 128
128
ASUS Radeon RX 7900 XTX TUF OC Review - Amazing Overclocking
Pictures & Teardown »AMD RDNA 3 Graphics Architecture
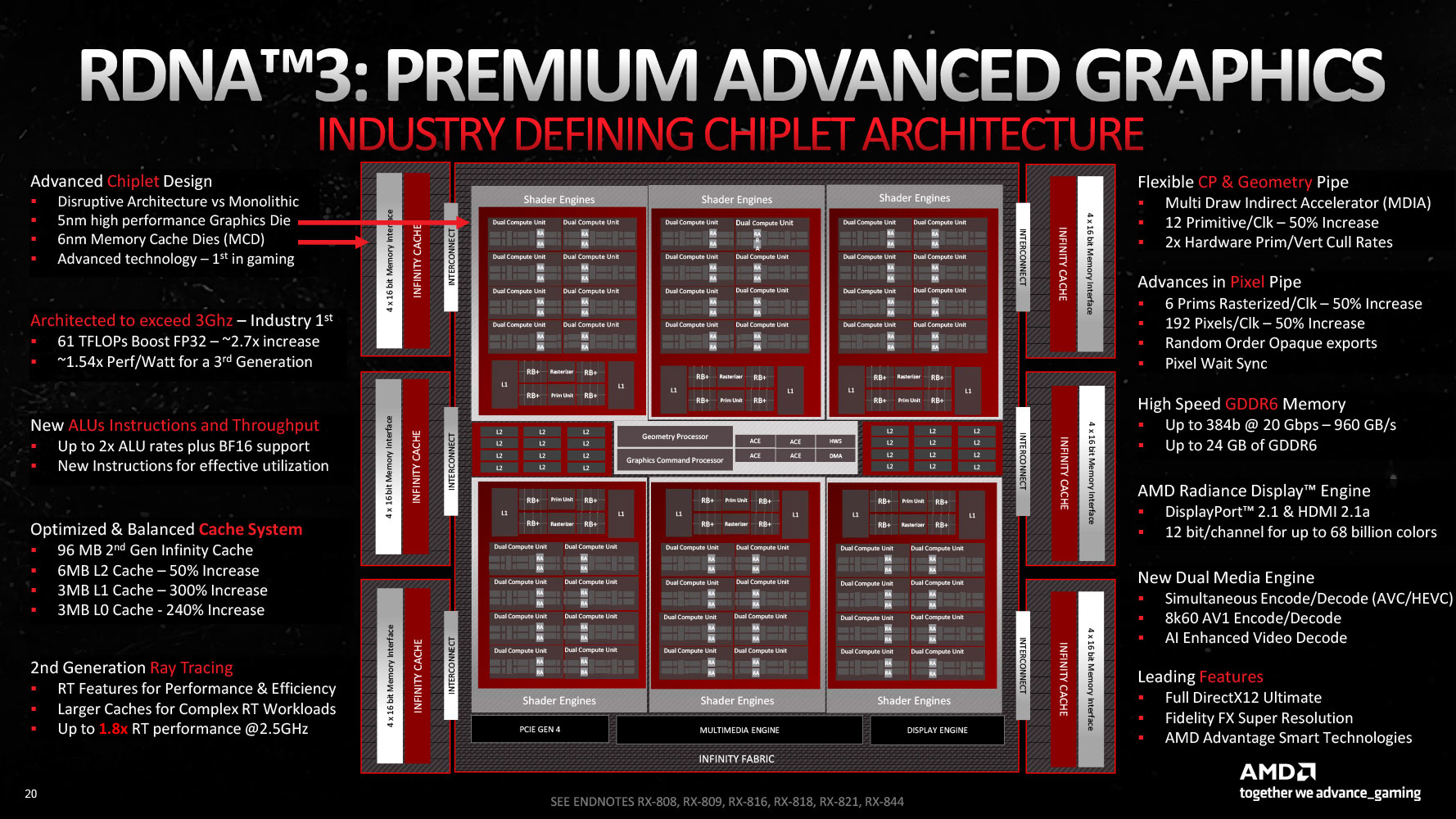

The Radeon RX 7900 XTX and RX 7900 XT debut AMD's 3rd generation RDNA graphics architecture, termed RDNA 3. With it, AMD plans to repeat the generational 50% performance/Watt gain it achieved with RDNA 2, which sprung it back to the high-end graphics segment after a long gap. AMD claims it succeeded in this endeavor, with a 54% generational performance/Watt gain. At the heart of this effort is the switch to the new TSMC 5 nm EUV foundry node. AMD figured out early on that it cannot build large monolithic GPUs on 5 nm without thinning its margins in the fight against NVIDIA, and set out to innovate the Chiplet architecture for the GPU. Under this, specific parts of the GPU that actually benefit from a switch to a newer foundry node, such as the Shader Engines, would be built on a centralized 5 nm die called the Graphics Compute Die (GCD), while those components that can make do with a less advanced node, namely the memory controllers and L3 cache, would be spun off to chiplets called Memory Cache Dies (MCDs), built on 6 nm.


