Monday, March 6th 2017

AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
AMD's Ryzen 7 lower than expected performance in some applications seems to stem from a particular problem: memory. Before AMD's Ryzen chips were even out, reports pegged AMD as having confirmed that most of the tweaks and programming for the new architecture had been done in order to improve core performance to its max - at the expense of memory compatibility and performance. Apparently, and until AMD's entire Ryzen line-up is completed with the upcoming Ryzen 5 and Ryzen 3 processors, the company will be hard at work on improving Ryzen's cache handling and memory latency.
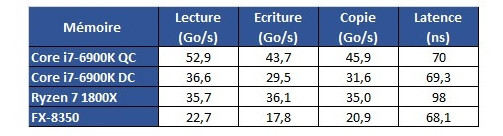
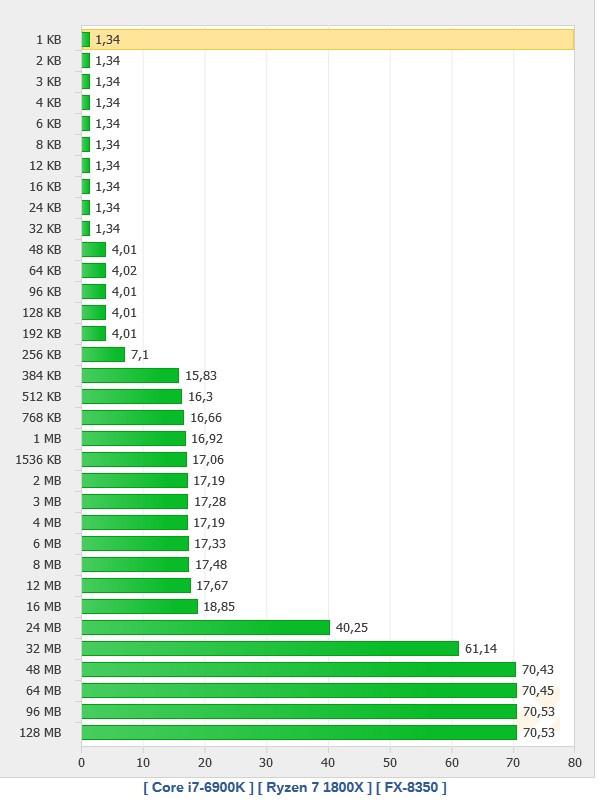
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).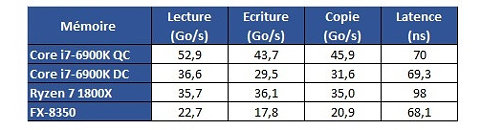 Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
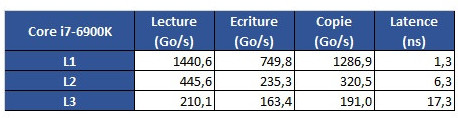
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.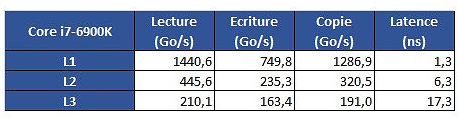
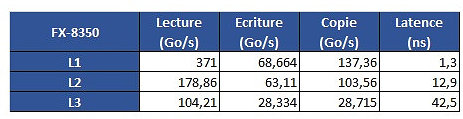 The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times.
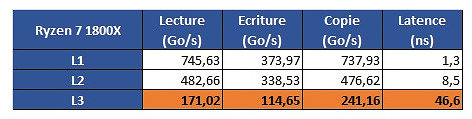
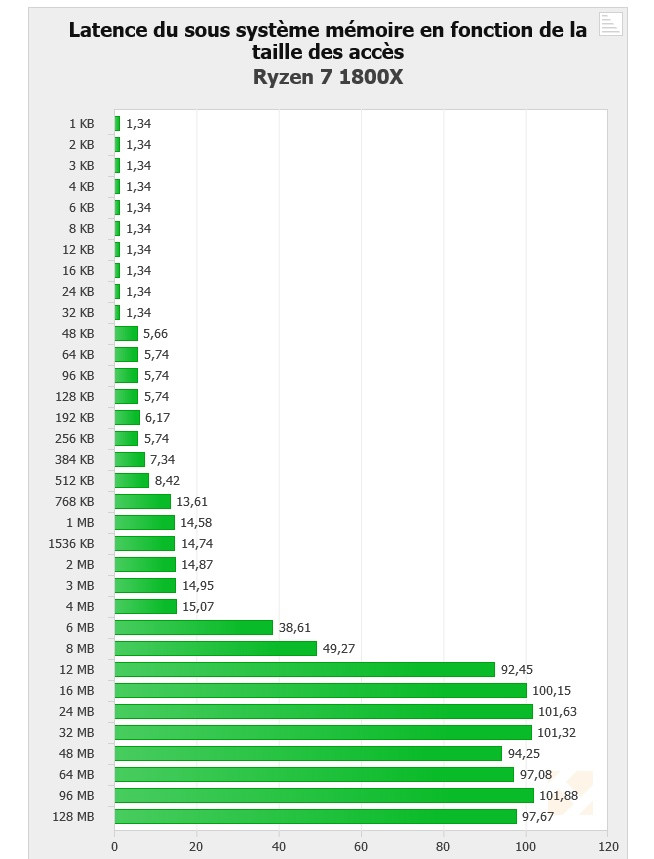
The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times. However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time.
