Tuesday, November 17th 2020

Apple M1 Beats Intel "Willow Cove" in Cinebench R23 Single Core Test?
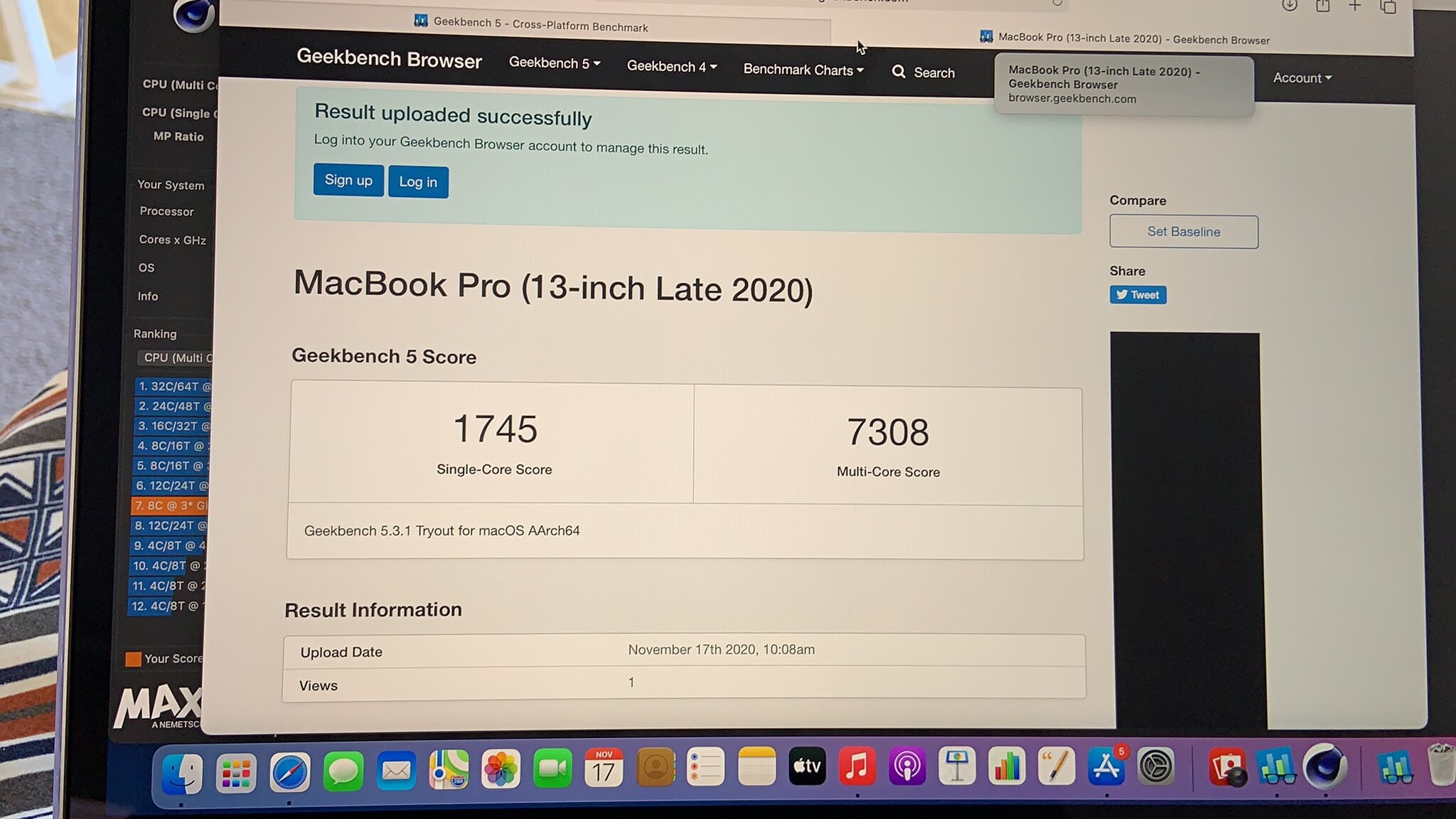
Maxon ported the its latest Cinebench R23 benchmark to the macOS "Big Sur" Apple M1 platform, and the performance results are groundbreaking. An Apple M1-powered MacBook Pro allegedly scored 1498 points in the single-core Cinebench R23 test, beating the 1382 points of the Core i7-1165G7 reference score as tested by Maxon. These scores were posted to Twitter by an M1 MacBook Pro owner who goes by "@mnloona48_" The M1 chip was clocked at 3.10 GHz for the test. The i7-1165G7 uses Intel's latest "Willow Cove" CPU cores. In the same test, the M1 scores 7508 points in the multi-core test. If these numbers hold up, we can begin to see why Apple chose to dump Intel's x86 machine architecture in favor of its own Arm-powered custom silicon, as the performance on offer holds up against the highest IPC mobile processors in the market.