The "Navi 31" GPU is hence a chiplet GPU and not a multi-chip module like "Vega 10." In a chiplet-based device, various components that can otherwise not exist on their own packages, are placed on a single package, with the goal of minimizing production costs, by stratifying their need for a new foundry node, such that only the most power-intensive IP receive the most advanced node. In a MCM, chips that can otherwise exist on their own package, are combined onto a single package for conserving PCB real-estate, or reducing latency. The GCD in the "Navi 31" GPU hence has all the shader engines, caches up to L2, the front-end Command Processor, Async Compute Engines (ACEs), the Display Engine, and the Media Engine. Each of the six MCDs has a 64-bit wide memory bus, and a 16 MB segment of the GPU's 96 MB Infinity Cache memory. The size of the Infinity Cache may have been generationally reduced (compared to 128 MB on "Navi 21"), but AMD has widened the memory bus itself, from 256-bit up to 384-bit.
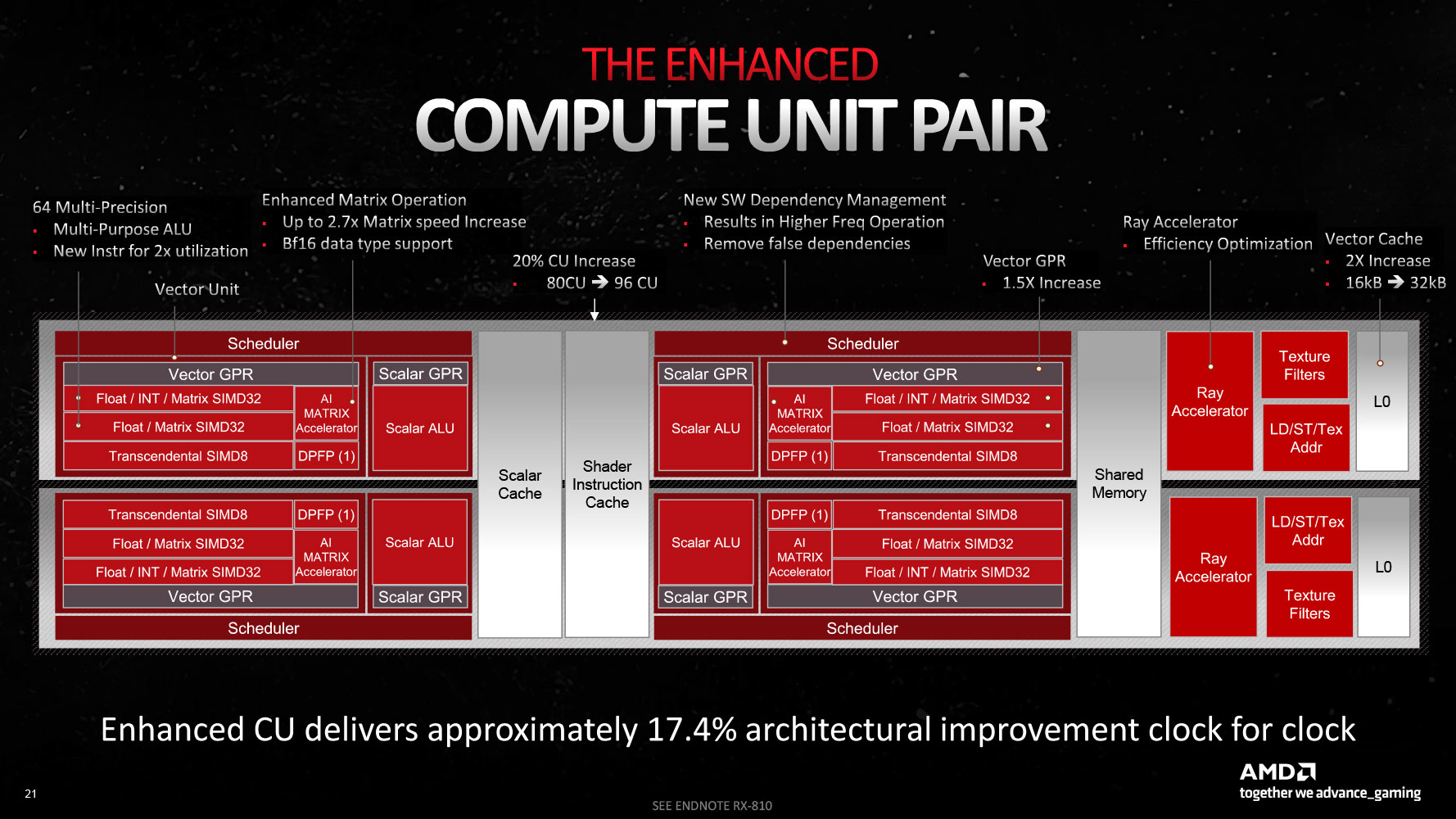

Much of the architectural innovation is not with the chiplet design (a packaging innovation); but at the level of the RDNA 3 Dual-Compute Unit (or Compute Unit pair). The "Navi 31" GPU physically features 96 compute units spread across six Shader Engines. AMD claims that at the same engine clocks, the RDNA 3 CU offers a 17.4% IPC increase over the RDNA 2 CU. There are 20% more CUs over the "Navi 21," and these run at higher engine clocks, tapping into the power headroom afforded by the 5 nm process. These combined work out to the 54% generational performance uplift, with which AMD plans to retain competitiveness with NVIDIA's RTX 40-series "Ada" high-end SKUs.
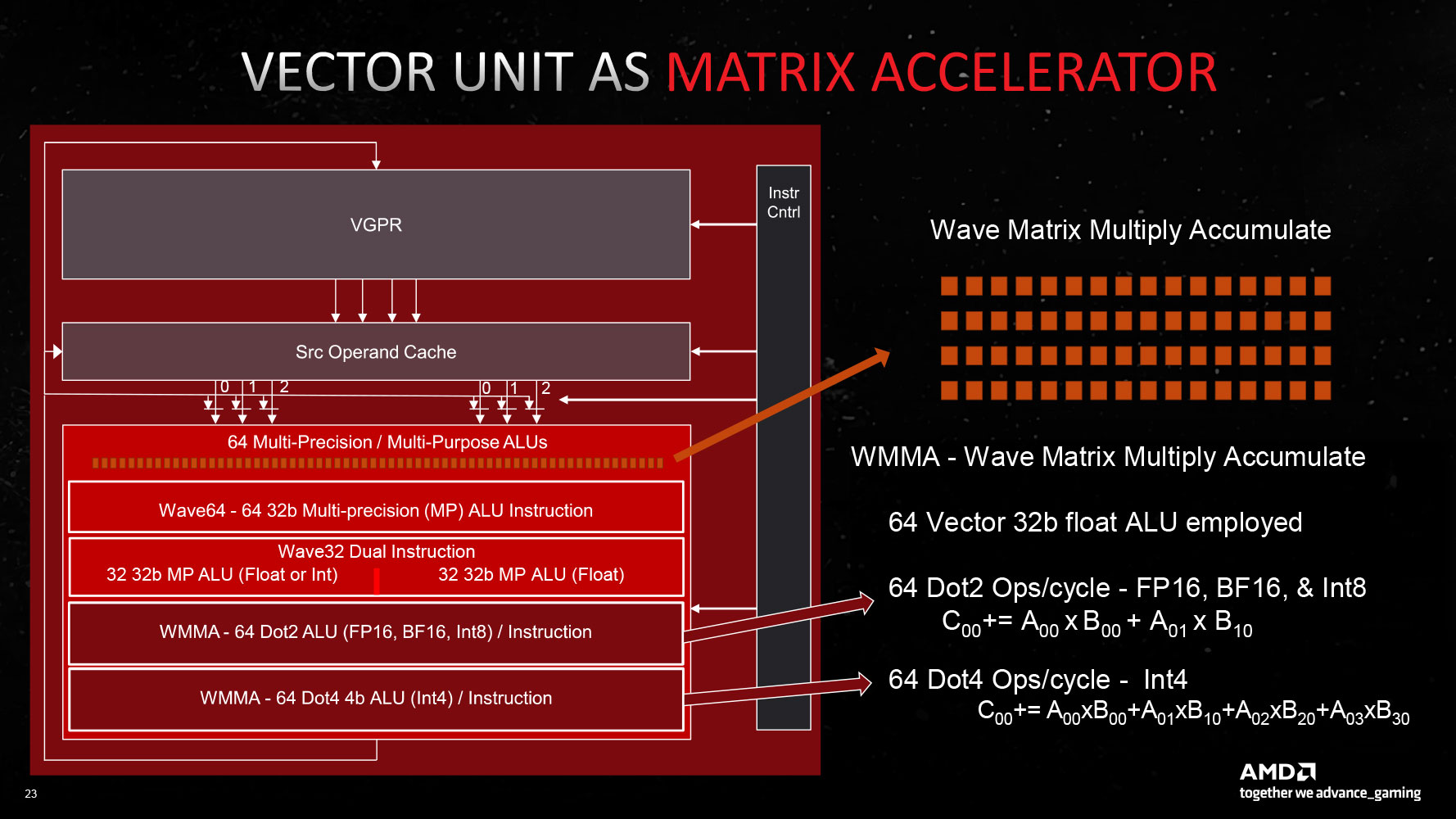
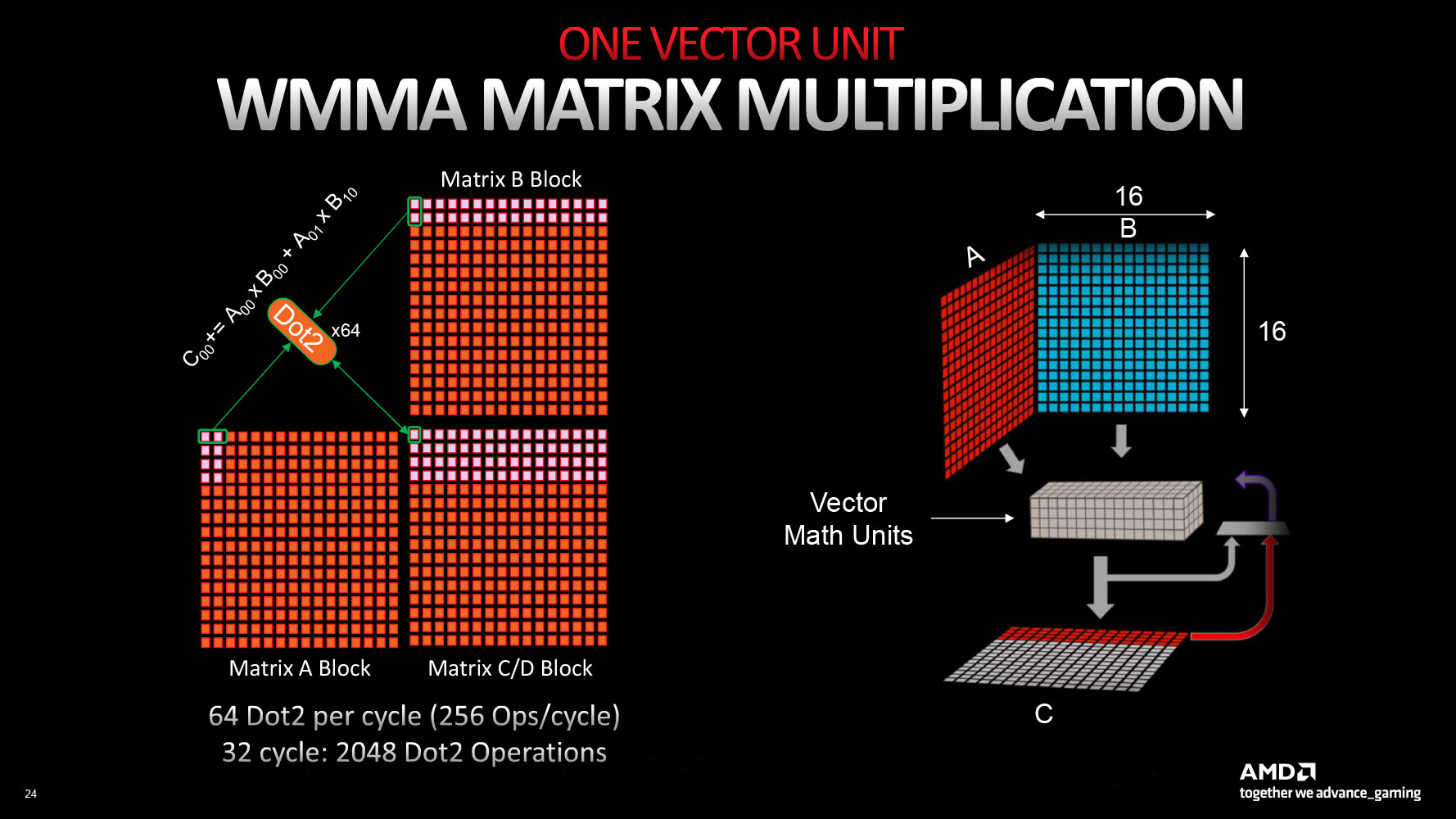
