 0
0
MSI GeForce GTX 1660 Gaming X 6 GB Review
Packaging & Contents »Architecture

The GeForce GTX 1660 is based on the same 12 nm "TU116" silicon as the GTX 1660 Ti launched last month. NVIDIA has carved out the GTX 1660 by disabling two out of 24 streaming multiprocessors (SMs), and pairing the GPU with 8 Gbps GDDR5 memory instead of 12 Gbps GDDR6. Memory bus width itself is unchanged at 192-bit wide, but the switch to GDDR5 has reduced memory bandwidth by a third (192 GB/s vs. 288 GB/s). GPU clock speeds are negligibly increased if not largely the same with 1530 MHz base and 1785 MHz GPU Boost, compared to the 1500/1770 MHz of the GTX 1660 Ti.
NVIDIA has significantly re-engineered the Graphics Processing Clusters (GPCs) of the silicon to lack RT cores and tensor cores. The chip's hierarchy is similar to other "Turing" GPUs. The GigaThread Engine and L2 cache are town-square for the GPU, which bind three GPCs with the chip's PCI-Express 3.0 x16 host and 192-bit GDDR5 memory interfaces. Each GPC has four indivisible TPCs (Texture Processing Cluster) that share a Polymorph Engine between two streaming multiprocessors (SM). Each Turing SM packs 64 CUDA cores, and thus, we end up with 128 CUDA cores per TPC, 512 per GPC, and 1,536 across the silicon. On the GTX 1660, there are 22 out of 24 SMs (or 11 out of 12 TPCs) enabled, which results in 1,408 CUDA cores. This is still more than the 1,280 of the GTX 1060 6 GB, and one has to also consider the increased IPC of the "Turing" architecture.

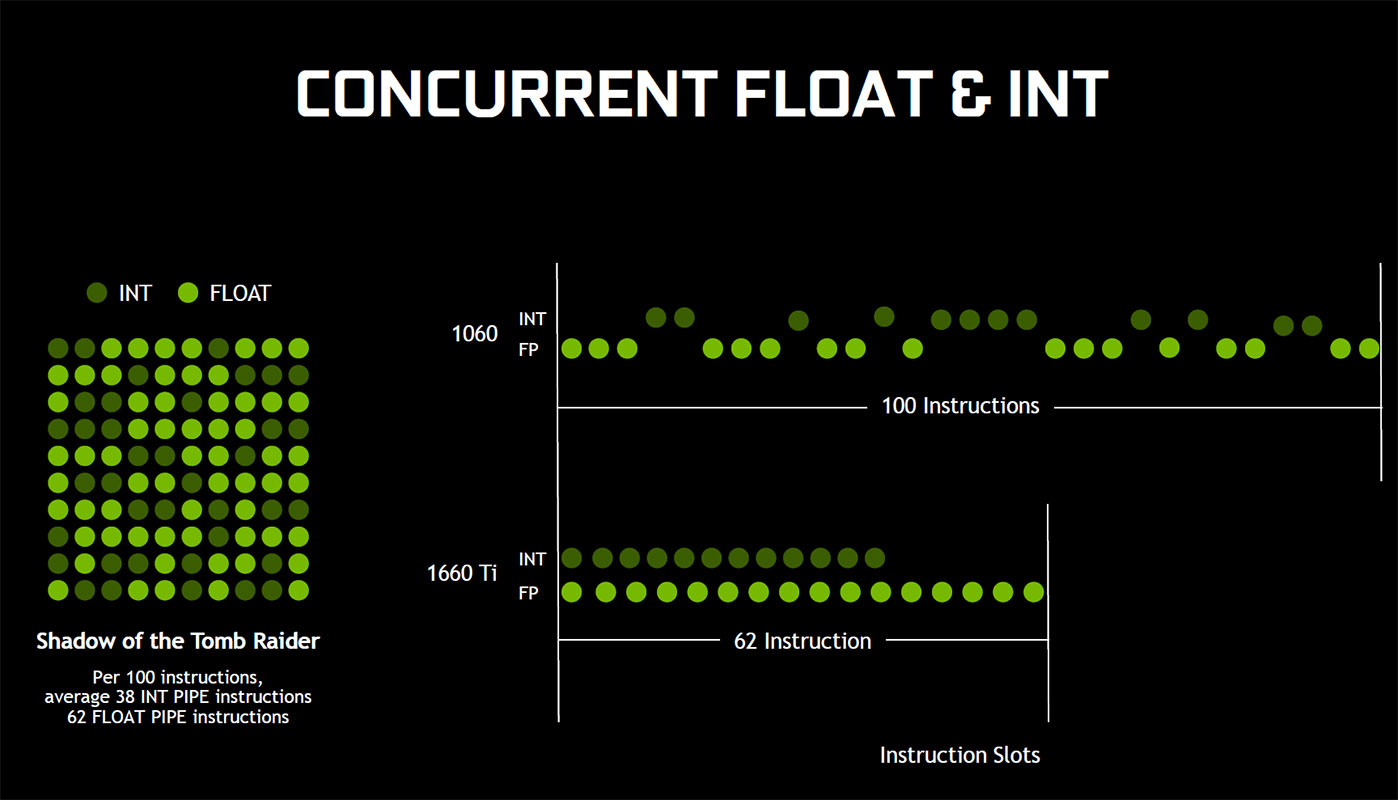
Much of NVIDIA's CUDA core specific innovation for Turing centers on improving the architecture's concurrent-execution capabilities. This is not the same as asynchronous compute, but the two concepts aren't too far out from each other. Turing CUDA cores are designed to execute integer and floating-point instructions per clock cycle in parallel, while older architectures, such as Pascal, can only handle one kind of execution at a time. Asynchronous compute is more of a macro concept and concerns the GPU's ability to handle various graphics and compute workloads in tandem.

