Tuesday, June 6th 2017

AMD's Entry-Level 16-core, 32-thread Threadripper to Reportedly Cost $849
AMD has recently announced that at least nine models are in preparation for their new HEDT line-up, which will, for now, feature processors with up to 16 cores and 32 threads. The entry-level 16-core chip, the Threadripper 1998, will come in at 3.20 GHz with 3.60 GHz boost, 155 W TDP, and is absent of XFR.
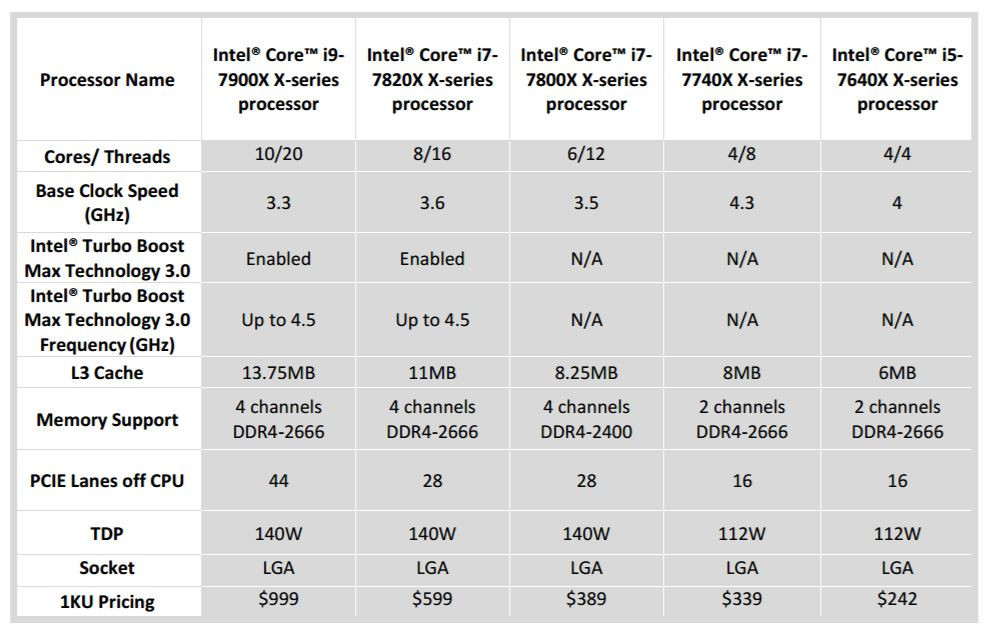
If recent reports hold true, this entry-level Threadripper 1998 will come in at $849. Now, let's be honest - this seems like an immensely optimistic value, undercutting even Intel's 10-core 7900X, which has been announced at $999 (in tray quantities.) That's over 6 more cores and 12 more threads for $150 less. And let's just say that AMD's IPC isn't that much lower than Intel's to justify such an aggressive undercutting, a high-volume approach to the market.

Source:
ETeknix
If recent reports hold true, this entry-level Threadripper 1998 will come in at $849. Now, let's be honest - this seems like an immensely optimistic value, undercutting even Intel's 10-core 7900X, which has been announced at $999 (in tray quantities.) That's over 6 more cores and 12 more threads for $150 less. And let's just say that AMD's IPC isn't that much lower than Intel's to justify such an aggressive undercutting, a high-volume approach to the market.


128 Comments on AMD's Entry-Level 16-core, 32-thread Threadripper to Reportedly Cost $849
I'm very impressed with their pricing if that's accurate.. I believe they're going as low as they can on price, not because performance is bad, but because they want as many people as possible to buy it and spread the word of how good their new generation of products is. They've hurt their reputation so badly this last decade that they need to price stuff low for IT companies to begin using them again.
We already know how the fabric works in an 1x00(X) chip: what we don't know is how it works linking different chips. Does it have a higher penalty then the latency between different CCXs of the same chip? The infinity fabric's performance when linking different chips is what is going to make or brake threadripper as well as epyc: we shall see ...
Regarding the pricing, i totally agree with what you said.
According to AMD they're getting close to 100% scaling with this modular design, and likely would be if they could keep clock speeds the same. Amd did a presentation recently where thread ripper done a cinebench done a run in 13 seconds ( approx) where as if actually 100% scaling it be 12 or so. That still aint bad at all.
It looks like if you want IPC single core performance intel are still king, but when it comes to multithreaded work loads I think AMD have outdone themselves.
Doubling up to yield 16 core TR, & again for 32 core Epyc, clearly has been plain sailing, given the latters imminent release.
