Tuesday, April 10th 2012

Trinity (Piledriver) Integer/FP Performance Higher Than Bulldozer, Clock-for-Clock
AMD's upcoming "Trinity" family of desktop and mobile accelerated processing units (APUs) will use up to four x86-64 cores based on the company's newest CPU architecture, codenamed "Piledriver". AMD conservatively estimated performance/clock improvements over current-generation "Bulldozer" architecture, with Piledriver. Citavia put next-generation A10-5800K, and A8-4500M "Trinity" desktop and notebook APUs, and pitted them against several currently-launched processors, from both AMD and Intel.
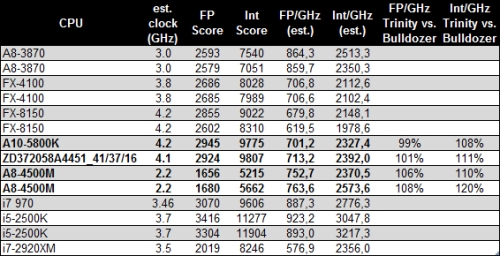
It found integer and floating-point performance increases clock-for-clock, against Bulldozer-based FX-8150. The benchmark is not multi-threaded, and hence gives us a fair idea of the per core performance. On a rather disturbing note, the performance-per-GHz figures of Piledriver are trailing far behind K12 architecture (Llano, A8-3850), let alone competitive architectures from Intel.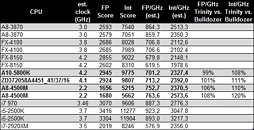
Source:
Expreview
It found integer and floating-point performance increases clock-for-clock, against Bulldozer-based FX-8150. The benchmark is not multi-threaded, and hence gives us a fair idea of the per core performance. On a rather disturbing note, the performance-per-GHz figures of Piledriver are trailing far behind K12 architecture (Llano, A8-3850), let alone competitive architectures from Intel.
115 Comments on Trinity (Piledriver) Integer/FP Performance Higher Than Bulldozer, Clock-for-Clock
i cant wait for the ins and outs of whats going on to be known in a few / year ,what will the ps3 and nextbox have etc.
im looking forward to a promising Vishera, not an awe inspireing one but id imagine with the new clock mesh tech these Apu's will OC a fair bit, given a reasonable Vreg which is only going to be on the Fm2 Platform not soo much laptops but in that form i can well imagine a modern day console type gameing experience on most pc games, maybe better/ deff better then an xbox360 game , and i can see it running well with an OC.
and with L3 ,more modules/cores and a (important)later possible stepping vishera could end up doing well, I only back Amd at any point due to the fact some are OT given i get 60-80Fps in any game on ultra(addmitedly with hybrid physx for the nv favoured games) with my main rig , an intel system may well do much better but My experience isnt as bad as some of you are making out i dont notice any wait times and these chips are going to perform better then my main rig does at min or should
from leaks it seems piledriver is 20% than bulldozer clock-clock so it almost finaly matches phenom II ipc, but offcourse clocks much higher.
once again the phenom/phenom II story going on, with piledriver being what bulldozer was meant to be(and some... or hopefully atleast)
Phenom II is not 20% faster than Bulldozer clock for clock. It's ridiculous to think that. Obviously its application dependant, but on a good day when an application favours Phenom II's architecture we are talking about maybe 5% or less or within margin for error. Overall the Bulldozer is faster.
Also all of those tasks that do better on the P2 are single threaded tasks and unoptimized floating point applications and even in both of these cases, the performance is acceptable.
So depending on pricing and the clocks for the lower end chips, Trinity may be fully competitive thanks to it's higher clocks and superior iGPU, especially with IB i3/pentium not coming out till Q3/Q4 and trinity coming out late Q1, early Q2.
And if the earlier rumor of power efficiency is true as well, with it being 15% more power efficient than llano, and given BD OC'd rather decently, the unlocked parts I feel based on what information we currently have available to us at the moment show a great budget part.
Although it is still merely speculation until Wiz gets to do a review.
They directly compare the FP performance per clock, and the A8 series is raping the A10 and bulldozer if the chart is real.
In other words, AMD may have done nothing but tweaked the core a bit to conserve energy and increase the speed. All joking aside this new architecture is the P4 from AMD.
I keep thinking and saying their only saving grace will be GCN added to a quad core and software enhancement to offload the work to the much faster GPU, however I think they lack the manpower and drive to do it. So I am expecting mediocrity from their next chip after this too. Once they push for it, or pull back to a tweaked for efficency design they have a chance to gain the performance edge.
AMD, please, make software to support your hardware, Intel did it for years, programs would see a Intel chip and optimize performance, you can do it too. I would rather have two cores dedicated to serving data to a on bard GPU with enough stream processors and cache to run full tilt than have 8 cores total. Or do it in hardware, surely 10% die area is worth a exponential increase in performance.
Why do I keep mentioning the iGPU? Because AMD's long term plan is HSA, and dumping floating point math onto the iGPU. And HSA functions -should- be available next year, with 22nm steamroller + GCN (expected to be possibly a 7750-equivalent) on die.
Oh, and earlier possible leaks show Trinity to be more power efficient than Llano as well.
