 50
50
AMD Ryzen Threadripper 3rd Gen Overclocking Deep Dive, feat. ASUS ROG Zenith II Extreme
Test System »Memory Overclocking on Threadripper
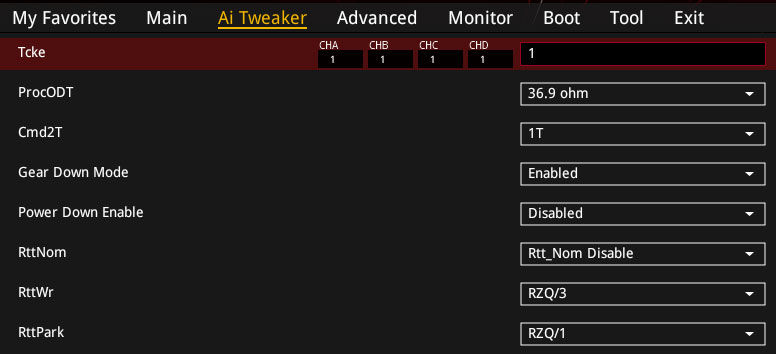
While overclocking memory on third-generation Threadrippers, I discovered some interesting characteristics I haven't seen mentioned online yet. AMD modified procODT (on any motherboard), for which the optimal range now is 28–36.9 Ω for single-rank memory and 36.9–53.3 Ω for dual-rank memory. This led to greatly improved overclocking, and users can now get up to 4600 MHz on most top boards.

RTT values remained the same, and I suggest leaving RTT_NOM disabled if you have four modules in the system (two for desktop Ryzen) and RZQ / 7 (34 Ω) for configurations with eight modules (four for desktop Ryzen). RTT_WR in RZQ / 3 (80 Ω) or RZQ / 2 (120 Ω) + RTT_PARK in RZQ / 1 (240 Ω) mode is what I'm recommending only with dual-rank memory or four single-rank memory modules for AM4, or eight single rank modules for HEDT. In other cases, set RTT_WR Dynamic ODT off + RTT_PARK RZQ / 5 (48 Ω).
The CAD_BUS has undergone some changes for this platform. The best values are now 24-20-20-24 instead of the standard 24-24-24-24. In most cases, this setting can significantly improve the stability of the system. Also, increasing the CAD_BUS ClkDrvStren value to 30 or 40, or even 60, will positively affect the stability of the system in which GearDown Mode (GDM) is disabled or when 4/8 RAM modules are installed. A value of 120 will be useful for disabling GDM on systems where dual-rank modules are used. I want to note that this is not a recommendation from AMD, but my own, and I truly hope that such overclocking rules will be introduced in the next AGESA update.