Sources:
mloona48_ (Twitter), via Hexus.net Forums

96 Comments on Apple M1 Beats Intel "Willow Cove" in Cinebench R23 Single Core Test?
Here are some observations:
It only draws about 28w from the wall when the CPU is stressed (which is what my PC draws while idle.) It draws only 6w when streaming video.
The M1 doesn't render the desktop at 144fps smoothly. I had to set my refresh rate to 120hz, and there was still some stuttering when dragging windows.
The x86 versions of Firefox and Chrome failed to stream video from Twitch, but they were fast enough.
Safari is very fast. Jetstream 2: 202, Octane: 63K, Kraken: 450ms. But I don't like Safari.
Resuming is fast, but boot times are slow because macOS is bloated.
It's obvious that AMD could have made a wider core with tons of transistors and made a higher IPC, lower clocking design like this. But could they have done so at the same level of efficiency? AnandTech suggests no. Of course Apple has a major advantage here in being vertically integrated and as such not caring that much about SoC costs as long as they can preserve their margins. Neither AMD nor Intel can operate that way, pushing them towards smaller and more affordable core designs. But quite frankly, that isn't much of an argument against the M1 being a major achievement, it just shows that Apple's tactics are working. Too bad for us non-Apple users, really.
As for a 16-core M1 being doable? It would definitely be a gargantuan piece of silicon, likely comparable to the Xbox Series X SoC in area, though of course on 5nm and not 7. I don't see Apple having a problem with that, given that it would be - at the low end - for >$2000 laptops and desktops (with very cut down chips at that price, allowing for salvaging a lot of faulty chips), scaling to well above $5000 for top configurations. The margins are more than there to pay for a big chip. As for performance scaling: they'll of course need to change their memory architecture and design an interconnect that works for that many cores. But that isn't that hard. In terms of pure performance, if the M1 nearly matches the 5950X at <1/4 the per-core power, there's little reason why a bigger chip wouldn't keep that performance at a minimum. Heat density will definitely be an issue, but one that can be solved by spreading core clusters out across the SoC or adding a vapor chamber.
As for AMD or Intel on 5nm being more competitive: well, obviously to some degree, but I wouldn't expect current TSMC 5nm to clock even close to as high as current TSMC 7nm, so that move might actually lose them performance unless it's also a wider architecture. Would it allow them to catch up in perf/W? Not even close. A single node change doesn't get you 75% power savings.Wasn't AMD's quite about not wanting hybrid architectures on the desktop, referring to Alder Lake? Hybrid for mobile makes perfect sense, and I don't doubt AMD could scale down Zen to a low power design for that use quite easily. That being said, that patent doesn't describe a method for entirely obviating the need for an architecture-aware scheduler; only allocating threads based on the instruction set only works for workloads where only one set of cores supports that instruction set, such as power hungry AVX loads. You'll still need the scheduler to know to move high performance threads to high performance cores even if they use instruction sets common to the two clusters.Oh dear lord no. The majority of applications today are 64-bit. That would mean the "little" chip couldn't run them at all. Windows 10 is AFAIK 64-bit only, so it couldn't even run the OS! No. Just no.You really shouldn't be surprised that a ~20-24W hybrid 4c (big) + 4c (little) CPU lags significantly behind an 8c16t all-big-core 65W (88W under all-core loads) CPU. What makes this impressive is that they're managing half your score with less than a third of the power, half the high performance cores, and no SMT.20-24W is for the Mac Mini, not the Macbook Air.