The new RDNA 3 CU introduces multi-precision capability for the 64 stream processors per CU: operating either as 1x SIMD64 or 2x SIMD32 units. The Vector Unit that houses these SIMD units can either function as a SIMD execution mechanism, or as a Matrix execution unit, thanks to the new AI Matrix Accelerator, which provides a 2.7x matrix multiplication performance uplift versus conventional SIMD execution. Also added are support for the Bfloat16 instruction-set, and SIMD8 execution. The GPU hence enjoys AI hardware-acceleration that can be leveraged in future feature-additions relevant to gamers, such as FSR 3.0. Game developers will also look for ways to exploit accelerated AI, now that all three brands feature it (NVIDIA Tensor cores and Intel XMX cores).


AMD's first-generation Ray Accelerator, introduced with the RDNA 2 architecture, was the result of a hasty effort to catch up to NVIDIA with a DirectX 12 Ultimate GPU, where they developed a fixed-function hardware to calculate ray intersections, and offloaded a large chunk of RT processing to the generationally-doubled SIMD resources. With RDNA 3, they've refined the Ray Accelerator to achieve an 80% ray tracing performance uplift over the previous generation, when you add up the Ray Accelerator count, their higher engine clocks, and other hardware-level optimizations, such as early sub-tree culling, specialized box sorting modes, and reduced traversal iterations.


There is a 50% ray intersection capacity improvement for the "Navi 31" GPU thanks to these optimizations, and cycles-per-ray reduction. Besides these, AMD has also made several improvements to the geometry- and pixel-pipes, with the introduction of the new multi-draw indirect accelerator (MDIA), which reduces CPU API and driver-level overheads by gathering and parsing multi-draw command data. At the hardware-level 12 primitives per clock is now supported compared to 8 per clock on RDNA 2, thanks to culling. The core-configuration overall enables 50% more rasterized performance per clock.