"Zen 2" also introduced a new voltage setting called CLDO_VDDG. CLDO as part of VDDG means that a dropout stabilizer is used for the voltage (LDO means "low dropout level"). VDDG is the Infinity Fabric (IF) voltage, which, as you might have guessed, is responsible for the integrity of the data moving through IF. It exists for the stabilization of high frequencies of FCLK. In recent AGESA, CLDO_VDDG was split into two settings: VDDG CCD and VDDG IOD. The first is responsible for Infinity Fabric links between the two CCX on each CCD, and the second parameter is responsible for the long-range IFOP link between IO Die and CCD. Since CLDO_VDDG and CLDO_VDDP are regulated from the VDDCR_SoC plane, there is a rule for setting VDDG. The SoC voltage should be higher than requested by VDDG. By default, it is 0.950 V; however, some motherboards may exceed the default level even with standard settings and may even cause a boot failure due to excessive voltage.
My recommendation is to use a manual VDDG with a value of 0.95 V (enough to overclock FCLK to 1800 MHz) or keep a 0.05 V gap between it and SoC. The safe limit for VDDG is up to and including 1.1 V. CLDO_VDDP. I advise you to not touch it at all, as 0.9 V is a wonderful number that allows you to train your memory at frequencies of 2133–4333 MHz. The "Memory Holes" were not found in my samples. I also did not notice a decreased appetite for DRAM voltage. Timings are clamped in the same way, without any surprises, because you can easily use configurations from the previous BIOS revisions and AGESA microcodes.
Let us now talk about 2:1 and 1:1 modes (MEMCLK : UCLK). In order to stabilize Infinity Fabric, the system automatically switches to 2:1 mode as soon as the DRAM frequency exceeds 3600 MHz, if the FCLK frequency isn't coupled with it. In other words, when RAM is overclocked above 3600 MHz, users must simultaneously increase the FCLK frequency to keep the RAM and IF synchronized, which will allow them to stay in 1:1 mode for the best performance with even higher RAM frequencies. Infinity Fabric and RAM will otherwise decouple, which happens when the FCLK frequency is left at "Auto".
It is normal for a cold boot to occur when switching between 2:1 and 1:1 mode; it will happen because the modes use either the processor clock generator or processor and motherboard clock generators (not all motherboards have an external BCLK clock, so keep that in mind). The second nuance is that "07" on the POST code display means that the FCLK limit has been reached for one reason or another and that increasing the VDDG voltage simply will not give a better result. In particular, the high voltage at VDDG_CCD will only be useful when using liquid nitrogen for extreme overclocking.
Overclocking FCLK is limited by the IO die chip bin. 1866–1900 MHz is the maximum most users can get, although there were a couple of samples that could reach 1966 MHz. With BCLK adjustments, I was able to find a critical point when the system stops booting even if I significantly increased SoC or VDDG, which was 1889 MHz for my Threadripper 3690X. I also came across a situation in which the AM4 Ryzen 3700X did not have stability at even 1866 MHz. There was a problem in games that manifested itself as screen flicker. Voltage adjustments on VDDG CCD and VDDG IOD did not change the situation. If we talk about my IOD instance, it turned out to be an excellent bin, a frequency of 3733 MHz for 8 modules was easily achieved on the ASUS ROG Zenith II Extreme at SOC 1.025 V and 0.95 V VDDG. However, at 3800 MHz, the system refused to start.

39% less latency between the farthest CCDs is another reason why you should consider overclocking/optimizing your system. By the way, note that when overclocking FCLK in the case of the AMD Ryzen Threadripper 3690X, throughput did not increase; it even had a negative impact.

Such a phenomenon can be an indication of AMD throttling the Infinity Fabric. For example, with every 10th or 20th clock (even a series of clocks could be idle clocks), when information is not received or transmitted. It might be a way to get rid of the noise on long-range links or an artificial limitation, the removal of which will be presented as an innovation in Zen 3—higher interconnect bandwidth leading to higher processor performance. Nevertheless, at the moment, we have losses for small-block operations, which certainly affects performance.

Also, FCLK overclocking has a positive effect on L3 cache access time. A minor drawback of the Zen 2 architecture is its L3 cache, which is not a monolithic block of cache on the chiplet. CCX1 core access to the L3 CCX2 cache incurs an additional delay due to the delay in accessing Infinity Fabric. Remember that CCX1 can even access L3 in CCX8, in which case L3 cache access time is only slightly less than DRAM access time. Fortunately, in Zen 3, users will get eight cores per CCD and a monolithic L3 cache, which will certainly improve raw performance.

