Monday, March 6th 2017

AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
AMD's Ryzen 7 lower than expected performance in some applications seems to stem from a particular problem: memory. Before AMD's Ryzen chips were even out, reports pegged AMD as having confirmed that most of the tweaks and programming for the new architecture had been done in order to improve core performance to its max - at the expense of memory compatibility and performance. Apparently, and until AMD's entire Ryzen line-up is completed with the upcoming Ryzen 5 and Ryzen 3 processors, the company will be hard at work on improving Ryzen's cache handling and memory latency.
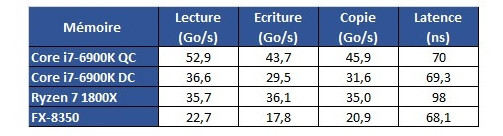
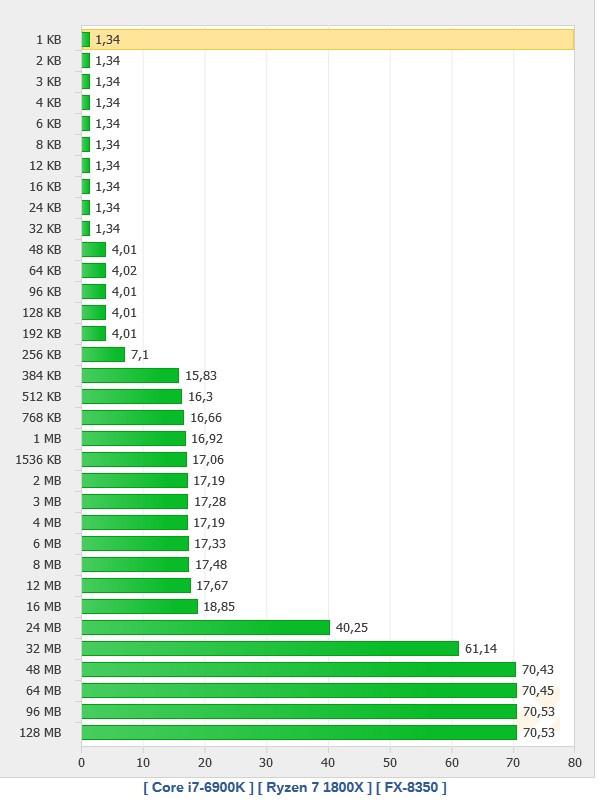
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).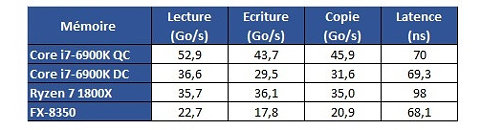 Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
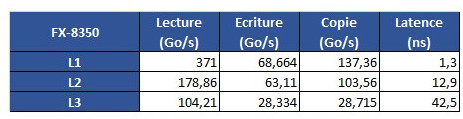
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.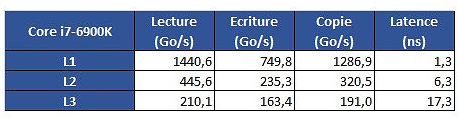
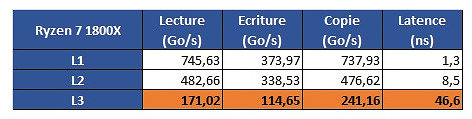
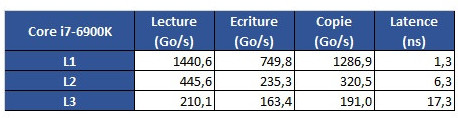
 The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times.
