Monday, March 6th 2017

AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
AMD's Ryzen 7 lower than expected performance in some applications seems to stem from a particular problem: memory. Before AMD's Ryzen chips were even out, reports pegged AMD as having confirmed that most of the tweaks and programming for the new architecture had been done in order to improve core performance to its max - at the expense of memory compatibility and performance. Apparently, and until AMD's entire Ryzen line-up is completed with the upcoming Ryzen 5 and Ryzen 3 processors, the company will be hard at work on improving Ryzen's cache handling and memory latency.
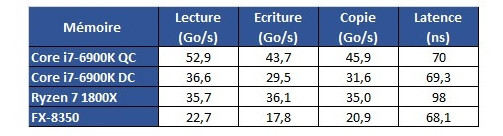
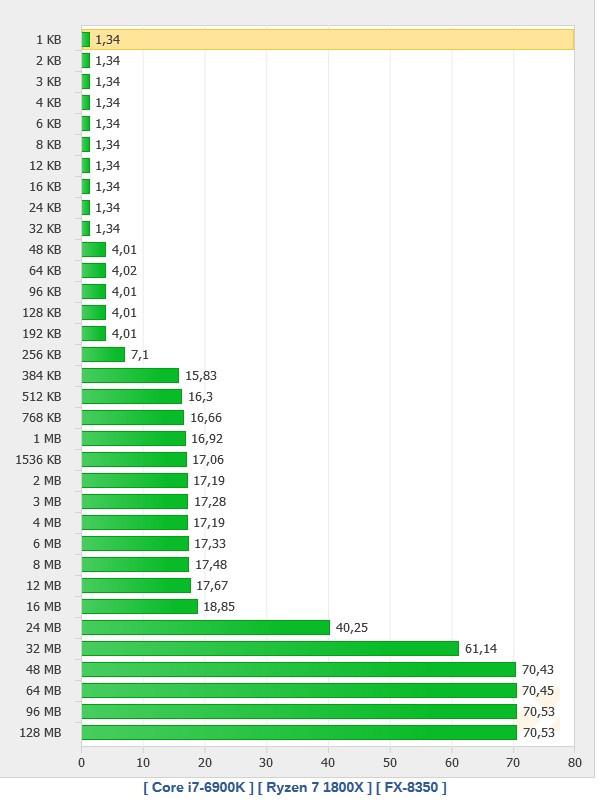
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).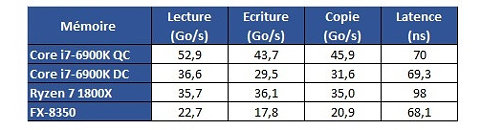 Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
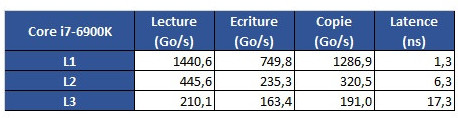
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.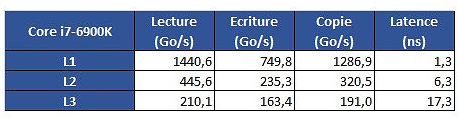
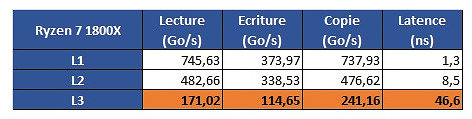
 The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times.
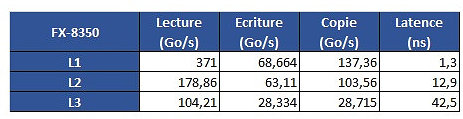
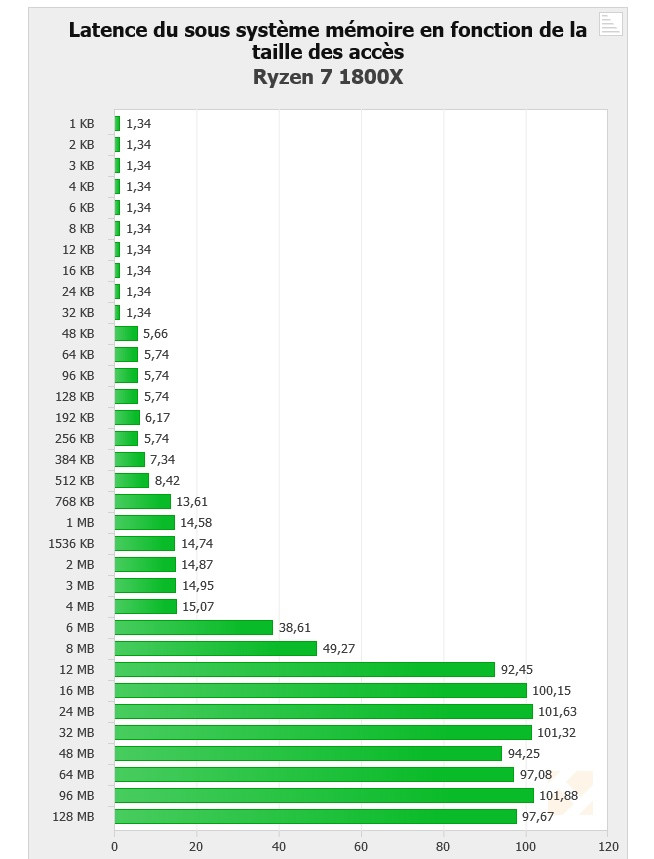
The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times. However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time.