As for the reduced write bandwidth between CCD and IOD (writing 16 bytes per clock and 32 bytes per clock for reads), I did not see a significant drawback. Only applications that require very high memory write bandwidth can lose a little bit of performance. In games, write speed is not very important, so the performance drop isn't observed. In any case, the x86 core has a read/write ratio of 2:1, and many new instructions even have a 3:1 ratio.
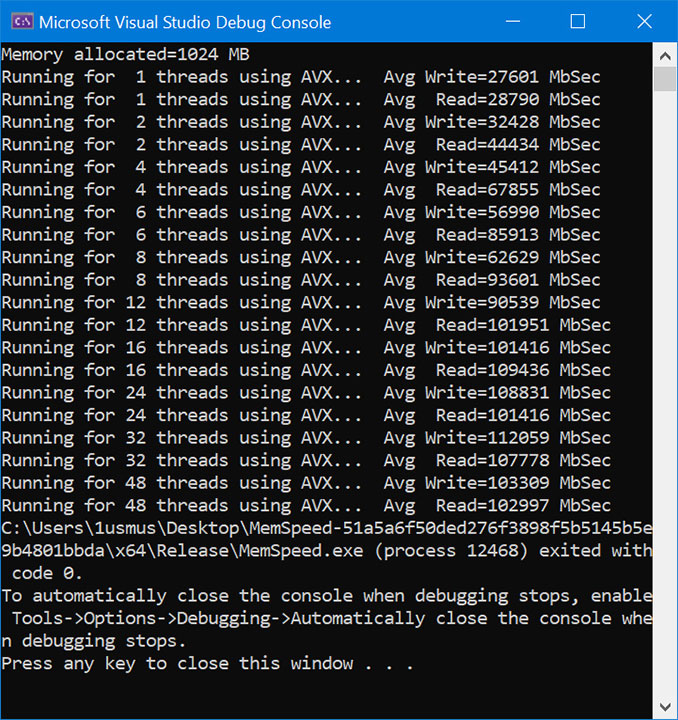
Of course, it's interesting to measure the bandwidth of reading and writing RAM for a different number of threads. The results show that one thread does not have access to two channels at once, although this is nothing special as all Intel solutions exhibit similar behavior.

The last interesting parameter is PMU Pattern Bits, an option that can affect memory training and the stability of the system as a whole. Recommended values are 6–10, and the greater the value, the more effectively will the training system work. Accordingly, system start-up will take longer, so you'll stare at a blank screen for longer, and what about four ranks on two channels? Most of my tests didn't react at all to doubling the amount of memory and ranks; I only saw a difference with the compilation of the Unreal Engine 4 game engine, which was most likely because the pagefile was used less.
Jul 1st, 2025 03:19 CDT
change timezone
Latest GPU Drivers
New Forum Posts
- Recommend me a decent budget card :) (16)
- Will you buy a RTX 5090? (585)
- Do you use Linux? (666)
- Super-slow WiFi (2)
- R-T-B's PNY RTX 5080 OC Photo sideshow. (1)
- Question about Intel Optane SSDs (88)
- The Official Thermal Interface Material thread (1756)
- Your PC ATM (35476)
- Help with a gtx1050 mxm (1)
- [Request] GTX 1650 mobile DEV_1F99 SUBSYS_143E1025 VBIOS firmware (0)
Popular Reviews
- ASUS ROG Crosshair X870E Extreme Review
- Sapphire Radeon RX 9060 XT Pulse OC 16 GB Review - An Excellent Choice
- AVerMedia CamStream 4K Review
- Lexar NQ780 4 TB Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Upcoming Hardware Launches 2025 (Updated May 2025)
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- AMD Ryzen 9 9950X3D Review - Great for Gaming and Productivity
- NVIDIA GeForce RTX 5060 8 GB Review
- Intel Core Ultra 7 265K Review
TPU on YouTube
Controversial News Posts
- Intel's Core Ultra 7 265K and 265KF CPUs Dip Below $250 (288)
- NVIDIA Grabs Market Share, AMD Loses Ground, and Intel Disappears in Latest dGPU Update (204)
- Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming (140)
- Microsoft Partners with AMD for Next-gen Xbox Hardware (105)
- NVIDIA Launches GeForce RTX 5050 for Desktops and Laptops, Starts at $249 (105)
- Intel "Nova Lake‑S" Series: Seven SKUs, Up to 52 Cores and 150 W TDP (100)
- NVIDIA GeForce RTX 5080 SUPER Could Feature 24 GB Memory, Increased Power Limits (97)
- Reviewers Bemused by Restrictive Sampling of RX 9060 XT 8 GB Cards (88)