Cushioning the CUDA cores is an improved L1 cache subsystem. The L1 caches are enlarged three-fold, with a four-fold increase in load/store bandwidth. The caches are configurable on the fly as either two 32 KB partitions per SM or a unified 64 KB block per TPC. NVIDIA has also substituted tensor cores with dedicated FP16 cores per SM to execute FP16 operations. These are physically separate components to the 64 FP32 and 64 INT32 cores per SM and execute FP16 at double the speed of FP32 cores. On the RTX 2060, for example, there are no dedicated FP16 cores per SM, and the tensor cores are configured to handle FP16 ops at an enormous rate.
NVIDIA has deployed the older generation GDDR5 memory on the GTX 1660, clocked at 8 Gbps data rate compared to 12 Gbps GDDR6 on the GTX 1660 Ti. This is a massive 33 percent decrease in memory bandwidth compared to the GTX 1660 Ti and exactly the same as on the GTX 1060 6 GB. The memory amount is unchanged at 6 GB.
Features



Let's talk about the two elephants in the room first. The GTX 1660 will not give you real-time raytracing because it lacks RT cores, and won't give you DLSS for want of tensor cores. What you will get is Variable Rate Shading. The Adaptive Shading (aka variable-rate shading) feature introduced with Turing is carried over to the GTX 1660. Both its key algorithms, content-adaptive shading (CAS) and motion-adaptive shading (MAS), are available. CAS senses color or spatial coherence in scenes to minimize repetitive shading of details in pursuit of increasing detail where it matters. MAS senses high motion in a scene (e.g.: race simulators) and minimizes shading of details in favor of performance.
Jul 5th, 2025 13:47 CDT
change timezone
Latest GPU Drivers
New Forum Posts
- Are there others on TPU with a dual system (two pc´s in one case)? (12)
- FINAL FANTASY XIV: Dawntrail Official Benchmark (196)
- Help Watercooling my PC (1)
- TPU's Nostalgic Hardware Club (20484)
- How do you view TPU & the internet in general? (With poll) (71)
- GravityMark v1.89 GPU Benchmark (310)
- Optane performance on AMD vs Intel (57)
- EVGA XC GTX 1660 Ti 8GB ROM (8)
- TPU's Rosetta Milestones and Daily Pie Thread (2374)
- Have you got pie today? (16775)
Popular Reviews
- NVIDIA GeForce RTX 5050 8 GB Review
- Fractal Design Scape Review - Debut Done Right
- Crucial T710 2 TB Review - Record-Breaking Gen 5
- ASUS ROG Crosshair X870E Extreme Review
- PowerColor ALPHYN AM10 Review
- Sapphire Radeon RX 9060 XT Pulse OC 16 GB Review - An Excellent Choice
- Upcoming Hardware Launches 2025 (Updated May 2025)
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- NVIDIA GeForce RTX 5060 8 GB Review
TPU on YouTube
Controversial News Posts
- Intel's Core Ultra 7 265K and 265KF CPUs Dip Below $250 (288)
- NVIDIA Grabs Market Share, AMD Loses Ground, and Intel Disappears in Latest dGPU Update (212)
- Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming (140)
- NVIDIA GeForce RTX 5080 SUPER Could Feature 24 GB Memory, Increased Power Limits (115)
- NVIDIA Launches GeForce RTX 5050 for Desktops and Laptops, Starts at $249 (105)
- Microsoft Partners with AMD for Next-gen Xbox Hardware (105)
- AMD Radeon RX 9070 XT Gains 9% Performance at 1440p with Latest Driver, Beats RTX 5070 Ti (102)
- Intel "Nova Lake‑S" Series: Seven SKUs, Up to 52 Cores and 150 W TDP (100)