Monday, October 8th 2018

AMD Introduces Dynamic Local Mode for Threadripper: up to 47% Performance Gain
AMD has made a blog post describing an upcoming feature for their Threadripper processors called "Dynamic Local Mode", which should help a lot with gaming performance on AMD's latest flagship CPUs.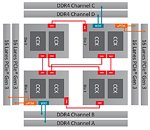
 Threadripper uses four dies in a multi-chip package, of which only two have a direct access path to the memory modules. The other two dies have to rely on Infinity Fabric for all their memory accesses, which comes with a significant latency hit. Many compute-heavy applications can run their workloads in the CPU cache, or require only very little memory access; these are not affected. Other applications, especially games, spread their workload over multiple cores, some of which end up with higher memory latency than expected, which results in a suboptimal performance.
Threadripper uses four dies in a multi-chip package, of which only two have a direct access path to the memory modules. The other two dies have to rely on Infinity Fabric for all their memory accesses, which comes with a significant latency hit. Many compute-heavy applications can run their workloads in the CPU cache, or require only very little memory access; these are not affected. Other applications, especially games, spread their workload over multiple cores, some of which end up with higher memory latency than expected, which results in a suboptimal performance.
The concept of multiple processors having different memory access paths is called NUMA (Non-uniform memory access). While technically it is possible for software to detect the NUMA configuration and attach each thread to the ideal processor core, most applications are not NUMA aware and the adoption rate is very slow, probably due to the low number of systems using such a concept.
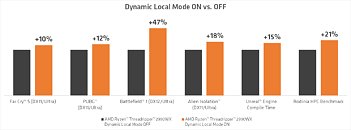
 In ThreadRipper, using Ryzen Master, users are free to switch between "Local Memory Access" mode or "Distributed Memory Access" mode, with the latter being the default for ThreadRipper, resulting in highest compute application performance. Local Mode on the other hand is better suited to games, but switching between the modes requires a reboot, which is very inconvenient for users.
In ThreadRipper, using Ryzen Master, users are free to switch between "Local Memory Access" mode or "Distributed Memory Access" mode, with the latter being the default for ThreadRipper, resulting in highest compute application performance. Local Mode on the other hand is better suited to games, but switching between the modes requires a reboot, which is very inconvenient for users.
AMD's new "Dynamic Local Mode" seeks to abolish that requirement by introducing a background process that continually monitors all running applications for their CPU usage and pushes the more busy ones onto the cores that have direct memory access, by adjusting their process affinity mask, which selects which processors the application is allowed to be scheduled on. Applications that require very little CPU are in turn pushed onto the cores with no memory access, because they are not so important for fast execution.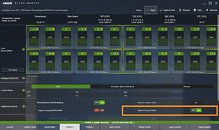 This update will be available starting October 29 in Ryzen Master, and will be automatically enabled unless the user manually chooses to disable it. AMD also plans to open the feature up to even more users by including Dynamic Local Mode as a default package in the AMD Chipset Drivers.
This update will be available starting October 29 in Ryzen Master, and will be automatically enabled unless the user manually chooses to disable it. AMD also plans to open the feature up to even more users by including Dynamic Local Mode as a default package in the AMD Chipset Drivers.
Source:
AMD Blog Post


The concept of multiple processors having different memory access paths is called NUMA (Non-uniform memory access). While technically it is possible for software to detect the NUMA configuration and attach each thread to the ideal processor core, most applications are not NUMA aware and the adoption rate is very slow, probably due to the low number of systems using such a concept.


AMD's new "Dynamic Local Mode" seeks to abolish that requirement by introducing a background process that continually monitors all running applications for their CPU usage and pushes the more busy ones onto the cores that have direct memory access, by adjusting their process affinity mask, which selects which processors the application is allowed to be scheduled on. Applications that require very little CPU are in turn pushed onto the cores with no memory access, because they are not so important for fast execution.

86 Comments on AMD Introduces Dynamic Local Mode for Threadripper: up to 47% Performance Gain
why would anyone buy a cpu with more than 8 cores if they just going to use the system for gaming?
I thought an 8 core CPU was the sweet spot in CPU's right now for gaming ? (probs due to consoles?)
do any games use or support more than 8 core cpu ?
I don't know so i'm asking.
Rate the point, not the person.
Honestly, it IS an odd design. But it's not useless.
If I really wanted to answer that question, I'd read up all the articles and official AMD docs that I could get my hands on to really understand it. I'm sure the answer is there, but it would take some time and effort to do. I'm not willing to though, because the issue isn't important enough for me. Again, do you really know the ins and outs of these designs to criticise AMD for their design choices?
If you say yes, then I'll expect you to back that up with hard evidence before I consider your argument credible.Thanks for the clarification rtb. Only saw your post after I'd posted. :)
Those familiar with the core layout should know how these CPUs work, and the sacrifices AMD have made by letting two dies not having direct access to memory.
Due to these limitations, 2990WX(32-core) goes from performing very well in some tasks to performing badly, sometimes even worse than the 2950X(16-core), if the task is not ideal. One example. The 2950X(16-core) performs as expected and scales fairly well, while the 2990WX(32-core) is really a mixed bag.
The sad thing is that 2990WX(32-core) would have been a much better product if the dies were either balanced with one memory channel each, or the full 8 channels.
Can you finally see that it's not a flawed design as you put it, but one that's working within cost and compatibility constraints?
When you have a 2990WX(32-core) which is basically a double 2950X(16-core), and it performs as expected in a wide range of controlled benchmarks, but suddenly performs worse than the 16-core due the core configuration having severe limitations in design. Any engineer would call that a design flaw. It's not a bug, but a principal mistake in the design, an oversight since they didn't foresee this type of configuration early enough. It ruins what would otherwise have been a much better product.
Oh, and I am an engineer - that's not a design flaw. It costs $1800, not $5,000+.
No argument there. However this report here at Techpowerup could have made this a bit more clear. I'm still not 100% sure but this other reference seemed to make it a bit clearer:www.pcper.com/news/Processors/AMD-Announces-Threadripper-2970WX-2920X-Availability-New-Dynamic-Local-Mode-Feature
Funny how AMD has a much more expensive solution without these limitations, innit? ;)
For example, 7-Zip.
I think in hindsight AMD might've preferred to wait for Zen2/3 for their 32 core TR monster, but I'm sure they had their reasons & it's not like TR2 is bad.
If you're looking at different websites, like TPU, then they'll give different numbers depending on the combination of hardware & software used, including OS like linux.