Tuesday, November 17th 2020

Apple M1 Beats Intel "Willow Cove" in Cinebench R23 Single Core Test?
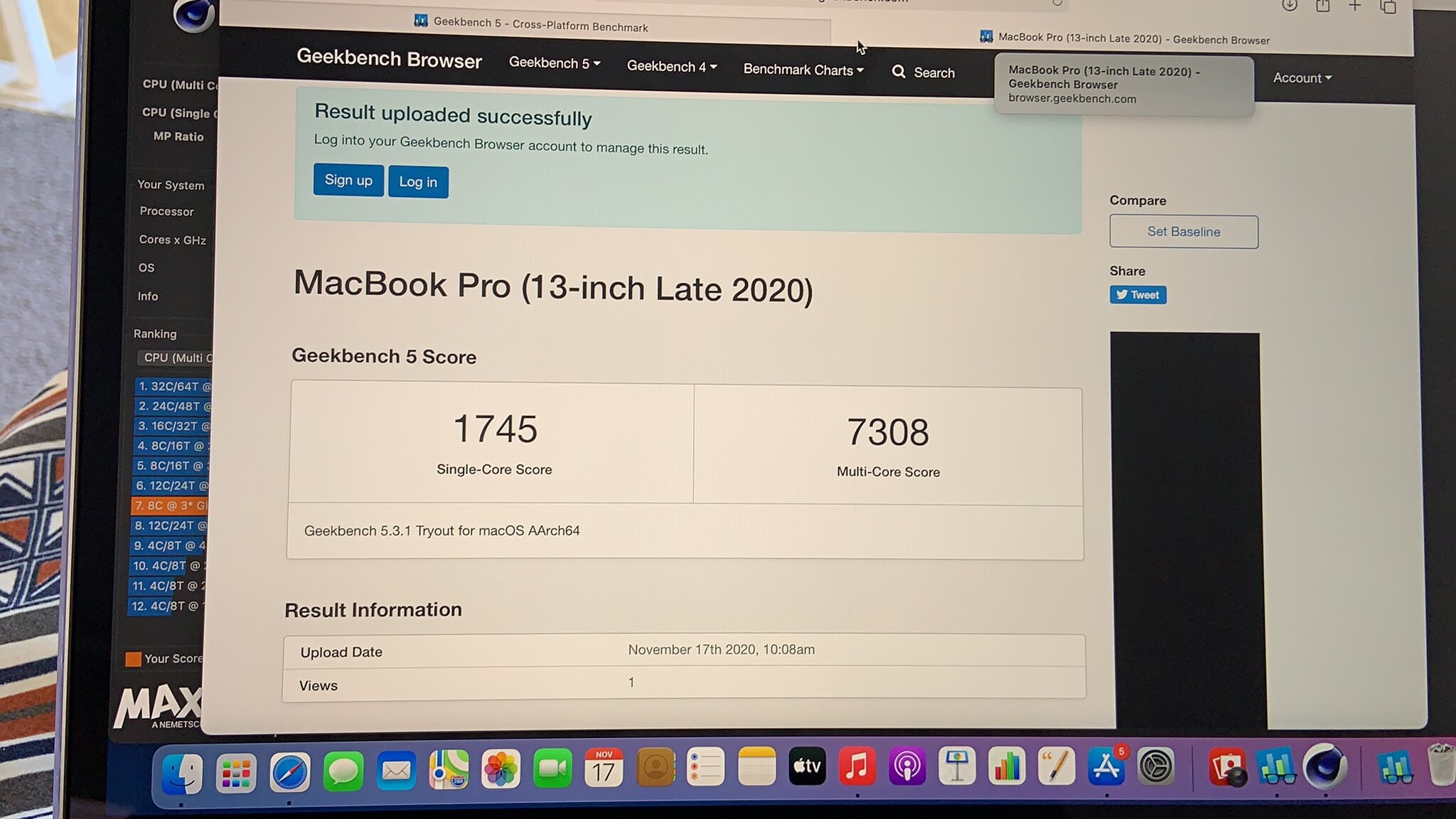
Maxon ported the its latest Cinebench R23 benchmark to the macOS "Big Sur" Apple M1 platform, and the performance results are groundbreaking. An Apple M1-powered MacBook Pro allegedly scored 1498 points in the single-core Cinebench R23 test, beating the 1382 points of the Core i7-1165G7 reference score as tested by Maxon. These scores were posted to Twitter by an M1 MacBook Pro owner who goes by "@mnloona48_" The M1 chip was clocked at 3.10 GHz for the test. The i7-1165G7 uses Intel's latest "Willow Cove" CPU cores. In the same test, the M1 scores 7508 points in the multi-core test. If these numbers hold up, we can begin to see why Apple chose to dump Intel's x86 machine architecture in favor of its own Arm-powered custom silicon, as the performance on offer holds up against the highest IPC mobile processors in the market.