Next big trick is getting the cpu & vega gpu leggo blocks to team up nicely on their "fabric", and few amd savvy folk would doubt thats a done deal too - its the same as an apu, which amd has done for many years.
we will see zen/vega apuS b4 xmas, in the more lucrative mobile market first.
Beyond that point, i personally cant see intel/nvidea getting much of a look in, if AMD can grow fast enough to meet demand. But again, the simplicity of their formula, makes me confident they have this covered.
The world will be their oyster.
Take the ~existing Epyc MCM. Its a fabric that can team up to 8 of the above leggo blocks. a server (which it sure is w/ 128 lanes), and could be purchased with just the right balance of cpu/gpu cores to suit projected c/gpu workloads.
What do u think of the notion that it pays to have symmetrical arrangements of cores/cache on these AMD Multi Core Modules? e.g. 8 core vs 6 core ryzen.
Conversely, the notion that the asymmetrically populated MCMs may yield more bang for buck, as they nip some cores, but leave the cache alone, but dont really price it in?
Either way still clever stuff!
@At the guy who asked about intels high core count stuff being lower clocks.
Basically with a monolithic design you've got two problems, first of all power delivery and TDP start to effect what high clocks you can get as the chips will start having stability issues earlier on. That and as they are sold for the server market not consumer lower clocks that guarantee stability and TDP are better. Also monolithic design means all x cores need to hit the same target core speed. If 1 doesn't go to 3.5ghz for example then they'll fuse off that 1 off plus its pair and sell it as an 18 core for example ( if it were a 20 core chip)
Where as AMD are making these 8 core chips, ones that arnt right end up in the 1600/1500/1400 series cpus. All the good ones get matched up ( best ones in server, followed by thread ripper and then ryzen) so if you have two chips that can 3.5 ghz on all cores then they'll stick them in a thread ripper package, they'll also have the benefit of the two chips actually being apart and so not heating each other up to such a degree which is why Ryzen/Thread ripper are clocked about the same. A monolithic CPU with that many cores would be toasty to say the least.
(Large chips are more costly to design as you get less chips per wafer, you also increase the chances of having a flaw the larger the chip as well)
Basically if all this works as it should, AMD have a system where they can maximise profit for each product sku whilst minimising losses on bad chips.
Its just chip binning as usual cept the infinity fabric allows them to be a lot more flexible.
Edit: I see that they just disabled two cores and half of the L3 on each CCX in 1400. At that point, why didn't they just do a full CCX? :kookoo:
It seems clear that what we historically know as an apu from amd (ryzen mobile nee raven ridge), will ~comply with ryzen basic layout MCM. Instead of 2 x 4 core cpu leggo blocks on the MCM, it will be 1 x 4 core cpu & 1 vega gpu.
If linking these 2 core units on the fabric works as well as it should in amdS uniquely experienced hands, then the concept is very extendable to historically UNFAMILIAR APUs, like 16 core and 4 x gpu on one amd ~epyc MCM.
I agree that their step down from ~ryzen, the expected soon, R3 cpuS, which are 4 core or less, i.e only one leggo block for which the MCM (& maybe chipset) is ~superflous expense, will be revealing.
FYI, I will post an amd slide separately as behoves its interesting nature :).
woo - this slide shows a fully populated epyc mcm, with the fabric branching yet again to further cpu/gpu cores.
I am curious how this works physically.
What it may refer to, is that the links are via a 2 socket server? - i.e. the fabric is extended to include a second epyc MCM on the other socket. These 2 socket servers allow double the leggo blocks, but no increase in pcie lanes over a 128 lane 1 socket server, as the extra 128 lanes are used for interconnecting the two ~epyc mcm/fabrics.
Still, its not how it looks. It shows a branch to a cpu/gpu on both ends of the epyc mcm.
www.overclock.net/t/1620103/lightbox/post/26112320/id/3040021
or
www.google.com.au/imgres?imgurl=http://www.overclock.net/content/type/61/id/3040021/width/350/height/700/flags/LL&imgrefurl=http://www.overclock.net/t/1620103/various-exclusive-amd-vega-presentation/920&docid=Wz5LiR-5iN6G0M&tbnid=a0ukJ3NOv60CjM:&vet=10ahUKEwjmxZHSzLrUAhWCWbwKHayrCcIQMwg0KA0wDQ..i&w=350&h=197&bih=880&biw=1776&q=amd epyc slides&ved=0ahUKEwjmxZHSzLrUAhWCWbwKHayrCcIQMwg0KA0wDQ&iact=mrc&uact=8
an exciting (imo) but obscure feature of vega is provision for dedicated raid nvm ssd storage directly connected to the gpu, laying the foundations for unheard of storage speeds for use as ~unlimited (512TB) vram sizes using virtual memory.