The GCD features six Shader Engines, each with 16 compute units (or 8 dual compute units), which work out to 1,024 stream processors. Six such Shader Engines make up 6,144 stream processors with 96 Ray Accelerators and 96 AI Accelerators. The GPU has 384 TMUs, and a massive 192 ROPs—a 50% increase over "Navi 21." The Radeon RX 7900 XTX enables all 96 CUs, and maxes out the silicon, whereas the RX 7900 XT has 84 out of 96 CUs enabled, which work out to 5,376 stream processors, 84 Ray Accelerators, 336 TMUs, and an unchanged 192 ROPs. The RX 7900 XTX gets 24 GB of GDDR6 memory across the GPU's entire 384-bit memory bus, with a memory speed of 20 Gbps (GDDR6-effective), translating to 960 GB/s of memory bandwidth. The RX 7900 XT is equipped with 20 GB of memory across a narrower 320-bit memory bus carved out by disabling one of the six MCDs. At the same 20 Gbps speed, this yields 800 GB/s bandwidth.


AMD has significantly improved the Display Engine of "Navi 31" over the previous-generation in terms of connectivity. The new Radiance Display Engine comes with native support for DisplayPort 2.1, which enables 8K output at up to 165 Hz refresh-rate, or 4K at up to 480 Hz, with a single cable. AMD has refined its FSR 2 algorithm to support 8K (i.e. render at a lower resolution with FSR-enhanced upscaling), to make it possible to enjoy the latest AAA titles at playable frame-rates on 8K displays. Both the RX 7900 series cards get two full-size DP 2.1 connectors, besides an HDMI 2.1b, and a USB-C with DP 1.2 passthrough. The "Navi 31" silicon receives full hardware-accelerated AV1 encode and decode capabilities, through dual independent encode/decoders, so two independent video streams can be simultaneously transcoded, or one stream at twice the framerate. With this generation, AMD is also introducing SmartAccess Video, a feature that lets the AMD driver leverage the hardware encoders of the RDNA 2 iGPU of Ryzen 7000 desktop processors, for additional encoding performance.
Jul 5th, 2025 23:21 CDT
change timezone
Latest GPU Drivers
New Forum Posts
- Help Watercooling my PC (8)
- Will you buy a RTX 5090? (627)
- RX 9000 series GPU Owners Club (1128)
- 9800x3d temps (3)
- Last game you purchased? (862)
- TPU's Rosetta Milestones and Daily Pie Thread (2375)
- What are you playing? (23897)
- Folding Pie and Milestones!! (9607)
- Do you game on a handheld console? (98)
- TPU's Nostalgic Hardware Club (20486)
Popular Reviews
- NVIDIA GeForce RTX 5050 8 GB Review
- Fractal Design Scape Review - Debut Done Right
- Crucial T710 2 TB Review - Record-Breaking Gen 5
- ASUS ROG Crosshair X870E Extreme Review
- Sapphire Radeon RX 9060 XT Pulse OC 16 GB Review - An Excellent Choice
- PowerColor ALPHYN AM10 Review
- Upcoming Hardware Launches 2025 (Updated May 2025)
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- NVIDIA GeForce RTX 5060 8 GB Review
TPU on YouTube
Controversial News Posts
- Intel's Core Ultra 7 265K and 265KF CPUs Dip Below $250 (288)
- NVIDIA Grabs Market Share, AMD Loses Ground, and Intel Disappears in Latest dGPU Update (212)
- Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming (140)
- NVIDIA GeForce RTX 5080 SUPER Could Feature 24 GB Memory, Increased Power Limits (115)
- Microsoft Partners with AMD for Next-gen Xbox Hardware (105)
- NVIDIA Launches GeForce RTX 5050 for Desktops and Laptops, Starts at $249 (105)
- AMD Radeon RX 9070 XT Gains 9% Performance at 1440p with Latest Driver, Beats RTX 5070 Ti (102)
- Intel "Nova Lake‑S" Series: Seven SKUs, Up to 52 Cores and 150 W TDP (100)