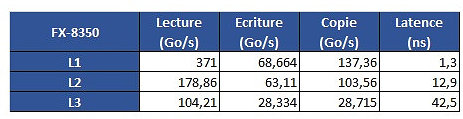
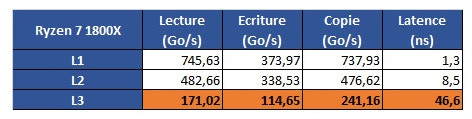
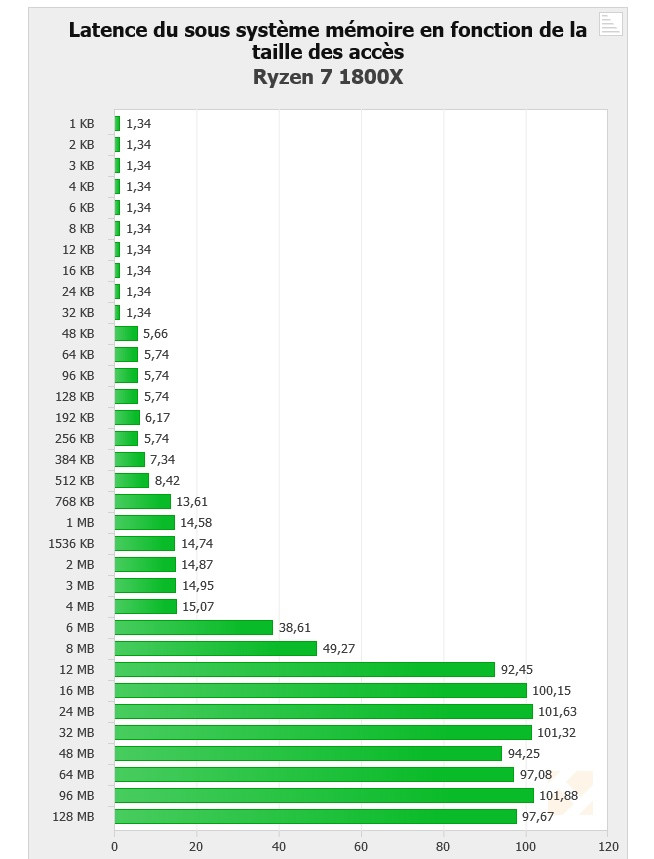
The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times. However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time.
However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time. The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
Source:
Hardware.fr
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
120 Comments on AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
forums.aida64.com/topic/3768-aida64-compatibility-with-amd-ryzen-processors/
And "2 x Octal core" doesn't seem right. When a 4790k says "quadcore" so maybe it needs some more fixing. :)
Thanks Dave.
In other news, my Asrock X370 (pro gaming) ships today.
Has anyone done any tests to see if the issue is greater for GPU's on the chipset PCIe lanes vs GPU's on the CPU embedded PCIe lanes?
(EDIT: Fix CPU lanes with PCIe lanes)
Naples has a ton of PCIe lanes connecting two sockets together on dual socket configs. Somewhere at AMD there must have been people who worked on intercommunication between the 2 CCXs. I don't buy the theory that AMD simply dropped the ball and put out a chip with a glaring architectural flaw. If there are limitations of Ryzen I expect to find compromises that were made after intense discussion. Although they don't have a foundry, they do have the ability to do limited production in house for testing and research purposes. It really feels like people are way underestimating AMD and the quality of their product.
Taken from
rog.asus.com/articles/technologies/your-guide-to-the-ryzen-am4-platform-and-its-x370-b350-and-a320-chipsets/
2 from the CPU and one from the chipset (with the associated latency).
In fact what a lot of the folks using VM want to do is have all 3 cards in separate I/O groups so you can e.g. have one card for your host O/S and the others each dedicated to a VM.
If the groups/UEFI are right, you could have a slower card off the chipset and have that as the host OSes' card (boot graphics) and then two powerful cards connected to the VMs or whatever.
Man, I am laughing all the way to the bank.
Your paradigm of splitting, for coding purposes, the 8 cores into discrete 4 core ccxS & 8MB L3 cache blocks. & then minimising interaction between them, could speed some apps considerably.
I am a newb~, but i mused similarly in the context of a poor mans vega pro ssg (a 16GB $5000+ Vega w/ an onboard 4x 960 pro raid array).
if you install an Affordable 8 lane vega and an 8 lane 2x nvme adapter, so both link to the same 16 lane ccx (as a 16 lane card does e.g.) , then the gpu and the 2x nvme raid array may be able to talk very directly, and ~share the same 8MB cpu L3 cache. It doesnt bypass the shared pcie bus like Vega SSG, but it could be minimal latency, and enhanced by specialised large block size formatting for; swapping, workspace, temp files and graphics.
Vega 56/64 of course, have a dedicated HBCC subsystem for such gpu cache extension using nvme arrays. Done right, it promises a pretty good illusion of ~unlimited gpu memory/address space. Cool indeed.
As you see, a belated post from me. We now have evidence in the perf figures of single ccx zen/vega apuS. Yes, inter ccx interconnects have dragged Ryzen ~IPC down.