Friday, June 28th 2019

AMD Patents a New Method for GPU Instruction Scheduling
With growing revenues coming from strong sales of Ryzen and Radeon products, AMD is more focused on innovation than ever. It is important for any company to re-invest its capital into R&D, to stay ahead. And that is exactly what AMD is doing by focusing on future technologies, while constantly improving existing solutions.
On June 13th, AMD published a new method for instruction scheduling of shader programs for a GPU. The method operates on fixed number of registers. It works in five stages: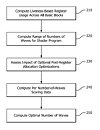
 It is important to note that the "liveness" of registers is most probably a reference to register utilization, while the term "wave" refers to the machine states, like for example EOP (End Of Pipe) and DRAW which draws the shader. There are of course many more states but these are just few examples from AMD's "GPU Open" documentation. The new method is supposed to bring additional performance improvements and reduce latency by making data (machine states in this case) like a wave that is stored in a register.
It is important to note that the "liveness" of registers is most probably a reference to register utilization, while the term "wave" refers to the machine states, like for example EOP (End Of Pipe) and DRAW which draws the shader. There are of course many more states but these are just few examples from AMD's "GPU Open" documentation. The new method is supposed to bring additional performance improvements and reduce latency by making data (machine states in this case) like a wave that is stored in a register.
You can find out more about it here.
On June 13th, AMD published a new method for instruction scheduling of shader programs for a GPU. The method operates on fixed number of registers. It works in five stages:
- Compute liveness-based register usage across all basic blocks
- Computer range of numbers of waves for shader program
- Assess the impact of available post-register allocation optimizations
- Compute the scoring data based on number of waves of the plurality of registers
- Compute optimal number of waves


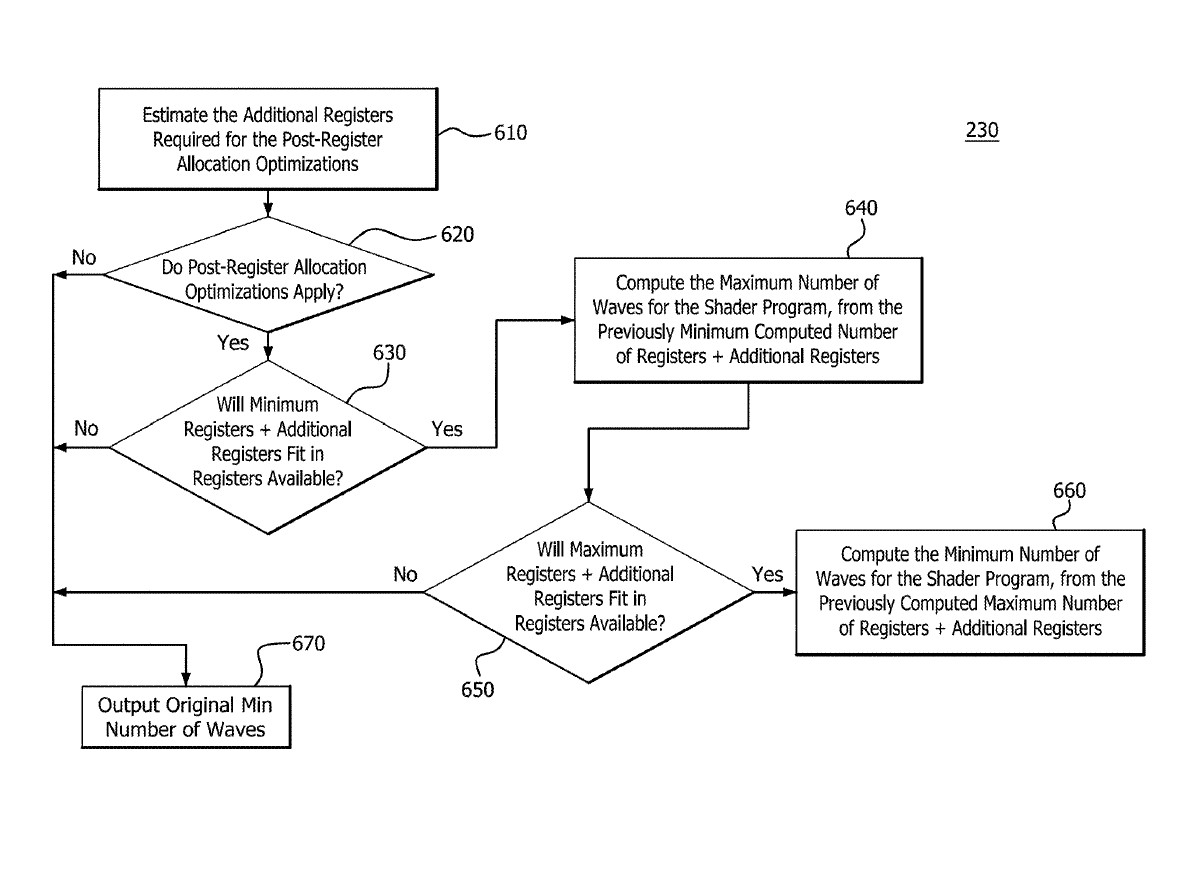
You can find out more about it here.
9 Comments on AMD Patents a New Method for GPU Instruction Scheduling
It also doesn't look mighty complicated... 'when its full, see if you can stuff in some more' 'and then some' captures it quite well I think. But it does sound very much like a fix for AMD's resource allocation problem and efficiency.
www.freepatentsonline.com/20190197761.pdf
direct link to patent
I think these are from 2017 so in a few more years we Might see them.
new mac pro with dual navi gpu card
- Support for Infinity Fabric Link GPU interconnect technology – With up to 84GB/s per direction low-latency peer-to-peer memory access, the scalable GPU interconnect technology enables GPU-to-GPU communications up to 5X faster than PCIe Gen 3 interconnect speeds.
do chiplets on gpus and amd could have an easy time beating nvidia. either one would rock!Generally speaking, alternates that do the same thing can be developed and implemented without breaching what someone else did.
I think it's still for x64 stuff, what else could it serve ?
Think of Intel's 5GHz CPU's integrate 1-2cores like that on the GPU itself and suddenly that makes the primary CPU a lot less frequency starved from a gaming standpoint at 1080p esport epeen Intel talking points. When you think about it like that too it makes a lot more sense than trying to get 16c to run at 5GHz on all cores for example to match Intel general grasping at straws a bit performance advantage in games that don't scale at resolutions that don't scale lol with overkill refresh rates ofc because hey gotta win somehow at all costs 240p 960Hz refresh rate here I come pew pew pew!!