However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time. The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
Source:
Hardware.fr
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.
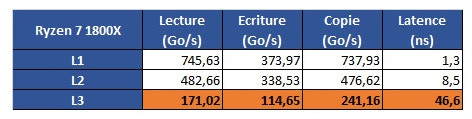
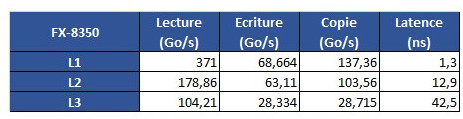
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
120 Comments on AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
69.3 vs 98 is... 3 times?
PS
Are they testing "Core from the left quad accessing L3 of the right quad" scenario? (CCX in the title hints at that, but nothing in the chaotic text of OP talks about it.
I think caching could surely be coded 'sympathetically' to the Ryzen architecture. Then again, I know nothing about coding and I am probably talking out my ass.
At the end, this is good news for AMD: they have a clear improvement path --> Lower those L3 and system memory latency figures!
It's clear that the CCX design relies on the interconnect bandwidth, so AMD has two paths going forward: 1) either find a way to increase that bandwidth for a truly scalable architecture, or 2) go Intel's route and design a chip that uses a larger CCX (with 16 cores), or 3) Do both.
It seems to me AMD should really do both if they want to also become a player in the server market again. 32-core (2 x CCX), 4-chip configurations with up to 128 cores/system is not too much to ask in the server business...
Or (totally fantasizing now, or am I?), they could truly innovate and ditch the multi-chip system designs but rather build up on the scalability idea to come up with 16-core CCX's that can do up to 8-way (on-chip) interconnects, yielding a full chip with 128 cores. Think about the implications for business clients: a single 128-core chip on a small board, meaning much-easier-to-deal-with systems with much lower power utilization (4 chips on a huge board means huge power overhead). Then, similar to what they do in GPUs, they can trim it down to create a product line-up. I have a feeling this is AMD's way (vision), but it's a goal that's a long way off at the moment...
Even if Intel catch AMD that would be with 8 and 10 cores processors and 150W power consumption.
Because of that upgrade on AMD is good choice at the moment.
Special if someone want small PC, mATX mobo, fanless 500W PSU and RX 580 + 1800X.
I don;t want to comment at all rumors about some strange lags, and some hidden problems of AMD.
Their CPU on paper shine, numbers are fantastic. If powerfull Intel fall so low that need to justify his presents with i7-7700K and
4.5GHz in games locked on 2 and 4 cores and on that way distract customers from AMD, than really no word. No one will help you except i7-7700K.
Everyone who sabotage real picture of AMD processor is enemy of enthusiasts and improvements and shoot in own legs.
Because AMD give you CPU capable to beat i7-6950X on LN2 for 500$, you can buy world recorder for 500$, with 2 core less, and far smaller power consumption.
In Windows 10 and DX12 people could get far better performance than Intel Broadwell-E. But Intel didn;t do nothing to provide that. We non stop listen about some walls and no space for improvements. No space to drain same architecture 5 years, everything what they done with X79 and X99 could fit in single socket, but there is space for new generations.
And it's not a typo, it appears 5 times in the text, while "ns" never appears.
- Memory latency (not L3) is higher (and ns, not ms ;))
- L3 is split in half and communication between the two CCX is thru the same link that links the CCX to the memory controller, PCIe, etc, at a much lower speed.
Plus many other things regarding CCX etc. I don't know how good a job Google Translate does of our article but I'd suggest people interested give it a shot (page 22/23 maybe 24 [we found another issue with game performance that's linked to Windows 10] is what you're looking for).
To answer another question, yes, L3 readings are innacurate in Aida (that's why we show them in orange in the table). We do use another test (a beta benchmark from Aida, too) to check latency at different block sizes, that one is the basis of our analysis.
G.