Tiny Corp. CEO Expresses "70% Confidence" in AMD Open-Sourcing Certain GPU Firmware
Lately Tiny Corp. CEO—George Hotz—has used his company's social media account to publicly criticize AMD Radeon RX 7900 XTX GPU firmware. The creator of Tinybox, a pre-orderable $15,000 AI compute cluster, has not selected "traditional" hardware for his systems—it is possible that AMD's Instinct MI300X accelerator is quite difficult to acquire, especially for a young startup operation. The decision to utilize gaming-oriented XFX-branded RDNA 3.0 GPUs instead of purpose-built CDNA 3.0 platforms—for local model training and AI inference—is certainly a peculiar one. Hotz and his colleagues have encountered roadblocks in the development of their Tinybox system—recently, public attention was drawn to an "LLVM spilling bug." AMD President/CEO/Chair, Dr. Lisa Su, swiftly stepped in and promised a "good solution." Earlier in the week, Tiny Corp. reported satisfaction with a delivery of fixes—courtesy of Team Red's software engineering department. They also disclosed that they would be discussing matters with AMD directly, regarding the possibility of open-sourcing Radeon GPU MES firmware.
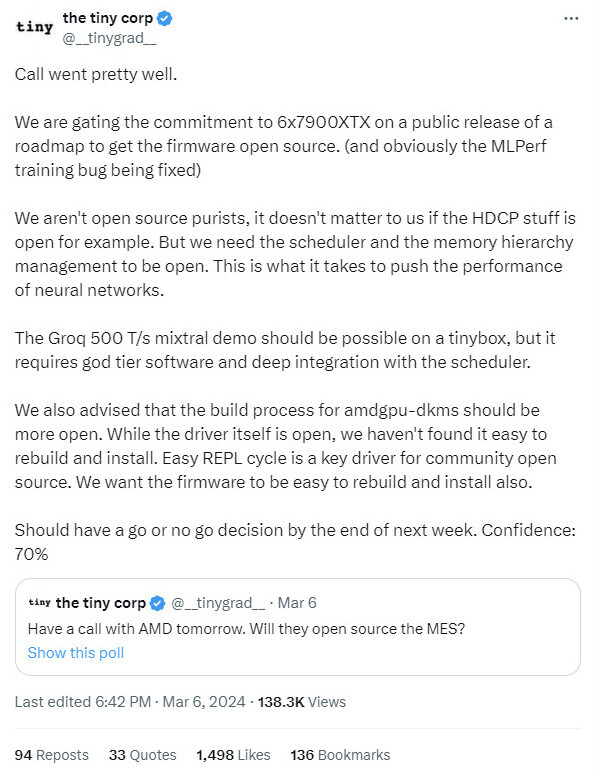
Subsequently, Hotz documented his interactions with Team Red representatives—he expressed 70% confidence in AMD approving open-sourcing certain bits of firmware in a week's time: "Call went pretty well. We are gating the commitment to 6x Radeon RX 7900 XTX on a public release of a roadmap to get the firmware open source. (and obviously the MLPerf training bug being fixed). We aren't open source purists, it doesn't matter to us if the HDCP stuff is open for example. But we need the scheduler and the memory hierarchy management to be open. This is what it takes to push the performance of neural networks. The Groq 500 T/s mixtral demo should be possible on a tinybox, but it requires god tier software and deep integration with the scheduler. We also advised that the build process for amdgpu-dkms should be more open. While the driver itself is open, we haven't found it easy to rebuild and install. Easy REPL cycle is a key driver for community open source. We want the firmware to be easy to rebuild and install also." Prior to this week's co-operations, Tiny Corp. hinted that it could move on from utilizing Radeon RX 7900 XTX, in favor of Intel Alchemist graphics hardware—if AMD's decision making does not favor them, Hotz & Co. could pivot to builds including Acer Predator BiFrost Arc A770 16 GB OC cards.



Subsequently, Hotz documented his interactions with Team Red representatives—he expressed 70% confidence in AMD approving open-sourcing certain bits of firmware in a week's time: "Call went pretty well. We are gating the commitment to 6x Radeon RX 7900 XTX on a public release of a roadmap to get the firmware open source. (and obviously the MLPerf training bug being fixed). We aren't open source purists, it doesn't matter to us if the HDCP stuff is open for example. But we need the scheduler and the memory hierarchy management to be open. This is what it takes to push the performance of neural networks. The Groq 500 T/s mixtral demo should be possible on a tinybox, but it requires god tier software and deep integration with the scheduler. We also advised that the build process for amdgpu-dkms should be more open. While the driver itself is open, we haven't found it easy to rebuild and install. Easy REPL cycle is a key driver for community open source. We want the firmware to be easy to rebuild and install also." Prior to this week's co-operations, Tiny Corp. hinted that it could move on from utilizing Radeon RX 7900 XTX, in favor of Intel Alchemist graphics hardware—if AMD's decision making does not favor them, Hotz & Co. could pivot to builds including Acer Predator BiFrost Arc A770 16 GB OC cards.