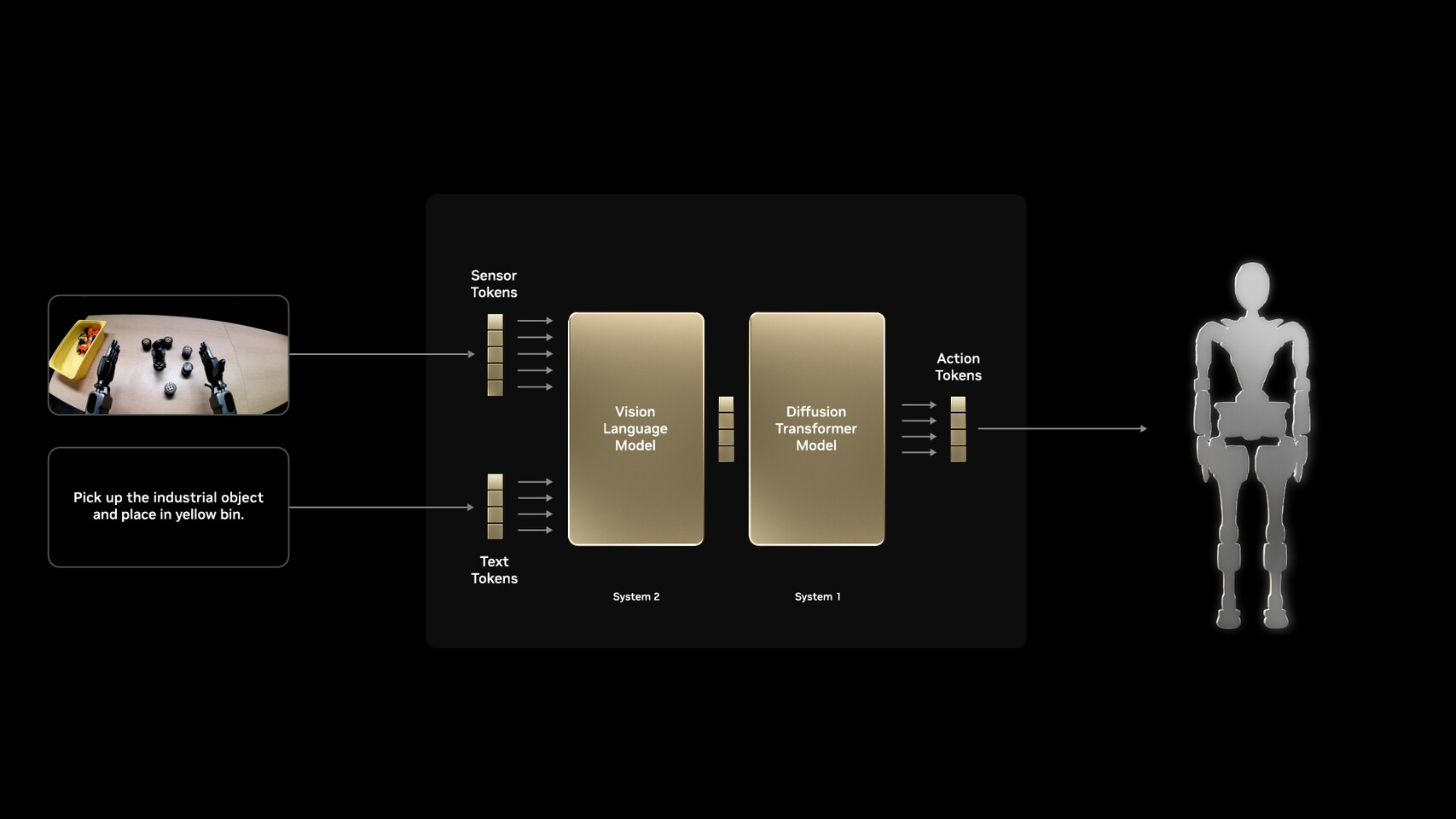
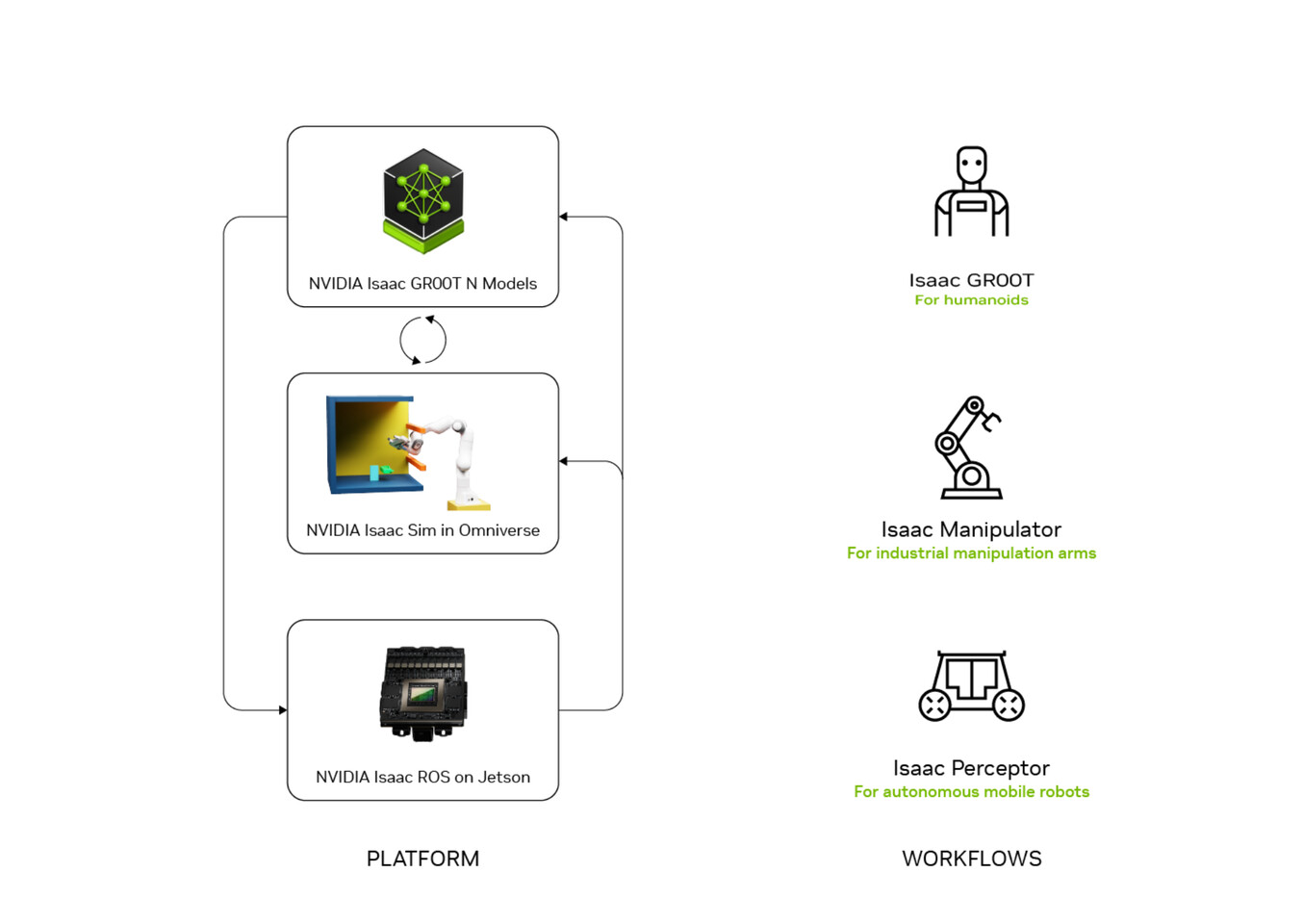
And this is not a bad thing. Since server assembly typically requires lifting heavy server racks throughout the day, the humanoid robot system will aid humans by doing the hard work, thereby saving workers from excessive labor. Initially, humans will oversee these robots in their operations, with fully autonomous factories expected later on. The human element here will primarily involve inspecting the work. NVIDIA has been laying the groundwork for humanoid robots for some time, as the company has developed NVIDIA Isaac, a comprehensive CUDA-accelerated platform designed for humanoid robots. As models from Agility Robotics, Boston Dynamics, Fourier, Foxlink, Galbot, Mentee Robotics, NEURA Robotics, General Robotics, Skild AI, and XPENG require models that are aware of their surroundings, NVIDIA created Isaac GR00T N1, the world's first open humanoid robot foundation model, available for anyone to use and finetune.


And this is not a bad thing. Since server assembly typically requires lifting heavy server racks throughout the day, the humanoid robot system will aid humans by doing the hard work, thereby saving workers from excessive labor. Initially, humans will oversee these robots in their operations, with fully autonomous factories expected later on. The human element here will primarily involve inspecting the work. NVIDIA has been laying the groundwork for humanoid robots for some time, as the company has developed NVIDIA Isaac, a comprehensive CUDA-accelerated platform designed for humanoid robots. As models from Agility Robotics, Boston Dynamics, Fourier, Foxlink, Galbot, Mentee Robotics, NEURA Robotics, General Robotics, Skild AI, and XPENG require models that are aware of their surroundings, NVIDIA created Isaac GR00T N1, the world's first open humanoid robot foundation model, available for anyone to use and finetune.