Perhaps even ~500GBps HBM2 vram can be pooled among GPUs and even CPUs, tho i doubt the latter (cpus cannot use vram from what i hear).
Fundamental to the biz model, is its a ~fixed cost biz. sure there are variable costs payable to fabs etc., but the unit variable costs pale (and amd are getting pleasing yields as a bonus) beside the money irretrievably sunk in getting that first chip produced and supported.
Nor do i think ryzen price cuts are unconnected with the imminent release of epyc products. Its normal to gouge early adopters a bit when supply is short anyway. early adopters accept there is a premium & dont begrudge it. The new reality is ryzen has competition from sibling products, and must adjust its price point.
This is contrary to the popular view. TR is a consumer product, not for the cores, but for the lanes.
Hi bandwidth devices, NVMEs ssdS especially, have rather blindsided an industry with 5 year product development cycles.
Every such ssd, must have 4 pcie3 lanes (both due to the specification, and because they will soon saturate that bandwidth, and now come close to doing so). It would take 8x sata ssdS to saturate 4 lanes. multiple 16 lane gpuS have gained utility recently. The new norm for lans will be 5-10x the bandwidth of the current 1Gb/120MB lan, ...
Intel even have the nerve to sell current products with a ludicrous 16 lanes total. even the higher lane count models i distrust. - they seem to be shared via the southbridge.
Amd got a bit lucky - they just happened to be aiming for servers via their mcm/fabric, which they may as well flog to consumers as well, and all that server type grunt, serendipitously, is now very desirable on even consumer desktops, and certainly on hedtS. (FYI, TR =64 lanes & epyc 128 lanes. Ryzen x350 - 24 lanes, x370 chipset = 28 lanes).
the apu could be interesting, as it will probably forgo the need for the usual 16 lanes for cpu/gpu interconnect, by simply using the fabric rather than the system bus.
This is how their apuS have worked for many years (A10-7850k e.g.).
As others have ~said here, amdS focus should not be on profits now, but seeding the; vast, lucrative, virgin and cautious server market.
The ecosystem is ~as important as the product. W/o sales volume, developers wont do the tweaks that can make big differences to productivity.
I forget re which product, but lisa su mentioned 5000 "seeder packs" sent pre-release to industry folks. Surely this excellent investment is a serious hit to the current account books, yet alleged stock analysts pilloried AMD for losing a lousy $70m in the quarter ending a few weeks post ryzen release. They are scoundrels and/or fools.
There will be a 16-core for ~$850, but this model will likely max out at ~3.5-3.8GHz. However with some binning it wouldn't be insane to think they could have 16-cores clocked at 4.0 - 4.2GHz, but at a higher $1200 - $1500 price point.
xfr is one core and these 8 core ccx cant get past their own boost/xfr with all cores for the most part. Not sure why adding another ccx using the same exact architecture can suddenly reach past what others cannot...
That logic leap escapes me (cause its not logical). :)
Seriously...what suddenly makes these all 4-4.2ghz cpus when most 8 cores cant get past 4?
And he was imagining the fantastical probability not stating fact, "However with some binning it would be insane to think they could have 16-cores clocked at 4.0 - 4.2GHz."
www.guru3d.com/news-story/amd-ryzen-14nm-wafer-yields-pass-80-threadripper-cpus-on-track.html
Indeed it is possible to improve the process. This is why i conceded zen2 for that type of 'insane to think of' clock.
Threadripper is nothing more than 2 zen ccx's, right? Where is the process improvement? I can see amd binning these cpus, but to fit within a power envelope more so than higher clocks. The more cores, generally, the less stock clockspeed.
I dont find it impressive that one core boosts to 3.9...its no different than one core boosting to 4ghz xfr on one ccx. In my feeble head, the fact that it boosts less with merely one more ccx speaks volumes to me about the 16 core ever clocking that high. :)
And cheers for amd hitting 80% yields...but that has nothing to do with clockspeed on the same exact process and architecture.
I also took the '...insane to think....' part different than you. In a positive light. I mean, why throw the binning part in there if its so outlandish?? When i see sick tricks i call it insane.... but again, in a positive way. A little disbelief, a lot of awesome. ;)
If AMD is smart, they will decouple the memory clock from the IMC/Fabric clock and let them be independently adjusted if it's latency sensitive. That would drive it home all together.
Im betting, lets be honest...guessing... quad channel wont matter much. Increased bandwidth, but also increased latency... so, it will depend. Im curious to see how some empirical testing on that goes. :)
Intel 12-16 core may well be technically superior in parts, but have a cost structure of a different order - fab AND cooling.