However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time. The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
Source:
Hardware.fr
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.
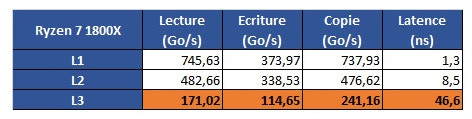
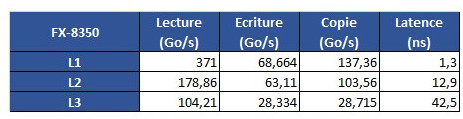
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
120 Comments on AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
Because here's what Stilt originally got which is no where near what they got. Though this is from last Thursday and I've not been keeping up with how often BIOSes have been released.
To be clear, 5704 was not the BIOS given to reviewers (I think 5702 ?) on the motherboards by AMD, you had to flash it yourself but that's pretty common with launchs and AMD gave many heads up on that.
www.legitreviews.com/ddr4-memory-scaling-amd-am4-platform-best-memory-kit-amd-ryzen-cpus_192259
SMT is also an issue but Windows 10 is worse than Windows 7 and Linux in terms of performance, most games have been benched in Windows 10.
I cannot find the same findings with a Xeon 2680 V2, it only drops a fps in windows 10 instead of 10 and in csgo 20 for me.
I can confirm something is iffy.
basicly windows treats ryzen as a massive 16 core cpu instead of 8c 16t
and that basicly creates all of the other problems that this cpu has because normally windows throw all of the heavy workloads into the physical cores and let the rest on the logical ones but here windows throw everything at everything resulting on the cpu to have to rely on "stealing" ram from the system ram because windows thinks it has a massive 138mb l3
and due to the nature of the smt some times when windows keeps a thread on the cpu (remember amd says that a ccx is a cpu not a core) the data on the l3 gets "lost" and thus windows re issues a new load to the said thread but the data is already on l3 thus resulting on the core parking bug because the cpu needs to pause the new workload to flush the identical one that is already on the l3
and we already have similiar problems in the past(identical to be honest ) its not really hard to connect the dots especially when we know that the smt taps into all the three caches
also a really good video to watch
How much performance is left in Ryzen once things get tweaked out? 10%?
Some vary salient points in there and also showing that Bulldozer seems to have overtaken 2500k in gaming over time ...
My main gaming rig still has a 3770k, haven't found a reason to upgrade yet. Same with my Steambox build, running a 4590. I'll replace all my crunchers with 1700s, that's a given.
Anyone tried to disable 4 cores (or 7, to be safe) in BIOS and see how it fares?Fixed that for you.
Admittedly, first time I saw the Zen reviews I thought that it'd kill intel in anything outside games. Then I remembered that even industry standard productivity software can be -and often is- embarrassingly single threaded, so a combination of both (core count and per-core IPC) is often needed, and here Intel still reigns, as long as price isn't a factor.IMO, saying that that channel is merely an AMD apologist would be an understatment.
(And I have a nagging feeling that I've already said that somewhere around here....)
forum.beyond3d.com/threads/why-nehalem-for-games-is-not-better-than-yorkfield.44382/
In fact, it does look like 1800X's dedicated L3 (~15 ns) is faster than i7-6900K (~17ns).
Proof: www.techspot.com/review/1348-amd-ryzen-gaming-performance/
In games that are well multithreaded, Ryzen does fine. In games that aren't, it does well enough. The higher the resolution and detail, the more Ryzen closes the gap with Intel.