Also @ genocide, 20% lower performance / clock and 10% lower performance / watt = shit? I see it as being less efficient and powerful, but it's not like it is only half as powerful. (and I'm saying that based on the slide btw. Given the A10 is a 100w part that is really a 95w CPU + GPU + 5w bridge chip and all. Bulldozer was something of a fail, Piledriver isn't looking to be quite as bad.
I have to agree on the appearance of a Phenom I / II again here.
So first you say the way is multi-core, and now you say they shouldn't prepare for multi-core systems? This makes no sense, if we are moving to a multi-core standard (we are) we need to have hardware/software resources to support it, and if developers aren't going to do it, AMD needs to.
I'd be happy to read a review which shows that claim. If anyone has external reading material feel free to post it.
only in situations were new instructions sets are supported does bulldozer hold ground,p but in typical use its way behind clock-clock, and yes by 20% if not more
phenom II does 3ipc while bulldozer does 4ipc shared between 2 cores, and because it has such a long pipeline each cycle takes a longer time(which isnt bad because its kinda designed that way so the resources can feed the second core in the module while the first one is munching on data)but things didnt go so well and the latency is worse than expected
www.legitreviews.com/article/1766/17/
heres some of conclusion from legitreview, i wasnt talking out of my ass just so you know
"When it comes to performance we were shocked to see the AMD A8-3850 'Llano' processor and the Socket FM1 platform performing better than the AMD FX-4100 'Bulldozer' processor and the Socket AM3+ platform. We quickly found out that the FX-4100 was priced this low as it needed to be. The performance of the FX-4100 wasn't awful, but we didn't expect to see the AMD A6-3650 running at 2.6GHz to beat the AMD FX-4100 running at 3.6GHz in benchmarks like POV-Ray and Cinebench! "
www.google.com/url?sa=t&rct=j&q=multicore%20performance%20analysis%20gain&source=web&cd=7&ved=0CFsQFjAG&url=http%3A%2F%2Fciteseerx.ist.psu.edu%2Fviewdoc%2Fdownload%3Fdoi%3D10.1.1.84.921%26rep%3Drep1%26type%3Dpdf&ei=BXiIT7ryEIPEgQfuu_TBCQ&usg=AFQjCNHF-2kq4OaqEGHMZBN3z0kXh3zM8A&cad=rja
Intel's own research shows a lack of increase when needing to tie up additional resources to schedule and track data between cores, and result dependency. I agree the initial result of two to four cores is a significant increase as we can offload other threads from the core running our primary worker, or assign different processes to different cores, however the overhead cost starts degrading the performance with more cores.
I was merely asking for a hardware thread handler, and if like Nvidias "hot clocks" it can run at 2 or 4 times the core speed it could easily dispatch and track resources, even handling the offload of work to the GPU cores for faster processing. I understand the unified memory and number of threads/different type of work makes it difficult, but compared to making mediocre processors blazingly fast, what downside is there? If it added 25W of heat but was only used on enthusiast grade processors I would still buy it, as would many.
That said, I'm fairly sure. Many of us would buy higher clocked chips up to 250w, and it would still sell among us. Given it's still able to be air cooled and all and most mid tower cases supporting 120mm tower coolers. Just leave a cooler out of the box, or give an option for a 155-165mm tall cooler with push-pull fans and a good design and we're set.
nVidia can do what they do because GPUs dispatch large workloads and runs a calculation on every shader that has data. CPUs don't work like this because you're not bulk processing the same instruction across a ton of data. You have different instructions being run, therefore what you're describing for a CPU is essentially a pipeline, which CPUs already have, but "dispatching" anything will result in less performance in single-threaded instances.
Do you know the basic 4 operations that almost any general purpose CPU does? Not to over-simplify how long a pipeline is, but basically you: LOAD, DECODE, EXECUTE, AND STORE, in that order. At this level, there is no parallelism, is's very step by step in the sense that you can't decode an instruction before you load it, you can't execute an instruction until it has been decoded, and you can't store the result after the instruction has been executed.
A single thread on a CPU might run the four, but if we have a hardware scheduler that reads ahead and prefetches data "branching" and then performs the decode at twice the rate, programs shaders to do the work, and then they execute it and store it in the contiguous memory pool what difference does it make if the CPU transistors do it, or if the same instruction is run 5,000 times in the program, the GPU transistors do it.
Pretty simple actually, GPU's already do 90% of this work to keep up with demand. The hardest part would be resource tracking, but again, if they solve it and the performance increase is only 25% better on average, they win.
A shader is small because it has a limited number of instructions it can perform and has no control mechanism, no write back. There is no concept of threads in a GPU, it is an array of one or more sets of data that will have the same operation performed on the entire set. A shader is also SIMD, not MIMD as you're describing.
Where a CPU can carry out instructions like "move 10 bytes from memory location A to memory location B," A GPU does something more like "multiply every item in the array by 1.43."If it is so simple, why hasn't anyone else figured it out, I'm sill convinced that you don't quite know what you're talking about.I do have a bachelors degree in computer science not to mention I'm employed as a systems admin and a developer.
i think thats the approach amd is taking with apu's in the future(HSA)