Sources:
mloona48_ (Twitter), via Hexus.net Forums

96 Comments on Apple M1 Beats Intel "Willow Cove" in Cinebench R23 Single Core Test?
GPU can be used for ML though that will remain an advantage for the M1's specific unit's, both Intel with one API and AMD with God knows what (they do have ML in chip already on Ryzen for process optimization) tbf could incorporate better AI and Ml hardware catching Up to the M1's main advantage.
Not surprised here, Apple seems on course to truly separate itself. Next up their own discreet card? Maybe?
"Legacy Crap bogging down Windows"
Wonder how the legacy crap is bogging the windows. Windows got it's strength from the software compatibility not gated bs like Apple. At Apple utopia, all is locked down only passed when Apple almighty says so. Do you even realize how big 32bit axe would be for the Applications ? Win10 32bit is already being phased out and so are GPU drivers, the Application support is very important for an OS to be very robust and non user restrictive. Did Linux got bogged down by all Legacy crap ?
M1 won't do anything, Apple users will buy their BGA riddled walled garden Macs no matter what, and Windows machines will be sold as they are, people need GPUs and OS supporting their Software requirements, until Apple catches up to AMD or Nvidia that day is not going to come.
Yes, it's very fast in single threaded workloads, no it's not what Apple claims overall.
No, you still don't want to game on Apple hardware.
www.anandtech.com/show/16252/mac-mini-apple-m1-tested/
The thing is, this design is likely to scale extremely well for servers and workstations, as the clock speeds they are reaching are the same as the ones hit by current top-end multi-core server chips, just at much lower power. They'd obviously need to tweak the architecture in various ways and find a way to couple together more than 4+4 cores efficiently without introducing bottlenecks or massive latency, but ... given what they've already done, that should be doable. Whatever silicon Apple makes for the next Mac Pro, it's looking like it'll be extremely impressive.I would really, really like to see what RotTR performance would look like if it was compiled for this architecture rather than run through a translation layer. Even if gaming performance is lacklustre overall, that is damn impressive.
Personally I could not care less, by their own design/philosophy I dont have anything to do with Apple and probably never will.
They could make a low power mobile chip that is as fast as an RTX3090 and it would not affect me in the slightest, I have nothing to do with Apple.
www.anandtech.com/show/16252/mac-mini-apple-m1-tested/2
This is the version 1 of a new/unsupported arch in some instances BEATING the next gen best. For a first attempt it's quite insane how fast this is.
Edit: I got confused that was for a 128KB cache, for a 192KB one that is 6 times larger it's basically the same explanation, they can do it because of the 16KB page.
No other company in the world has a complete in-house platform that can be tuned to this degree for optimal performance.
It gives them what one could almost call an unfair advantage.
However, we still have to seem them scale this, as right now we're looking at an iPad with a keyboard, on steroids.
This is not going to be a hardware solution that will be competitive in all aspects and so far we're barely scratching the surface, as all the benchmarks so far are somewhat limited.
Single core performance is no longer as important as it once was and judging by the benchmarks, it's running into problems keeping up once we go beyond the performance cores.
Not saying Apple did a bad job, I'm just not buying into all the hype, as Apple clearly oversold this when it was announced.
Yes, it's going to be good enough of a work computer for a lot of people, but it's clearly not for everyone.
As for making wider cores: yes, they likely will, but this is actually an area where x86 is a real problem. To quote AT:So they can, but they would need to take a significant efficiency penalty, or find some way to mitigate this.
modern processors are just so much more complex than just the instruction set that in the end it do not really matter. at least for pure performance. for low power, x86 still seem to have a bit higher overhead...
But the thing is ARM is getting more powerful by using more transitors and more power. It's not the 4 watt cpu in your phone that is doing that...
I am not an apple fan, but i am glad they do something powerful because we need competitions. AMD is starting to compete again and there is a lot more performance gain each year than when Intel and Nvidia had 0 competition.
Good stuff indeed, good stuff...
The closest thing to compare that to in the PC space is game consoles vs PC gaming; Last Gen XBox hardware is pitiful by modern standards but if you took the equivalent Radeon R7 260 DDR3 that the XBox One has in it and tried to run the PC version of an Xbox One game on that R7 260, you'd be greeted by a low-res, low-quality slideshow.
Meanwhile the same hardware in the XBone is getting 1080p30 with improved graphics quality. That's the power of optimising and compiling for a single-purpose, single-spec platform.
But there is another company which proves my point more than anyone else, ARM themselves, they're also close to extracting similar performance out of cores that are even smaller and consume way less power and area than Apple's. I'll maintain my opinion that Apple's approach is the wrong one long term.
What interested me in is its promising performance (if software transitions well) coupled with impressive looking battery life (guess it needs to be tested).
While I need my GPU to play ray-traced games, that's on my desktop; my laptop could be something else and now I am motivated to give it a shot.Maybe one day they scale up M1 to something that can compete with a 5950X?
Not sure if it is technically possible with their design, but ARM definitely is picking up some momentum lately.
Depending on what Apple's plan is, they're obviously going to have to scale the performance upwards.
How they'll do this, I guess we're going to have to wait and see.