Anandtech reviewed the Mac Mini not the Macbook Air and he estimated 20W power draw from the SOC at full load.
For your sake I hope you are just a massive fanboy and are not actually this dumb. Regardless I am not sticking around to find out, off to the ignore list you go.
The 15w zen2 are not too shabby for an x86, the single core perf didn't suffer that much. we have yet to see if low power zen 3 can do the same.
You're probably right about QC not daring to make anything that expensive though. IIRC the cost of a high end smartphone chip is typically in the $50 range (or at least it was a few years back). Even doubling that would likely be very close to the pure silicon (no processing, packaging, binning, etc.) cost of the M1. Which would leave QC taking a net loss on every part they sell. And given how slim margins are in the mobile industry (for everyone but Apple, that is), going higher in chip prices for a non-integrated company is likely not feasible. Though mixed designs with 1-2 X1 cores might serve as a good middle ground.
Its a Consumer thing, wanna a Golden Cage:
Yes
No
If u buy Software in the Appstore for a few 100 or 1000$ u can`t switch back to Windows or Linux or u need to buy the Software again.
In a few Years Apple can set the Prices higher and higher cause u can`t go out from the Apple Economic. :toast:
Apple then downclocked the design to 2.8GHz. There's no mystery here: Apple designed the widest core in all of computing history (erm... maybe 2nd widest. The Power9 8-SMT was 12 instructions / clock wide. But this M1 is the widest chip ever on the consumer market).
The "secret" to silicon power consumption is quite simple. Power consumption = O(voltage ^ 2 * frequency), and guess what? Frequency is related to voltage, so that's really O(voltage^3). Smaller transistors can operate at lower voltage (5nm advantage). Lower frequency means lower voltage, and then lower voltage means far less power. By making a wide (but low-frequency) core, Apple beats everyone in single-threaded performance and power-efficiency simultaneously.
Same thing with AVX512 (though different). Intel is willing to downclock their processor to perform 16 x 32-bit -operations simultaneously, because low-frequency / low-voltage but lots of work just scales better.
Anyway, you downclock and lower the voltage for power-efficiency. Then increase the width of the core to compensate for speed (and make things faster). Your processor needs to search harder for instruction-level parallelism, but that's a well known trick at this point. (Aka: out of order execution).
That's all there is to it. Everything after that is hypotheticals about the future. Can Intel / AMD make an 8-wide decoder? Or would the x86's variable-length instructions make such parallelism hard to accomplish?
-------------
Vya Domus has a point: traditionally, you'd just make a 2nd core instead of doubling the core size. (or, you go wide SIMD, which does scale well). What Apple is doing here, is betting that customers do want that faster single-core performance instead of shuffling data to a 2nd or 3rd core.
I agree with Apple however. I think the typical consumer would prefer a slightly faster (and slightly more efficient) single-core, rather than more cores. If given the choice between 8 cores (all 8-wide decode/execute), or 16-cores (of 4-wide decode/execute), the typical consumer probably wants the 8-core x 8-wide execution. Note: 8-wide execution is NOT 2x faster than 4-wide execution.
And your other comment about power density, yes, the W/Sqcm is an issue for low power designed devices, which is why 7nm TSMC can run 5Ghz on 1.5v or just 2.5Ghz on 1v it's about the design, putting space between the hottest parts so they can flux heat into other cooler areas without letting the magic smoke out.
Nvidia need 50w for 2,4 TFLOPS FP32 inc. 4GB GDDR5 and now Apple will do it similar with 7w on its IGP:shadedshu:
All are stupid,
Nvidia,
ARM with Mali,
Qualcomm with Adreno,
AMD wit RDNA
Only apple got the holy grail with theyr IGP to perform nearly 8 times better than anyone above :roll:
As for Nvidia, they don't develop for low power first, their small gpu are just a heavily cut down big gpu. Apple is doing the reverse, they started from something made for efficiency, and are making it bigger and bigger.
Their best low power soc is still the Tegra X1 from 2015 who's still based on maxwell. Them owning ARM won't have any effect until several years from now, but who know ? Nvidia has been marketing their mobile and desktop gpu as the holy grail of content creation so much, the revival of the mac might make them try harder